Регулярные выражения для самых маленьких
Содержание:
- Нечёткие регулярные выражения
- 4.1 Positive Lookahead
- Литература
- 2.8.1 Caret
- Скобочные группы (?:…) и перечисления |
- Строковые методы, поиск и замена
- Группирующие скобки (…) и match-объекты в питоне
- Короткая запись
- Поиск совпадений: метод exec
- Модификаторы¶
- 2.5 Character Group
- Проверка наличия совпадения
- Примечания
- Замена текста REGEXP_REPLACE
- 2 Практический раздел. Ссылки
- 2.4 Braces
- Lookaround
- Реализации
- Literal Characters
- Grouping and Capturing
- В теории формальных языков
- Заключение
Нечёткие регулярные выражения
В некоторых случаях регулярные выражения удобно применить для анализа текстовых фрагментов на естественном языке, то есть написанных людьми, и, возможно, содержащих опечатки либо нестандартные варианты употреблений слов. Например, если проводить опрос (допустим, на веб-сайте) «какой станцией метро вы пользуетесь», может оказаться, что «Невский проспект» посетители могут указать как:
- Невский
- Невск. просп.
- Нев. проспект
- наб. Канала Грибоедова («Канал Грибоедова» — это название второго выхода ст. м. Невский проспект)
Здесь обычные регулярные выражения неприменимы, в первую очередь из-за того, что входящие в образцы слова могут совпадать не очень точно (нечётко), но, тем не менее, было бы удобно описывать регулярными выражениями структурные зависимости между элементами образца,
например, в нашем случае, указать, что совпадение может быть с образцом «Невский проспект» ИЛИ «Канал Грибоедова», притом «проспект» может быть сокращено до «пр» или отсутствовать, а перед «Канал» может находиться сокращение «наб.»
Эта задача сродни полнотекстовому поиску, отличаясь в том, что здесь короткий фрагмент должен сравниваться с набором образцов, а при полнотекстовом поиске, наоборот, образец обычно один, в то время как фрагмент текста очень большой, или задаче разрешения лексической многозначности, которая, однако, не позволяет задать структурирующие отношения между элементами образца.
Существует небольшое количество библиотек, реализующих механизм регулярных выражений с возможностью нечёткого сравнения:
- TRE — бесплатная библиотека на С, использующая синтаксис регулярных выражений, похожий на POSIX (стабильный проект);
- FREJ — open-source библиотека на Java, использующая Lisp-образный синтаксис и лишённая многих возможностей обычных регулярных выражений, но сосредоточенная на различного рода автоматических заменах фрагментов текста (бета-версия).
4.1 Positive Lookahead
The positive lookahead asserts that the first part of the expression must befollowed by the lookahead expression. The returned match only contains the text that is matched by the first part of the expression. To define a positivelookahead, parentheses are used. Within those parentheses, a question mark with equal sign is used like this: . Lookahead expression is written after the equal sign inside parentheses. For example, the regular expression means: optionally match lowercase letter or uppercase letter , followed by letter , followed by letter . In parentheses we define positive lookahead which tells regular expression engine to match or which are followed by the word .
(T|t)he(?=\sfat) => The fat cat sat on the mat.
Литература
- Фридл, Дж. Регулярные выражения = Mastering Regular Expressions. — СПб.: «Питер», 2001. — 352 с. — (Библиотека программиста). — ISBN 5-318-00056-8.
- Смит, Билл. Методы и алгоритмы вычислений на строках (regexp) = Computing Patterns in Strings. — М.: «Вильямс», 2006. — 496 с. — ISBN 0-201-39839-7.
- Форта, Бен. Освой самостоятельно регулярные выражения. 10 минут на урок = Sams Teach Yourself Regular Expressions in 10 Minutes. — М.: «Вильямс», 2005. — 184 с. — ISBN 5-8459-0713-6.
- Ян Гойвертс, Стивен Левитан. Регулярные выражения. Сборник рецептов = Regular Expressions: Cookbook. — СПб.: «Символ-Плюс», 2010. — 608 с. — ISBN 978-5-93286-181-3.
- Мельников С. В. Perl для профессиональных программистов. Регулярные выражения. — М.: «Бином», 2007. — 190 с. — (Основы информационных технологий). — ISBN 978-5-94774-797-3.
- Майкл Фицджеральд. Регулярные выражения. Основы. — М.: «Вильямс», 2015. — 144 с. — ISBN 978-5-8459-1953-3.
2.8.1 Caret
Caret symbol is used to check if matching character is the first characterof the input string. If we apply the following regular expression (if a isthe starting symbol) to input string it matches . But if we apply regular expression on above input string it does not match anything. Because in input string is not the starting symbol. Let’s take a look at another regular expression which means: uppercase character or lowercase character is the start symbol of the input string, followed bylowercase character , followed by lowercase character .
(T|t)he => The car is parked in the garage.
^(T|t)he => The car is parked in the garage.
Скобочные группы (?:…) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора , который записывается с помощью символа . Так, некоторая строка подходит к регулярному выражению тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений или . Например, отдельные овощи в тексте можно искать при помощи шаблона .
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами или . Например, . Каждый отдельный символ можно задать как , и можно весь шаблон записать так:
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка . Можно писать круглые скобки и без значков , однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее. Об этом будет написано ниже. Итак, если — шаблон, то — эквивалентный ему шаблон. Разница только в том, что теперь к можно применять квантификаторы, указывая, сколько именно раз должна повториться группа. Например, шаблон для поиска MAC-адреса, можно записать так:
Скобки плюс перечисления
Также скобки позволяют локализовать часть шаблона, внутри которого происходит перечисление. Например, шаблон соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом .
Ещё примеры
| Шаблон | Применяем к тексту |
|---|---|
| Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. | |
| Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. | |
| +7-926-123-12-12, 8-926-123-12-12 | |
| Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. | |
| Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Группирующие скобки (…) и match-объекты в питоне
Match-объекты
| Метод | Описание | Пример |
|---|---|---|
| , | Подстрока, соответствующая шаблону | |
| Индекс в исходной строке, начиная с которого идёт найденная подстрока | ||
| Индекс в исходной строке, который следует сразу за найденной подстрока |
Группирующие скобки
Если в шаблоне регулярного выражения встречаются скобки без , то они становятся группирующими. В match-объекте, который возвращают , и , по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует , а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок , то вывод был бы таким:
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
Группы и
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки .
Группы и
Если в шаблоне нет группирующих скобок, то работает очень похожим образом на . А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
Короткая запись
Допустим, мы хотим найти наличие цифр от 1 до 8. Мы могли бы использовать для поиска следующий диапазон: , но есть вариант получше:
Вы можете комбинировать набор символов вместе с другими символами:
В регулярном выражении, приведенном выше, мы ищем цифры 1, 2, 3, 4 или 9.
Мы также можем объединить несколько наборов. В следующем регулярном выражении мы ищем 1, 2, 3, 4, 5, a, b, c, d, e, f, x:
Использование наборов символов иногда может привести к странному поведению. Например, вы можете использовать диапазон и обнаружить, что ему соответствует символ . Это связано с таблицами символов, которые использует система. В большинстве систем есть таблица символов, в которой сначала идут все строчные буквы, а затем все заглавные (например, ). Однако некоторые системы чередуют строчные и прописные буквы (например, ). Если вы столкнулись с каким-то странным поведением и при этом используете диапазоны, то это первое, что нужно проверить.
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Модификаторы¶
Синтаксис для одного модификатора: чтобы включить, и чтобы выключить. Для большого числа модификаторов используется синтаксис: .
Можно использовать внутри регулярного выражения. Это может быть особенно удобно, поскольку оно имеет локальную область видимости. Оно влияет только на ту часть регулярного выражения, которая следует за оператором .
И если оно находится внутри подвыражения, оно будет влиять только на это подвыражение, а именно на ту часть подвыражения, которая следует за оператором. Таким образом, в это влияет только на подвыражение , поэтому оно будет соответствовать , но не .
2.5 Character Group
Character group is a group of sub-patterns that is written inside Parentheses . As we discussed before that in regular expression if we put a quantifier after a character then it will repeat the preceding character. But if we put quantifier after a character group then it repeats the whole character group. For example, the regular expression matches zero or more repetitions of the character . We can also use the alternation meta character inside character group. For example, the regular expression means: lowercase character , or , followed by character , followed by character .
(c|g|p)ar => The car is parked in the garage.
Проверка наличия совпадения
Регулярные выражения используются для описания текста, который требуется найти в строке (и возможно, подвергнуть дополнительной обработке). Давайте вернемся к примеру, который приводился ранее в этом блоге:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Aaron,Jeff';
Допустим, мы хотим определить на программном уровне, содержит ли строка список имен, разделенных запятыми. Для этого мы воспользуемся функцией , обнаруживающей совпадения шаблона в строке:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
BEGIN
--Поиск по шаблону
comma_delimited := REGEXP_LIKE(names,'^(*,)+(*){1}$');
--Вывод результата
DBMS_OUTPUT.PUT_LINE(
CASE comma_delimited
WHEN true THEN 'Обнаружен список с разделителями!'
ELSE 'Совпадение отсутствует.'
END);
END;
Результат:
Обнаружен список с разделителями
Чтобы разобраться в происходящем, необходимо начать с выражения, описывающего искомый текст. Общий синтаксис функции выглядит так:
REGEXP_LIKE (исходная_строка, шаблон )
Здесь — символьная строка, в которой ищутся совпадения; шаблон — регулярное выражение, совпадения которого ищутся в исходной_строке; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Если функция находит совпадение шаблона в , она возвращает логическое значение ; в противном случае возвращается .
Процесс построения регулярного выражения выглядел примерно так:
- Каждый элемент списка имен может состоять только из букв и пробелов. Квадратные скобки определяют набор символов, которые могут входить в совпадение. Диапазон a–z описывает все буквы нижнего регистра, а диапазон A–Z — все буквы верхнего регистра. Пробел находится между двумя компонентами выражения. Таким образом, этот шаблон описывает один любой символ нижнего или верхнего регистра или пробел.
- * Звездочка является квантификатором — служебным символом, который указывает, что каждый элемент списка содержит ноль или более повторений совпадения, описанного шаблоном в квадратных скобках.
- *, Каждый элемент списка должен завершаться запятой. Последний элемент является исключением, но пока мы не будем обращать внимания на эту подробность.
- *,) Круглые скобки определяют подвыражение, которое описывает некоторое количество символов, завершаемых запятой. Мы определяем это подвыражение, потому что оно должно повторяться при поиске.
- ]*,)+ Знак + — еще один квантификатор, применяемый к предшествующему элементу (то есть к подвыражению в круглых скобках). В отличие от * знак + означает «одно или более повторений». Список, разделенный запятыми, состоит из одного или нескольких повторений подвыражения.
- ( В шаблон добавляется еще одно подвыражение: (*). Оно почти совпадает с первым, но не содержит запятой. Последний элемент списка не завершается запятой.
- Мы добавляем квантификатор {1}, чтобы разрешить вхождение ровно одного элемента списка без завершающей запятой.
- ^ Наконец, метасимволы ^ и привязывают потенциальное совпадение к началу и концу целевой строки. Это означает, что совпадением шаблона может быть только вся строка вместо некоторого подмножества ее символов.
Функция анализирует список имен и проверяет, соответствует ли он шаблону. Эта функция оптимизирована для простого обнаружения совпадения шаблона в строке, но другие функции способны на большее!
Примечания
Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции. Синтаксический анализ. — Мир. — М., 1978. — Т. 2.
Во многих книгах используются символы ∪, + или ∨ вместо |.
Vladimir Komendantsky. Matching Problem for Regular Expressions with Variables // Trends in Functional Programming : 13th International Symposium, TFP 2012, St Andrews, UK, June 12-14, 2012, Revised Selected Papers. — Springer, 2013. — P. 149–150. — ISBN 9783642404474.
Для использования последовательностей букв необходимо установить правильную кодовую страницу, в которой эти последовательности будут идти в порядке от и до указанных символов.
Для русского языка это Windows-1251, ISO 8859-5 и Юникод, так как в DOS-855, DOS-866 и KOI8-R русские буквы не идут одной целой группой или не упорядочены по алфавиту
Отдельное внимание следует уделять буквам с диакритическими знаками, наподобие русских Ё/ё, которые, как правило, разбросаны вне основных диапазонов символов.
Существует эквивалентное обозначение ]
Существует эквивалентное обозначение ]
Замена текста REGEXP_REPLACE
Поиск и замена — одна из лучших областей применения регулярных выражений. Текст замены может включать ссылки на части исходного выражения (называемые обратными ссылками), открывающие чрезвычайно мощные возможности при работе с текстом. Допустим, имеется список имен, разделенный запятыми, и его содержимое необходимо вывести по два имени в строке. Одно из решений заключается в том, чтобы заменить каждую вторую запятую символом новой строки. Сделать это при помощи стандартной функции нелегко, но с функцией задача решается просто. Общий синтаксис ее вызова:
REGEXP_REPLACE (исходная_строка, шаблон ]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Пример:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
extracted_name VARCHAR2(60);
name_counter NUMBER;
BEGIN
-- Искать совпадение шаблона
comma_delimited := REGEXP_LIKE(names,'^(*,)+(*){1}$', 'i');
-- Продолжать, только если мы действительно
-- работаем со списком, разделенным запятыми.
IF comma_delimited THEN
names := REGEXP_REPLACE(
names,
'(*),(*),',
'\1,\2' || chr(10) );
END IF;
DBMS_OUTPUT.PUT_LINE(names);
END;
Результат выглядит так:
Anna,Matt Joe,Nathan Andrew,Jeff Aaron
При вызове функции передаются три аргумента:
- names — исходная строка;
- ‘(*),(*),’ — выражение, описывающее заменяемый текст (см. ниже);
- ‘\1,\2 ‘ || chr(10) — текст замены. \1 и \2 — обратные ссылки, заложенные в основу нашего решения. Подробные объяснения также приводятся ниже.
Выражение, описывающее искомый текст, состоит из двух подвыражений в круглых скобках и двух запятых.
- Совпадение должно начинаться с имени.
- За именем должна следовать запятая.
- Затем идет другое имя.
- И снова одна запятая.
Наша цель — заменить каждую вторую запятую символом новой строки. Вот почему выражение написано так, чтобы оно совпадало с двумя именами и двумя запятыми. Также запятые не напрасно выведены за пределы подвыражений.
Первое совпадение для нашего выражения, которое будет найдено при вызове , выглядит так:
Anna,Matt,
Два подвыражения соответствуют именам «» и «». В основе нашего решения лежит возможность ссылаться на текст, совпавший с заданным подвыражением, через обратную ссылку. Обратные ссылки и в тексте замены ссылаются на текст, совпавший с первым и вторым подвыражением. Вот что происходит:
'\1,\2' || chr(10) -- Текст замены
'Anna,\2' || chr(10) -- Подстановка текста, совпавшего
-- с первым подвыражением
'Anna,Matt' || chr(10) -- Подстановка текста, совпавшего
-- со вторым подвыражением
Вероятно, вы уже видите, какие мощные инструменты оказались в вашем распоряжении. Запятые из исходного текста попросту не используются. Мы берем текст, совпавший с двумя подвыражениями (имена «Anna» и «Matt»), и вставляем их в новую строку с одной запятой и одним символом новой строки.
Но и это еще не все! Текст замены легко изменить так, чтобы вместо запятой в нем использовался символ табуляции (ASCII-код 9):
names := REGEXP_REPLACE( names, '(*),(*),', '\1' || chr(9) || '\2' || chr(10) );
Теперь результаты выводятся в два аккуратных столбца:
Anna Matt Joe Nathan Andrew Jeff Aaron
Поиск и замена с использованием регулярных выражений — замечательная штука. Это мощный и элегантный механизм, с помощью которого можно сделать очень многое.
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:

Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:

Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
2.4 Braces
In regular expression braces that are also called quantifiers are used tospecify the number of times that a character or a group of characters can berepeated. For example, the regular expression means: Match at least 2 digits but not more than 3 ( characters in the range of 0 to 9).
{2,3} => The number was 9.9997 but we rounded it off to 10.0.
We can leave out the second number. For example, the regular expression means: Match 2 or more digits. If we also remove the comma theregular expression means: Match exactly 3 digits.
{2,} => The number was 9.9997 but we rounded it off to 10.0.
{3} => The number was 9.9997 but we rounded it off to 10.0.
Lookaround
Lookaround is a special kind of group. The tokens inside the group are matched normally, but then the regex engine makes the group give up its match and keeps only the result. Lookaround matches a position, just like anchors. It does not expand the regex match.
q(?=u) matches the q in question, but not in Iraq. This is positive lookahead. The u is not part of the overall regex match. The lookahead matches at each position in the string before a u.
q(?!u) matches q in Iraq but not in question. This is negative lookahead. The tokens inside the lookahead are attempted, their match is discarded, and the result is inverted.
To look backwards, use lookbehind. The positive lookbehind (?<=a)b matches the b in abc. The negative lookbehind (?<!a)b fails to match abc.
You can use a full-fledged regular expression inside lookahead. Most applications only allow fixed-length expressions in lookbehind.
Реализации
- NFA (англ. nondeterministic finite-state automata — недетерминированные конечные автоматы) используют жадный алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA, выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
- DFA (англ. deterministic finite-state automata — детерминированные конечные автоматы) работают линейно по времени, поскольку не используют откаты и никогда не проверяют какую-либо часть текста дважды. Они могут гарантированно найти самую длинную строку из возможных. DFA содержит только конечное состояние, следовательно, не обрабатывает обратных ссылок, а также не поддерживает конструкций с явным расширением, то есть не способен обработать и подвыражения. DFA используется, например, в lex и egrep.
Literal Characters
The most basic regular expression consists of a single literal character, such as a. It matches the first occurrence of that character in the string. If the string is Jack is a boy, it matches the a after the J.
This regex can match the second a too. It only does so when you tell the regex engine to start searching through the string after the first match. In a text editor, you can do so by using its “Find Next” or “Search Forward” function. In a programming language, there is usually a separate function that you can call to continue searching through the string after the previous match.
Twelve characters have special meanings in regular expressions: the backslash \, the caret ^, the dollar sign $, the period or dot ., the vertical bar or pipe symbol |, the question mark ?, the asterisk or star *, the plus sign +, the opening parenthesis (, the closing parenthesis ), the opening square bracket , and the opening curly brace {. These special characters are often called “metacharacters”. Most of them are errors when used alone.
If you want to use any of these characters as a literal in a regex, you need to escape them with a backslash. If you want to match 1+1=2, the correct regex is 1\+1=2. Otherwise, the plus sign has a special meaning.
Grouping and Capturing
Place parentheses around multiple tokens to group them together. You can then apply a quantifier to the group. E.g. Set(Value)? matches Set or SetValue.
Parentheses create a capturing group. The above example has one group. After the match, group number one contains nothing if Set was matched. It contains Value if SetValue was matched. How to access the group’s contents depends on the software or programming language you’re using. Group zero always contains the entire regex match.
Use the special syntax Set(?:Value)? to group tokens without creating a capturing group. This is more efficient if you don’t plan to use the group’s contents. Do not confuse the question mark in the non-capturing group syntax with the quantifier.
В теории формальных языков
Основная статья: Регулярный язык
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно.
Определены следующие константы:
- (пустое множество) ∅;
- (пустая строка) ε обозначает строку, не содержащую ни одного символа; эквивалентно «»;
- (символьный литерал) «a», где a — символ используемого алфавита;
- (множество) из символов, либо из других множеств;
и следующие операции:
- (сцепление, конкатенация) RS обозначает множество {αβ | α ∈ R & β ∈ S}, например: {«boy», «girl»}{«friend», «cott»} = {«boyfriend», «girlfriend», «boycott», «girlcott»};
- (дизъюнкция, чередование) R|S обозначает объединение R и S, например: {«ab», «c»}|{«ab», «d», «ef»} = {«ab», «c», «d», «ef»};
- (замыкание Клини, звезда Клини) R* обозначает минимальное надмножество множества R, которое содержит ε и замкнуто относительно конкатенации (это есть множество всех строк, полученных конкатенацией нуля или более строк из R, например: {«Run», «Forrest»}* = {ε, «Run», «Forrest», «RunRun», «RunForrest», «ForrestRun», «ForrestForrest», «RunRunRun», «RunRunForrest», «RunForrestRun», …})[источник не указан 562 дня].
Регулярные выражения, входящие в современные языки программирования (в частности, PCRE), имеют больше возможностей, чем то, что называется регулярными выражениями в теории формальных языков; в частности, в них есть нумерованные обратные ссылки. Это позволяет им разбирать строки, описываемые не только регулярными грамматиками, но и более сложными, в частности, контекстно-свободными грамматиками.
Заключение
В приведенном выше примере нам удалось создать следующий CSV-файл, имея на старте лишь текстовый файл:
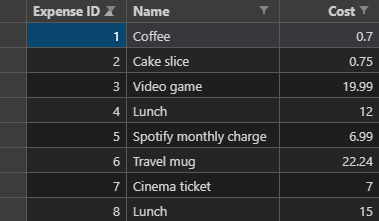
Итоговый CSV
Как я уже говорил в начале, это упражнение простое, но дает хорошую практику регулярных выражений.
Напоследок, я хотел бы посоветовать вам regex101.com, этот ресурс отлично подходит для написания и тестов паттернов, а также чит-лист регулярных выражений Python на Debuggex.
- Когда ИИ или машинное обучение неуместны
- 4 шага к совершенству: правила для идеальных функций
- 25 наборов аудиоданных для исследований
Читайте нас в Telegram, VK и
Перевод статьи José Fernando Costa: Using RegEx to extract expenses information from a text file