Основы linux от основателя gentoo. часть 2 (1/5): регулярные выражения
Содержание:
- grep примеры использования
- Основы регулярных выражений
- Grep OR Operator
- Приведем примеры
- Регулярные выражения Linux
- Other options
- файлами с Работа
- 11. Параметры для использования с командой Tree в Linux
- Использование регулярных выражений
- Примеры использования
- File and directory selection
- Команда sed в Linux
- Regular expressions
- EXAMPLE top
- Основная информация о Find
- 2. Примеры использования команды Grep
grep примеры использования
В принципе для работы grep не обязательно указывать даже файл или директорию, но это крайне желательно, если Вы хотите найти всё быстрее и точнее. Например:
Найдет файлы с упоминанием меня любимого, если таковые есть. Точнее не файлы, а строки с упоминанием указанного слова, т.е в данном случае sonikelf. Здесь стоит упомянуть, что строкой grep считает все символы, находящиеся между двумя символами новой строки.
| grep sonikelf file.txt | поиск sonikelf в файле file.txt, с выводом полностью совпавшей строкой |
| grep -o sonikelf file.txt | поиск sonikelf в файле file.txt и вывод только совпавшего куска строки |
| grep -i sonikelf file.txt | игнорирование регистра при поиске |
| grep -bn sonikelf file.txt | показать строку (-n) и столбец (-b), где был найден sonikelf |
| grep -v sonikelf file.txt | инверсия поиска (найдет все строки, которые не совпадают с шаблоном sonikelf) |
| grep -A 3 sonikelf file.txt | вывод дополнительных трех строк, после совпавшей |
| grep -B 3 sonikelf file.txt | вывод дополнительных трех строк, перед совпавшей |
| grep -C 3 sonikelf file.txt | вывод три дополнительные строки перед и после совпавшей |
| grep -r sonikelf $HOME | рекурсивный поиск по директории $HOME и всем вложенным |
| grep -c sonikelf file.txt | подсчет совпадений |
| grep -L sonikelf *.txt | вывести список txt-файлов, которые не содержат sonikelf |
| grep -l sonikelf *.txt | вывести список txt-файлов, которые содержат sonikelf |
| grep -w sonikelf file.txt | совпадение только с полным словом sonikelf |
| grep -f sonikelfs.txt file.txt | поиск по нескольким sonikelf из файла sonikelfs.txt, шаблоны разделяются новой строкой |
| grep -I sonikelf file.txt | игнорирование бинарных файлов |
| grep -v -f file2 file1 > file3 | вывод строк, которые есть в file1 и нет в file2 |
| grep -in -e ‘python’ `find -type f` | рекурсивный поиск файлов, содержащих слово python с выводом номера строки и совпадений |
| grep -inc -e ‘test’ `find -type f` | grep -v :0 | рекурсивный поиск файлов, содержащих слово python с выводом количества совпадений |
| grep . *.py | вывод содержимого всех py-файлов, предваряя каждую строку именем файла |
| grep «Http404» apps/**/*.py | рекурсивный поиск упоминаний Http404 в директории apps в py-файлах |
Основы регулярных выражений
В общем виде синтаксис команды ‘grep’ выглядит следующим образом:
Изучим некоторые специальные символы, известные как метасимволы. Они помогают создавать более сложные поисковые выражения:
| . | будет соответствовать любому символу; |
| будет соответствовать диапазону символов; | |
| будет соответствовать всем символам, кроме указанных в фигурных скобках; | |
| * | будет соответствовать любому количеству символов, предшествующих звездочке, в том числе нулю; |
| + | будет соответствовать одному или нескольким из стоящих перед ним выражений; |
| ? | будет соответствовать нулю или одному из стоящих перед ним выражений; |
| {n} | будет соответствовать ‘n’ повторениям предшествующих выражений; |
| {n,} | будет соответствовать не менее ‘n’ повторениям предшествующих выражений; |
| {n m} | будет соответствовать не менее ‘n’ и не более ‘m’ повторениям предшествующих выражений; |
| {,m} | будет соответствовать не более или равному ‘m’ повторениям предшествующих выражений; |
| является escape-символом (символом экранирования), используемым, когда нужно включить один из метасимволов. |
Grep OR Operator
Use any one of the following 4 methods for grep OR. I prefer method number 3 mentioned below for grep OR operator.
1. Grep OR Using \|
If you use the grep command without any option, you need to use \| to separate multiple patterns for the or condition.
grep 'pattern1\|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Without the back slash in front of the pipe, the following will not work.
$ grep 'Tech\|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
2. Grep OR Using -E
grep -E option is for extended regexp. If you use the grep command with -E option, you just need to use | to separate multiple patterns for the or condition.
grep -E 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ grep -E 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
3. Grep OR Using egrep
egrep is exactly same as ‘grep -E’. So, use egrep (without any option) and separate multiple patterns for the or condition.
egrep 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ egrep 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
4. Grep OR Using grep -e
Using grep -e option you can pass only one parameter. Use multiple -e option in a single command to use multiple patterns for the or condition.
grep -e pattern1 -e pattern2 filename
For example, grep either Tech or Sales from the employee.txt file. Use multiple -e option with grep for the multiple OR patterns.
$ grep -e Tech -e Sales employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
Приведем примеры
. (точка)
Используется для соответствия любому символу, который встречается в поисковом запросе. Например, можем использовать точку как:
Это регулярное выражение означает, что мы ищем слово, которое начинается с ‘d’, оканчивается на ‘g’ и может содержать один любой символ в середине файла с именем ‘file1’. Точно так же мы можем использовать символ точки любое количество раз для нашего шаблона поиска, например:
Этот поисковый термин будет искать слово, которое начинается с ‘T’, оканчивается на ‘h’ и может содержать любые шесть символов в середине.
Квадратные скобки используются для определения диапазона символов. Например, когда нужно искать один из перечисленных символов, а не любой символ, как в случае с точкой:
Здесь мы ищем слово, которое начинается с ‘N’, оканчивается на ‘n’ и может иметь только ‘o’, ‘e’ или ‘n’ в середине. В квадратных скобках можно использовать любое количество символов. Мы также можем определить диапазоны, такие как ‘a-e’ или ‘1-18’, как список совпадающих символов в квадратных скобках.
Это похоже на оператор отрицания для регулярных выражений. Использование означает, что поиск будет включать в себя все символы, кроме тех, которые указаны в квадратных скобках. Например:
Это означает, что у нас могут быть все слова, которые начинаются с ‘St’, оканчиваются буквой ‘d’ и не содержат цифр от 1 до 9.
До сих пор мы использовали примеры регулярных выражений, которые ищут только один символ. Но что делать в иных случаях? Допустим, если требуется найти все слова, которые начинаются или оканчиваются символом или могут содержать любое количество символов в середине. С этой задачей справляются так называемые метасимволы-квантификаторы, определяющие сколько раз может встречаться предшествующее выражение: + * & ?
{n}, {n m}, {n, } или { ,m} также являются примерами других квантификаторов, которые мы можем использовать в терминах регулярных выражений.
* (звездочка)
На следующем примере показано любое количество вхождений буквы ‘k’, включая их отсутствие:
Это означает, что у нас может быть совпадение с ‘lake’ или ‘la’ или ‘lakkkkk’.
+
Следующий шаблон требует, чтобы хотя бы одно вхождение буквы ‘k’ в строке совпадало:
Здесь буква ‘k’ должна появляться хотя бы один раз, поэтому наши результаты могут быть ‘lake’ или ‘lakkkkk’, но не ‘la’.
?
В следующем шаблоне результатом будет строка bb или bab:
С заданным квантификатором ‘?’ мы можем иметь одно вхождение символа или ни одного.
Важное примечание! Предположим, у нас есть регулярное выражение:
И мы получаем результаты ‘Small’, ‘Silly’, и ещё ‘Susan is a little to play ball’. Но почему мы получили ‘Susan is a little to play ball’, ведь мы искали только слова, а не полное предложение?
Все дело в том, что это предложение удовлетворяет нашим критериям поиска: оно начинается с буквы ‘S’, имеет любое количество символов в середине и заканчивается буквой ‘l’. Итак, что мы можем сделать, чтобы исправить наше регулярное выражение, чтобы в качестве выходных данных мы получали только слова вместо целых предложений.
Для этого в регулярное выражение нужно добавить квантификатор ‘?’:
или символ экранирования
Символ » используется, когда необходимо включить символ, который является метасимволом или имеет специальное значение для регулярного выражения. Например, требуется найти все слова, заканчивающиеся точкой. Для этого можем использовать выражение:
Оно будет искать и сопоставлять все слова, которые заканчиваются точкой.
Итак, вы получили общее представление о том, как работают регулярные выражения. Практикуйтесь как можно больше, создавайте регулярные выражения и старайтесь включать их в свою работу как можно чаще. Проверять правильность использования своих регулярных выражений на конкретном примере можно на специальном сайте.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
файлами с Работа
Команда grep может обрабатывать количество любое файлов
одновременно. Создадим три 123:
файла.txt: alice.txt: ast.1234:
txt Алиса очень Символ астериска
красивая 5678 девочка, обозначается (*)
89*0 у нее такая ****** длинная.
звездочкой коса!
И дадим команду:
grep '*' txt.123 ast.txt alice.txt txt.123:89*0 ast.txt:обозначается (*). alice.нее:у txt такая ******
В выводе перечислены файлы, и каком, в указано из них какая
строка содержит астериска символ. ОБРАЗЕЦ (*) пришлось взять в
кавычки, командный чтобы интерпретатор понял, что имеется в символ
виду, а не условный знак. Попробуйте без увидите, кавычек —
ничего не получится.
Команда grep ограничена не вовсе одним выражением в качестве
ОБРАЗЦА, задавать можно хоть целые фразы. Только их заключать нужно
в кавычки (одинарные или двойные):
ная 'grep ко' 123.txt ast.txt txt.alice alice.txt:длинная коса!
поиска Возможности при помощи команды grep быть могут
значительно расширены применением групповых Например. символов, уже
упоминавшийся астериск (звездочка) для используется представления
любого символа или символов группы, если речь идет о тексте, и
файла любого или группы файлов, если идет речь о директории.
Создадим директорию /example, в поместим которую файлы наших
примеров: 123.ast, txt.txt, alice.txt и дадим grep:
команду '*' example/* example/123.txt:89*0 alice/example.txt:у нее такая ****** example/txt.ast:обозначается (*)
То есть мы приказали просмотреть файлы все директории /example.
Таким способом обследовать можно такие огромные директории как
/dev, /usr, и любые другие.
11. Параметры для использования с командой Tree в Linux
Параметры для использования с деревом
Далее Solvetic объяснит доступные параметры для использования с Tree:
-a: распечатать все файлы, помните, что по умолчанию дерево не печатает скрытые файлы.
-d: список только каталогов.
-l: продолжить символические ссылки, если они указывают на каталоги, притворяясь каталогами.
-f: вывести префикс полного пути к объектам.
-x: остается только в текущей файловой системе.
-L Level: позволяет определить максимальную глубину просмотра дерева каталогов в результате.
-R: Действовать рекурсивно, пересекая дерево в каталогах каждого уровня, и в каждом из них оно будет выполняться. дерево снова, добавив `-o 00Tree.html ‘.
-P шаблон: список только файлов, которые соответствуют шаблону подстановки.
-I шаблон: не перечислять файлы, которые соответствуют шаблону подстановки.
—matchdirs. Этот параметр указывает шаблон соответствия, который позволяет применять шаблон только к именам каталогов.
—prune: этот параметр удаляет пустые каталоги из выходных данных.
—noreport: пропускает печать файла и отчета каталога в конце списка выполненного дерева.
Общие параметры дерева
Это общие параметры, доступные для дерева, но у нас также есть эксклюзивные параметры для файлов, это:
-q: печатать непечатаемые символы в именах файлов.
-N: печать непечатных символов.
-Q: его функция заключается в назначении имен файлов в двойных кавычках.
-p: вывести тип файла и разрешения для каждого файла в каталоге.
-u: распечатать имя пользователя или UID файла.
-s: вывести размер каждого файла в байтах, а также его имя.
-g Распечатать имя группы или GID файла.
-h: его функция — распечатывать размер каждого файла разборчиво для пользователя.
—du: Он действует в каждом каталоге, генерируя отчет о его размере, включая размеры всех его файлов и подкаталогов.
—si: он использует степени 1000 (единицы СИ) для отображения размера файла.
-D: Распечатать дату последнего изменения файлов.
-F: Ваша задача — добавить `/ ‘для каталогов, a` =’ для файлов сокетов, a` * ‘для исполняемых файлов, `>’ для дверей (Solaris) и a` | ‘ для FIFO.
—inodes: вывести номер инода файла или каталога.
- —device: вывести номер устройства, к которому относится файл или каталог в результате.
- -v: Сортировать вывод по версии.
-U: не упорядочивает результаты.
-r: сортировать вывод в обратном порядке.
-t: сортировать результаты по времени последней модификации, а не по алфавиту.
-S: активировать линейную графику CP437
-n: отключает раскраску результата.
-C: активирует раскраску.
-X: активировать вывод XML.
-J: активировать вывод JSON.
-H baseHREF: активирует вывод HTML, включая ссылки HTTP.
—help: Помощь дерева доступа.
—version: показывает используемую версию команды Tree.
С помощью этих двух команд стало возможным гораздо более полное администрирование каждой задачи, выполняемой над файлами в Linux, дополняющей задачи поиска или управления этими файлами и доступа к интегральным результатам по мере необходимости.
Использование регулярных выражений
Истинная сила grep заключается в возможности применения для поиска соответствий регулярным выражениям. В регулярных выражениях в аргументе ШАБЛОН используются специальные символы для охвата более широкого диапазона строк. Рассмотрим простой пример.
Допустим, требуется найти каждое появление фразы, похожей на «our products», которая всегда должна начинаться с «our» и заканчиваться на «products». Для этого нужно указать такой шаблон: «our.*products».
В регулярных выражениях точка («.») интерпретируется как маска для одного символа. Она означает «подойдет любой символ на этом месте». Звездочка («*») означает «подойдет предыдущий символ в количестве от нуля и более». Таким образом, комбинация «.*» означает, что подойдет любой символ в любом количестве. Например, «our amazing products», «ours, the best-ever products» и даже «ourproducts» будут соответствовать выражению. А так как указана опция –i, ему будут соответствовать также «OUR PRODUCTS» и «OuRpRoDuCtS». При запуске команды с этим регулярным выражением мы получим дополнительные совпадения:
$ grep –-color –n -i «our.*products» *.html product-details.html:27:<p><b>OUR PRODUCTS</b></p> product-details.html:59:<p class=”products-searchbox”>To search a comprehensive list of our products type your search term in the box below and click the magnifying glass</p> product-replacement.html:58:<p>If you experience dissatisfaction with any of our fine products, do not hesitate to contact us using the form below.</p> $
Была найдена фраза «our fine products».
Grep – мощный инструмент работы с текстовыми файлами. При умелом использовании регулярных выражений он предоставляет еще более широкие возможности. Здесь рассмотрены наиболее типичные примеры использования команды. Другие опции командной строки можно узнать, запустив команду с опцией —help.
Примеры использования
А теперь давайте рассмотрим примеры find, чтобы вы лучше поняли, как использовать эту утилиту.
2. Поиск файлов в определенной папке
Показать все файлы в указанной директории:
Искать файлы по имени в текущей папке:
Не учитывать регистр при поиске по имени:
5. Несколько критериев
Поиск командой find в Linux по нескольким критериям, с оператором исключения:
Найдет все файлы, начинающиеся на test, но без расширения php. А теперь рассмотрим оператор ИЛИ:
8. Поиск по разрешениям
Найти файлы с определенной маской прав, например, 0664:
Найти файлы с установленным флагом suid/guid:
Или так:
Поиск файлов только для чтения:
Найти только исполняемые файлы:
Найти все файлы, принадлежащие пользователю:
Поиск файлов в Linux принадлежащих группе:
10. Поиск по дате модификации
Поиск файлов по дате в Linux осуществляется с помощью параметра mtime. Найти все файлы модифицированные 50 дней назад:
Поиск файлов в Linux открытых N дней назад:
Найти все файлы, модифицированные между 50 и 100 дней назад:
Найти файлы измененные в течении часа:
Найти все файлы размером 50 мегабайт:
От пятидесяти до ста мегабайт:
Найти самые маленькие файлы:
Самые большие:
13. Действия с найденными файлами
Для выполнения произвольных команд для найденных файлов используется опция -exec. Например, выполнить ls для получения подробной информации о каждом файле:
Удалить все текстовые файлы в tmp
Удалить все файлы больше 100 мегабайт:
File and directory selection
| -a, —text | Process a binary file as if it were text; this is equivalent to the —binary-files=text option. |
| —binary-files=TYPE | If the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binary file matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. Warning: grep —binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. |
| -D ACTION, —devices=ACTION | If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read as if they were ordinary files. If ACTION is skip, devices are silently skipped. |
| -d ACTION, —directories=ACTION | If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. |
| —exclude=GLOB | Skip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and as wildcards, and \ to quote a wildcard or backslash character literally. |
| —exclude-from=FILE | Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under —exclude). |
| —exclude-dir=DIR | Exclude directories matching the pattern DIR from recursive searches. |
| -I | Process a binary file as if it did not contain matching data; this is equivalent to the —binary-files=without-match option. |
| —include=GLOB | Search only files whose base name matches GLOB (using wildcard matching as described under —exclude). |
| -r, —recursive | Read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -d recurse option. |
| -R, —dereference-recursive | Read all files under each directory, recursively. Follow all symbolic links, unlike -r. |
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, by using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
EXAMPLE top
The following example outputs the location and contents of any line
containing “f” and ending in “.c”, within all files in the current
directory whose names contain “g” and end in “.h”. The -n option
outputs line numbers, the -- argument treats expansions of “*g*.h”
starting with “-” as file names not options, and the empty file
/dev/null causes file names to be output even if only one file name
happens to be of the form “*g*.h”.
$ grep -n -- 'f.*\.c$' *g*.h /dev/null
argmatch.h:1:/* definitions and prototypes for argmatch.c
The only line that matches is line 1 of argmatch.h. Note that the
regular expression syntax used in the pattern differs from the glob‐
bing syntax that the shell uses to match file names.
Основная информация о Find
Find — это одна из наиболее важных и часто используемых утилит системы Linux. Это команда для поиска файлов и каталогов на основе специальных условий. Ее можно использовать в различных обстоятельствах, например, для поиска файлов по разрешениям, владельцам, группам, типу, размеру и другим подобным критериям.
Утилита find предустановлена по умолчанию во всех Linux дистрибутивах, поэтому вам не нужно будет устанавливать никаких дополнительных пакетов. Это очень важная находка для тех, кто хочет использовать командную строку наиболее эффективно.
Команда find имеет такой синтаксис:
find критерий шаблон
Папка — каталог в котором будем искать
Параметры — дополнительные параметры, например, глубина поиска, и т д
Критерий — по какому критерию будем искать: имя, дата создания, права, владелец и т д.
Шаблон — непосредственно значение по которому будем отбирать файлы.
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
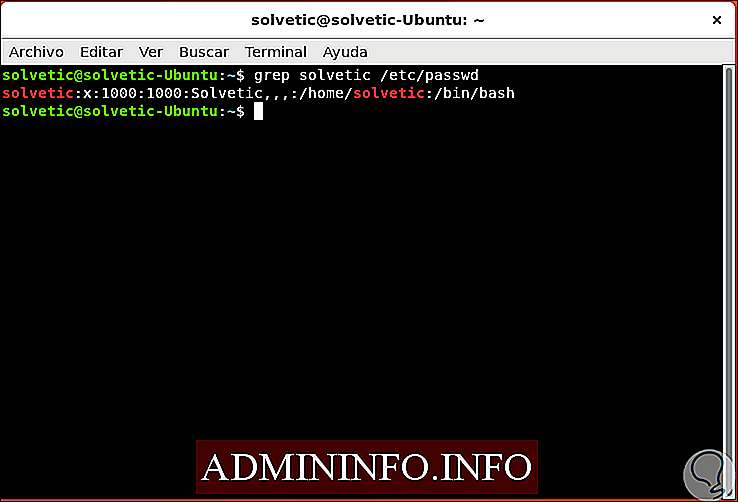
Как использовать Grep в общем
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd
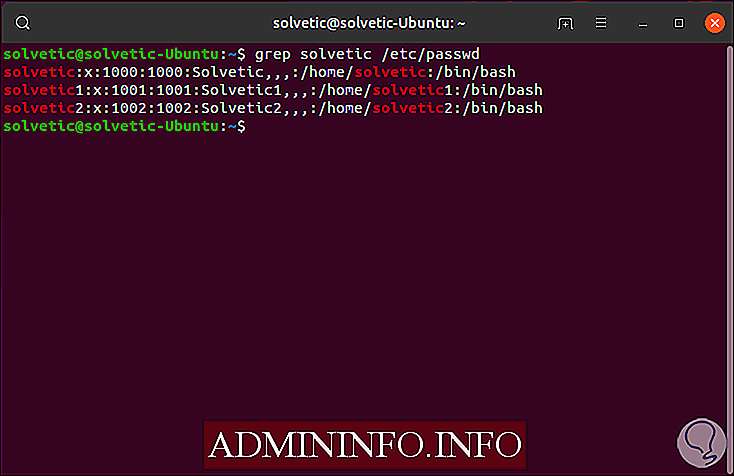
В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd
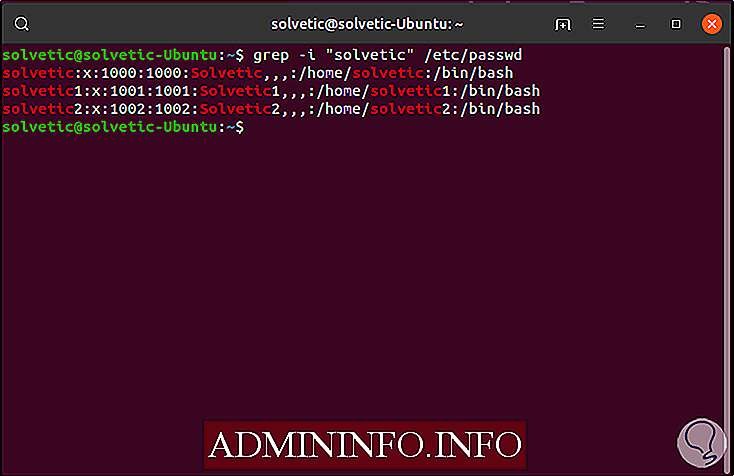
Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt
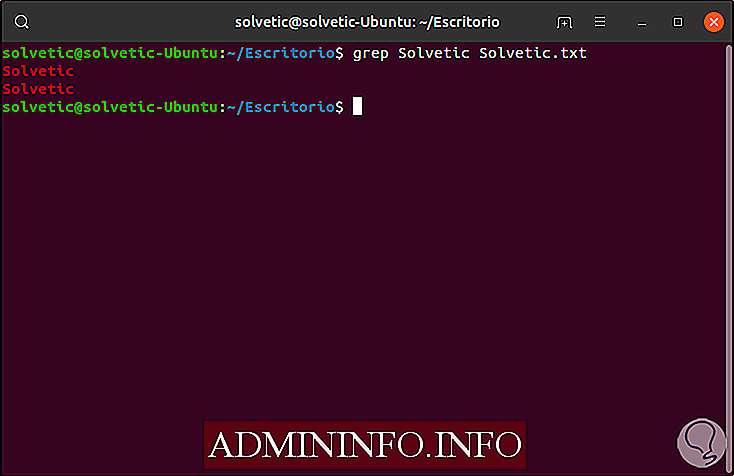
Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt
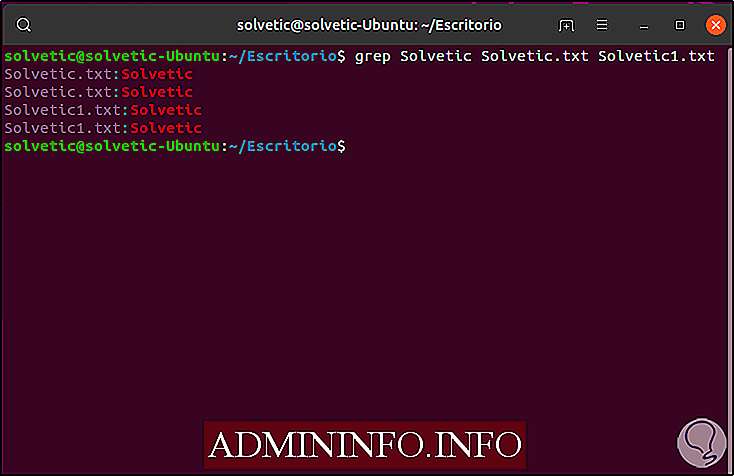
Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *
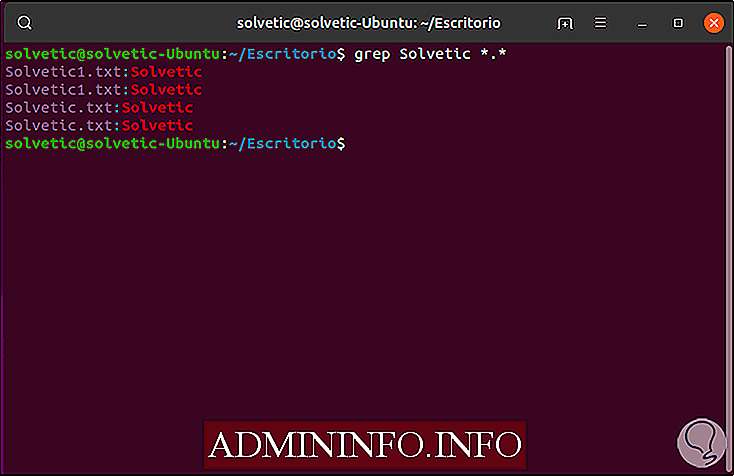
Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt
Как использовать grep для поиска в каталогах
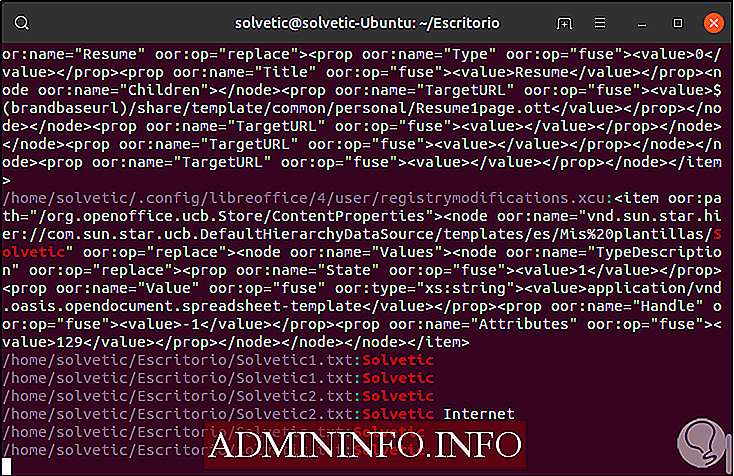
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий
Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt
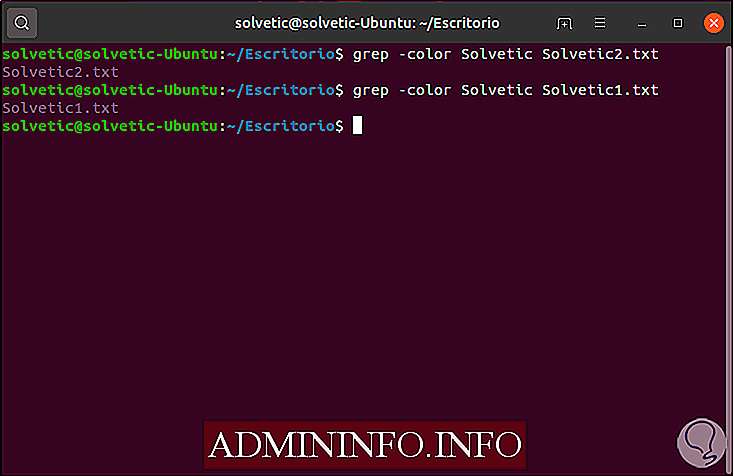
Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt
Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt
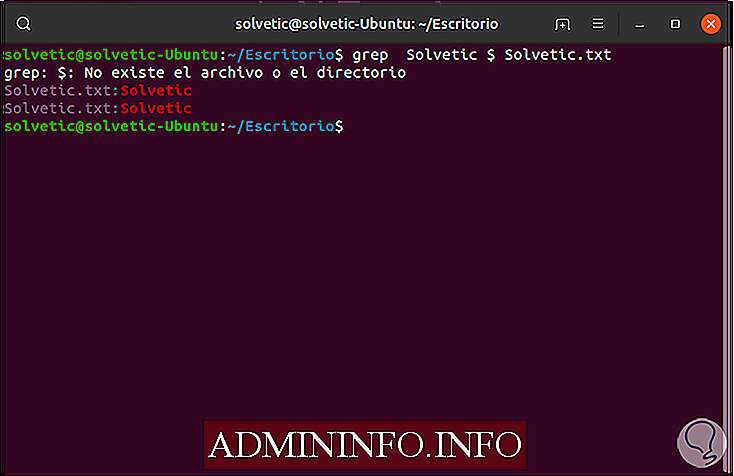
Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
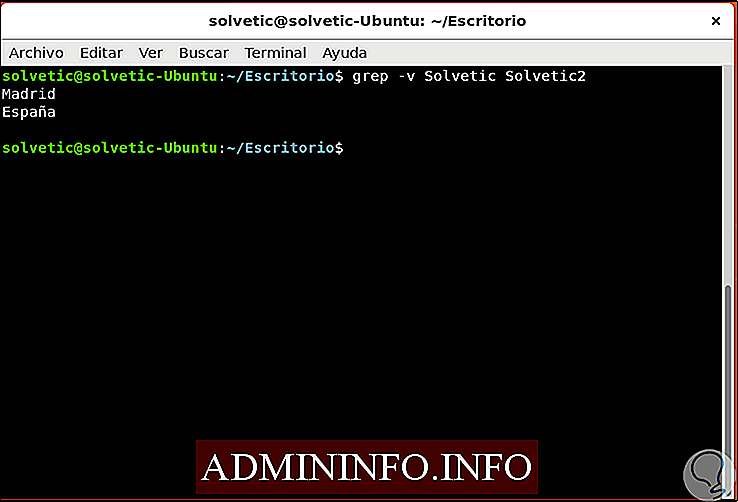
grep Solvetic $ Solvetic.txt
Как использовать grep для печати всех строк, не видя совпадающих
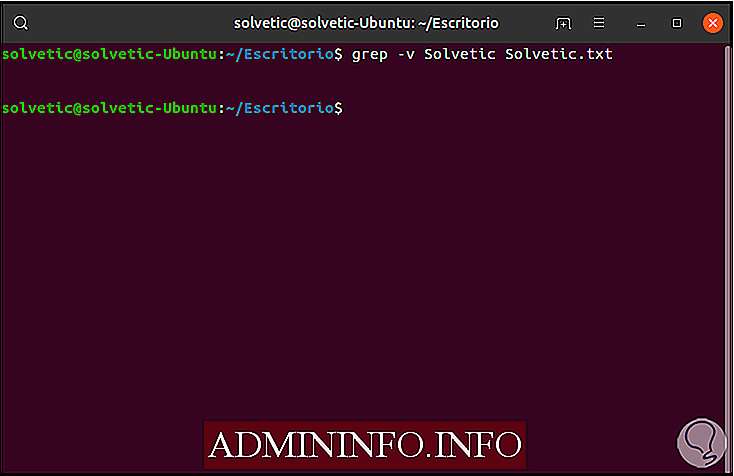
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt
Как использовать grep с другими командами
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http
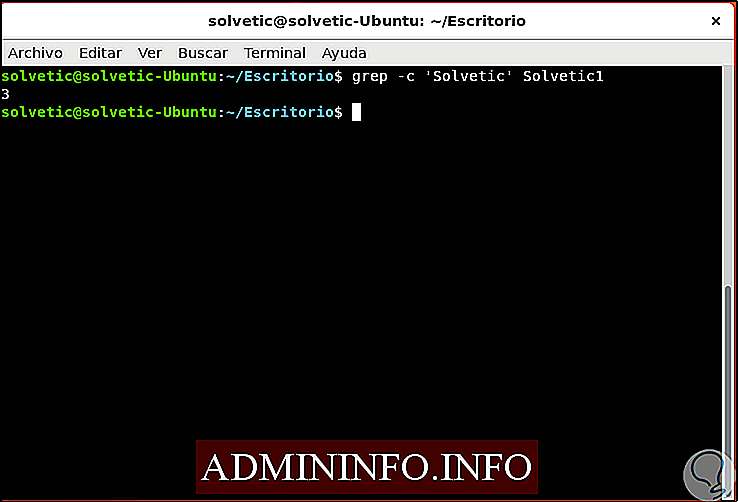
Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt
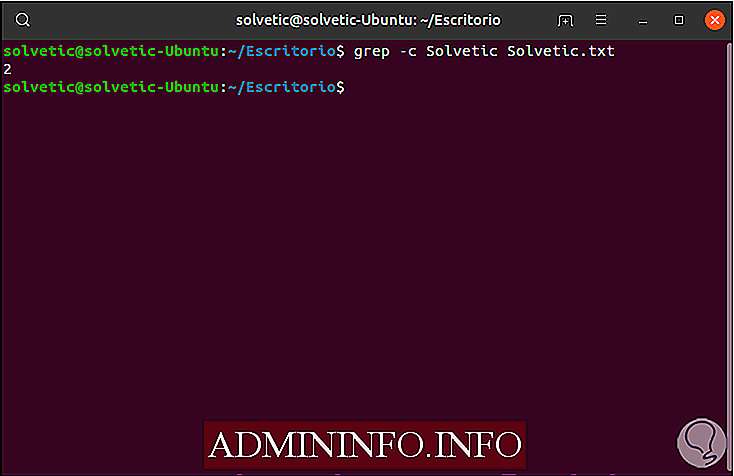
Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
grep -v Solvetic Solvetic2.txt
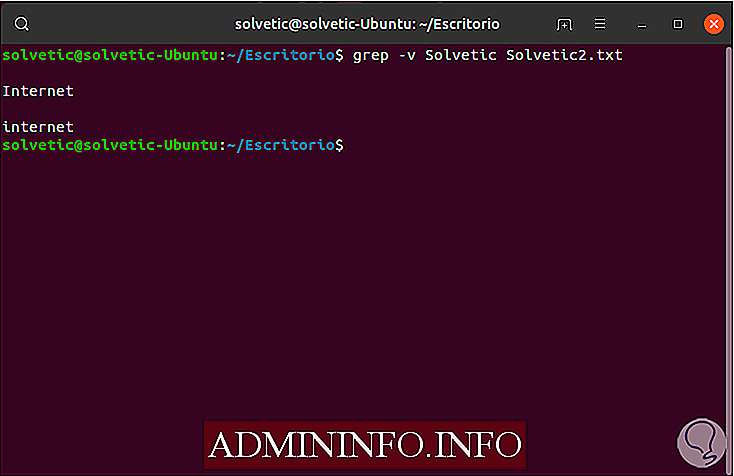
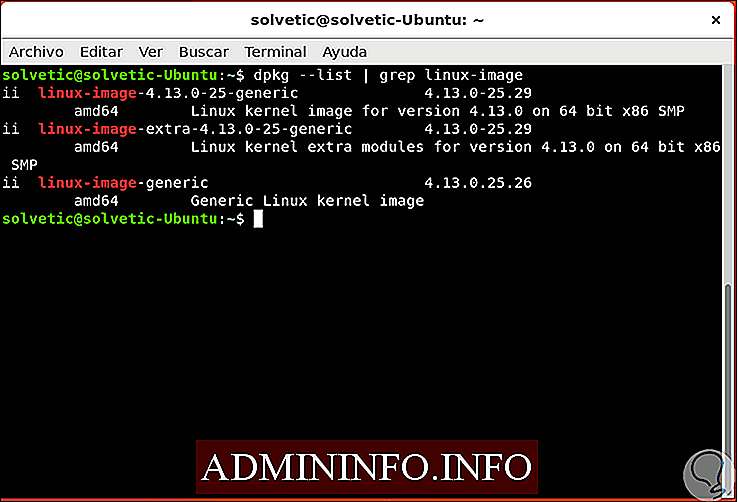
Как использовать grep для просмотра сведений об оборудовании
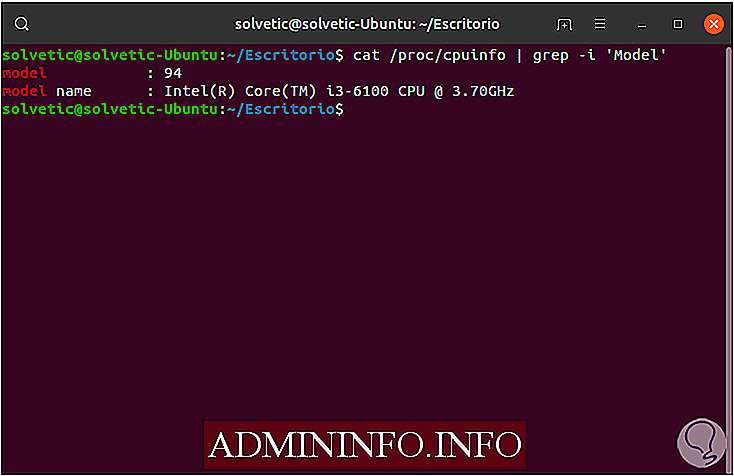
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'
Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.