Регулярные выражения javascript — шпаргалка
Содержание:
- Введение в регулярные выражения¶
- Опережающая проверка
- Создание простого регулярного выражения и флаги
- Упрощённый пример
- 2 Практический раздел. Ссылки
- Всесильные регулярные выражения и их особенности
- Синтаксис регулярных выражений
- Статические свойства
- Поиск всех совпадений с группами: matchAll
- Заметки о методах
- str.replace(str|regexp, str|func)
- Группировка в регулярных выражениях
- Полезные методы работы с регулярными выражениями в JavaScript
- JavaScript
- Строковые методы, поиск и замена
- Quantifiers
Введение в регулярные выражения¶
Регулярные выражения (RegExp) — это очень эффективный способ работы со строками.
Составив регулярное выражение с помощью специального синтаксиса вы можете:
- искать текст в строке
- заменять подстроки в строке
- извлекать информацию из строки
Почти во всех языках программирования есть регулярные выражения. Есть небольшие различия в реализации, но общие концепции применяются практически везде.
Регулярные выражения относятся к 1950-м годам, когда они были формализованы как концептуальный шаблон поиска для алгоритмов обработки строк.
Регулярные выражения реализованные в UNIX, таких как grep, sed и популярных текстовых редакторах, начали набирать популярность и были добавлены в язык программирования Perl, а позже и в множество других языков.
JavaScript, наряду с Perl, это один из языков программирования в котором поддержка регулярных выражений встроена непосредственно в язык.
Опережающая проверка
Синтаксис опережающей проверки: .
Он означает: найди при условии, что за ним следует . Вместо и здесь может быть любой шаблон.
Для целого числа, за которым идёт знак , шаблон регулярного выражения будет :
Обратим внимание, что проверка – это именно проверка, содержимое скобок не включается в результат. При поиске движок регулярных выражений, найдя , проверяет есть ли после него
Если это не так, то игнорирует совпадение и продолжает поиск дальше
При поиске движок регулярных выражений, найдя , проверяет есть ли после него . Если это не так, то игнорирует совпадение и продолжает поиск дальше.
Возможны и более сложные проверки, например означает:
- Найти .
- Проверить, идёт ли сразу после (если нет – не подходит).
- Проверить, идёт ли сразу после (если нет – не подходит).
- Если обе проверки прошли – совпадение найдено.
То есть, этот шаблон означает, что мы ищем при условии, что за ним идёт и и .
Такое возможно только при условии, что шаблоны и не являются взаимно исключающими.
Например, ищет при условии, что за ним идёт пробел, и где-то впереди есть :
В нашей строке это как раз число .
Создание простого регулярного выражения и флаги
Для тестирования и написания паттернов в режиме онлайн я обычно использую сервис https://regex101.com. Выбираете там Javascript и смотрите в риалтайме, как обрабатывается текст вашей регуляркой, плюс там есть подсказки и небольшой справочник.
Есть несколько способов задания регулярного выражения. Вот пример синтаксиса:
// Стандартный метод
var re = new RegExp("паттерн", "флаги");
// Укороченная форма записи
var re = /паттерн/; // без флагов
var re = /паттерн/gmi; // с флагами gmi
Флаги — это параметры поиска, их всего несколько видов и вы можете использовать любой из них, или даже все сразу.i — ignore case, Если этот флаг есть, то регэксп ищет независимо от регистра, то есть не различает между А и а.g — global match, Если этот флаг есть, то регэксп ищет все совпадения, иначе – только первое.m — multiline, Многострочный режим.
Пример использования:
var str = 'Писать ботов на iMacros+JS очень круто!'; window.console.log(/imacros/i.test(str)); // true window.console.log(/imacros/.test(str)); // false
Упрощённый пример
В чём же дело? Почему регулярное выражение «зависает»?
Чтобы это понять, упростим пример: уберём из него пробелы . Получится .
И, для большей наглядности, заменим на . Получившееся регулярное выражение тоже будет «зависать», например:
В чём же дело, что не так с регулярным выражением?
Внимательный читатель, посмотрев на , наверняка удивится, ведь оно какое-то странное. Квантификатор здесь выглядит лишним. Если хочется найти число, то с тем же успехом можно искать .
Действительно, это регулярное выражение носит искусственный характер, но, разобравшись с ним, мы поймём и практический пример, данный выше. Причина их медленной работы одинакова. Поэтому оставим как есть.
Что же происходит во время поиска в строке (укоротим для ясности), почему всё так долго?
-
Первым делом, движок регулярных выражений пытается найти . Плюс является жадным по умолчанию, так что он хватает все цифры, какие может:
Затем движок пытается применить квантификатор , но больше цифр нет, так что звёздочка ничего не даёт.
Далее по шаблону ожидается конец строки , а в тексте символ , так что соответствий нет:
-
Так как соответствие не найдено, то «жадный» квантификатор уменьшает количество повторений, возвращается на один символ назад.
Теперь – это все цифры, за исключением последней:
-
Далее движок снова пытается продолжить поиск, начиная уже с позиции ().
Звёздочка теперь может быть применена – она даёт второе число :
Затем движок ожидает найти , но это ему не удаётся, ведь строка оканчивается на :
-
Так как совпадения нет, то поисковый движок продолжает отступать назад. Общее правило таково: последний жадный квантификатор уменьшает количество повторений до тех пор, пока это возможно. Затем понижается предыдущий «жадный» квантификатор и т.д.
Перебираются все возможные комбинации. Вот их примеры.
Когда первое число содержит 7 цифр, а дальше число из 2 цифр:
Когда первое число содержит 7 цифр, а дальше два числа по 1 цифре:
Когда первое число содержит 6 цифр, а дальше одно число из 3 цифр:
Когда первое число содержит 6 цифр, а затем два числа:
…И так далее.
Существует много способов как разбить на числа набор цифр . Если быть точным, их , где – длина набора.
В случае их порядка миллиона, при – ещё в тысячу раз больше. На их перебор и тратится время.
Что же делать?
Может нам стоит использовать «ленивый» режим?
К сожалению, нет: если мы заменим на , то регулярное выражение всё ещё будет «зависать». Поменяется только порядок перебора, но не общее количество комбинаций.
Некоторые движки регулярных выражений содержат хитрые проверки и конечные автоматы, которые позволяют избежать полного перебора в таких ситуациях или кардинально ускорить его, но не все движки и не всегда.
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
Всесильные регулярные выражения и их особенности
А более опытный разработчик поймет, что данное выражение проверяет введенное мыло на корректность. Таким образом, в написанном должна быть почта, состоящее из цифр, букв, знака тире и/или нижнего подчеркивания, после обязательно должен присутствовать один знак собачки, за которым следуют буквы, тире и цифры, а далее точка и от двух до шести символов.
Это и есть основная отличительная черта регулярных выражений. Они абсолютно не похожи ни на какие известные вам ранее средства программирования.
Итак, регулярные выражение по-простому можно назвать образцом, шаблоном, по которому идет сопоставление символов в строках. Благодаря им можно производить поиск, проверку и замену строковых значений.
Главным их преимуществом является удобный способ записи универсальных формул проверки значений.
Вот пример тестирования на валидность мобильного номера вида (+ХХХХХХХХХХХХ):
Также с помощью шаблонов можно производить поиск совпадений слов/выражений в тексте с искомым значением.
Синтаксис регулярных выражений
Последнее обновление: 1.11.2015
Рассмотрим базовые моменты синтаксиса регулярных выражений.
Метасимволы
Регулярные выражения также могут использовать метасимволы — символы, которые имеют определенный смысл:
-
: соответствует любой цифре от 0 до 9
-
: соответствует любому символу, который не является цифрой
-
: соответствует любой букве, цифре или символу подчеркивания (диапазоны A–Z, a–z, 0–9)
-
: соответствует любому символу, который не является буквой, цифрой или символом подчеркивания (то есть не находится
в следующих диапазонах A–Z, a–z, 0–9) -
: соответствует пробелу
-
: соответствует любому символу, который не является пробелом
-
: соответствует любому символу
Здесь надо заметить, что метасимвол \w применяется только для букв латинского алфавита, кириллические символы для него не подходят.
Так, стандартный формат номера телефона соответствует регулярному выражению .
Например, заменим числа номера нулями:
var phoneNumber = "+1-234-567-8901"; var myExp = /\d-\d\d\d-\d\d\d-\d\d\d\d/; phoneNumber = phoneNumber.replace(myExp, "00000000000"); document.write(phoneNumber);
Модификаторы
Кроме выше рассмотренных элементов регулярных выражений есть еще одна группа комбинаций, которая указывает, как символы в строке будут повторяться.
Такие комбинации еще называют модификаторами:
-
: соответствует n-ому количеству повторений предыдущего символа. Например, соответствует подстроке «hhh»
-
: соответствует n и более количеству повторений предыдущего символа. Например, соответствует подстрокам
«hhh», «hhhh», «hhhhh» и т.д. -
: соответствует от n до m повторений предыдущего символа. Например, соответствует подстрокам
«hh», «hhh», «hhhh». -
: соответствует одному вхождению предыдущего символа в подстроку или его отсутствию в подстроке. Например, соответствует подстрокам
«home» и «ome». -
: соответствует одному и более повторений предыдущего символа
-
: соответствует любому количеству повторений или отсутствию предыдущего символа
-
: соответствует началу строки. Например, соответствует строке «home», но не «ohma», так как h должен представлять начало строки
-
: соответствует концу строки. Например, соответствует строке «дом», так как строка должна оканчиваться на букву м
Например, возьмем номер тот же телефона. Ему соответствует регулярное выражение . Однако с
помощью выше рассмотренных комбинаций мы его можем упростить:
Также надо отметить, что так как символы ?, +, * имеют особый смысл в регулярных выражениях, то чтобы их использовать в обычным для них значении
(например, нам надо заменить знак плюс в строке на минус), то данные символы надо экранировать с помощью слеша:
var phoneNumber = "+1-234-567-8901";
var myExp = /\+\d-\d{3}-\d{3}-\d{4}/;
phoneNumber = phoneNumber.replace(myExp, "80000000000");
document.write(phoneNumber);
Отдельно рассмотрим применение комбинации ‘\b’, которая указывает на соответствие в пределах слова. Например, у нас есть
следующая строка: «Языки обучения: Java, JavaScript, C++». Со временем мы решили, что Java надо заменить на C#. Но простая замена приведет также
к замене строки «JavaScript» на «C#Script», что недопустимо. И в этом случае мы можем проводить замену, если регуляное выражение соответствует
всему слову:
var initialText = "Языки обучения: Java, JavaScript, C++"; var exp = /Java\b/g; var result = initialText.replace(exp, "C#"); document.write(result); // Языки обучения: C#, JavaScript, C++
Но при использовании ‘\b’ надо учитывать, что в JavaScript отсутствует полноценная поддержка юникода, поэтому применять ‘\b’ мы сможем только к англоязычным словам.
Использование групп в регулярных выражениях
Для поиска в строке более сложных соответствий применяются группы. В регулярных выражениях группы заключаются в скобки. Например,
у нас есть следующий код html, который содержит тег изображения: ‘<img src=»picture.png» />’. И допустим, нам надо вычленить из этого
кода пути к изображениям:
var initialText = '<img src= "picture.png" />';
var exp = /+\.(png|jpg)/i;
var result = initialText.match(exp);
result.forEach(function(value, index, array){
document.write(value + "<br/>");
})
Вывод браузера:
picture.png png
Первая часть до скобок (+\.) указывает на наличие в строке от 1 и более символов из диапазона a-z, после которых идет точка. Так как точка
является специальным символом в регулярных выражениях, то она экранируется слешем. А дальше идет группа: .
Эта группа указывает, что после точки может использоваться как «png», так и «jpg».
НазадВперед
Статические свойства
Ну и напоследок — еще одна совсем оригинальная особенность регулярных выражений.
Вот — одна интересная функция.
Запустите ее один раз, запомните результат — и запустите еще раз.
function rere() {
var re1 = /0/, re2 = new RegExp('0')
alert()
re1.foo = 1
re2.foo = 1
}
rere()
В зависимости от браузера, результат первого запуска может отличаться от второго. На текущий момент, это так для Firefox, Opera. При этом в Internet Explorer все нормально.
С виду функция создает две локальные переменные и не зависит от каких-то внешних факторов.
Почему же разный результат?
Ответ кроется в стандарте ECMAScript, :
Цитата…
A regular expression literal is an input element that is converted to a RegExp object (section 15.10)
when it is scanned. The object is created before evaluation of the containing program or function begins.
Evaluation of the literal produces a reference to that object; it does not create a new object.
То есть, простыми словами, литеральный регэксп не создается каждый раз при вызове .
Вместо этого браузер возвращает уже существующий объект, со всеми свойствами, оставшимися от предыдущего запуска.
В отличие от этого, всегда создает новый объект, поэтому и ведет себя в примере по-другому.
Поиск всех совпадений с группами: matchAll
является новым, может потребоваться полифил
Метод не поддерживается в старых браузерах.
Может потребоваться полифил, например https://github.com/ljharb/String.prototype.matchAll.
При поиске всех совпадений (флаг ) метод не возвращает скобочные группы.
Например, попробуем найти все теги в строке:
Результат – массив совпадений, но без деталей о каждом. Но на практике скобочные группы тоже часто нужны.
Для того, чтобы их получать, мы можем использовать метод .
Он был добавлен в язык JavaScript гораздо позже чем , как его «новая и улучшенная» версия.
Он, как и , ищет совпадения, но у него есть три отличия:
- Он возвращает не массив, а перебираемый объект.
- При поиске с флагом , он возвращает каждое совпадение в виде массива со скобочными группами.
- Если совпадений нет, он возвращает не , а просто пустой перебираемый объект.
Например:
Как видите, первое отличие – очень важное, это демонстрирует строка. Мы не можем получить совпадение как , так как этот объект не является псевдомассивом
Его можно превратить в настоящий массив при помощи . Более подробно о псевдомассивах и перебираемых объектов мы говорили в главе Перебираемые объекты.
В явном преобразовании через нет необходимости, если мы перебираем результаты в цикле, вот так:
…Или используем деструктуризацию:
Каждое совпадение, возвращаемое , имеет тот же вид, что и при без флага : это массив с дополнительными свойствами (позиция совпадения) и (исходный текст):
Почему результат – перебираемый объект, а не обычный массив?
Зачем так сделано? Причина проста – для оптимизации.
При вызове движок JavaScript возвращает перебираемый объект, в котором ещё нет результатов. Поиск осуществляется по мере того, как мы запрашиваем результаты, например, в цикле.
Таким образом, будет найдено ровно столько результатов, сколько нам нужно.
Например, всего в тексте может быть 100 совпадений, а в цикле после 5-го результата мы поняли, что нам их достаточно и сделали . Тогда движок не будет тратить время на поиск остальных 95.
Заметки о методах
Для работы с регулярными выражениями используется семь методов. Начнем разбор по порядку.
Search ()
Используется для нахождения позиции вхождения первого совпадения.
1 2 3 4 5 6 |
<script> var regExp = /рыб/gi; var text = "Покупайте речную рыбу!"; var myArray = text.search(regExp ); alert(myArray); //Ответ: 17 </script> |
Match ()
Работает в двух режимах в зависимости от того, укажете ли вы опциональный флаг g или нет.
Если /g отсутствует, то в результате будет получен массив из одного элемента и с возможностью просмотра дополнительных свойств input (строка, в которой осуществлялся поиск совпадений) и index (позиция результата; если подстрока не найдена, то покажет -1).
1 2 3 4 5 6 7 8 |
<script> var regExp = /12.02/; var text = "11.02 - Концерт. 12.02 - Мастер-класс."; var myArray = text.match(regExp ); alert( myArray ); alert( myArray.input ); //11.02 - Концерт. 12.02 - Мастер-класс. alert( myArray.index ); //17 </script> |
Если же вы используете глобальный поиск, то возможность просмотра дополнительных свойств пропадает, а в массиве вернутся все совпадения.
Split ()
Как и в некоторых других языках программирования, метод Split () разбивает значение строковой переменной на подстроки по заданному разделителю.
1 2 3 4 |
<script>
var text = "Пусть все будет хорошо";
alert(text.split(' ')); //Пусть,все,будет,хорошо
</script>
|
В качестве разделителя можно передавать как строковое значение, так и регэксп.
Replace ()
Очень удобный инструмент для нахождения и замены символов в задачах различной сложности. По умолчанию изменяет только первое совпавшее вхождение, однако это исправимо благодаря такой удобной штуке, как /g.
1 2 3 4 |
<script> var text = "Ты пробежал 3 км за 13 и 25 минут."; alert( text.replace( / и /g, "," )); // Ты пробежал 3 км за 13,25 минут </script> |
Exec ()
До этого все методы принадлежали к классу String. А оставшиеся два предоставляются классом RegExp.
Итак, текущий метод является дополнением к первым двум описанным методам. Он также ищет все вхождения и еще скобочные группы. Без указания флага g exec () работает, как match (). В противном случае совпадение запоминается, а его позиция записывается в lastIndex.
Последующий поиск продолжается с установленной позиции. Если далее совпадений больше не было, то lastIndex сбрасывается в 0.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<script>
var str = 'Сорок сорок сидели на трубе';
var expresion = /сорок/ig;
var res;
alert( "lastIndex: " + expresion.lastIndex );
while (res = expresion.exec(str)) {
alert( 'Найдено: ' + res + ' на позиции: ' + res.index );
alert( 'А теперь lastIndex равен: ' + expresion.lastIndex );
}
alert( 'Под конец lastIndex сбрасывается в: ' + expresion.lastIndex );
</script>
|
Test ()
Данный инструмент проверяет, а есть ли хоть один результат совпадения строк. Если есть, то возвращает булево значение true, иначе – false.
1 2 3 4 |
<script>
var expresion = /крас/gi;
alert( expresion.test("Ах, какая красна девица! красавица!")); //true
</script>
|
Вот я и рассказал вам основы такого механизма, как регулярные выражения. Для лучшего усвоения материала читайте и другие статьи на данную тематику на моем блоге, а также становитесь подписчиками и делитесь интересными ссылками с друзьями. Пока-пока!
Прочитано: 119 раз
str.replace(str|regexp, str|func)
This is a generic method for searching and replacing, one of most useful ones. The swiss army knife for searching and replacing.
We can use it without regexps, to search and replace a substring:
There’s a pitfall though.
When the first argument of is a string, it only replaces the first match.
You can see that in the example above: only the first is replaced by .
To find all hyphens, we need to use not the string , but a regexp , with the obligatory flag:
The second argument is a replacement string. We can use special character in it:
| Symbols | Action in the replacement string |
|---|---|
| inserts the whole match | |
| inserts a part of the string before the match | |
| inserts a part of the string after the match | |
| if is a 1-2 digit number, inserts the contents of n-th capturing group, for details see Capturing groups | |
| inserts the contents of the parentheses with the given , for details see Capturing groups | |
| inserts character |
For instance:
For situations that require “smart” replacements, the second argument can be a function.
It will be called for each match, and the returned value will be inserted as a replacement.
The function is called with arguments :
- – the match,
- – contents of capturing groups (if there are any),
- – position of the match,
- – the source string,
- – an object with named groups.
If there are no parentheses in the regexp, then there are only 3 arguments: .
For example, let’s uppercase all matches:
Replace each match by its position in the string:
In the example below there are two parentheses, so the replacement function is called with 5 arguments: the first is the full match, then 2 parentheses, and after it (not used in the example) the match position and the source string:
If there are many groups, it’s convenient to use rest parameters to access them:
Or, if we’re using named groups, then object with them is always the last, so we can obtain it like this:
Using a function gives us the ultimate replacement power, because it gets all the information about the match, has access to outer variables and can do everything.
Группировка в регулярных выражениях
(ABC) – Объединение несколько символов вместе. Подстрока, соответствующую этому выражению сохраняется для последующего использования.
(?:ABC) – Это выражение также производит поиск группы символов, но не сохраняет результат.
\d+(?=ABC) – выражение соответствует символам предшествующим (?=ABC), только если за ним следует “ABC”. Часть “ABC” не будет учитываться при поиске. Часть выражения “\d” приведена всего лишь для примера. На ее месте может быть любое регулярное выражение.
\d+(?!ABC) – выражение соответствует символам предшествующим (?!ABC), только если за ним НЕ следует “ABC”. Часть “ABC” не будет учитываться при поиске. Часть выражения “\d” приведена всего лишь для примера. На ее месте может быть любое регулярное выражение.
Полезные методы работы с регулярными выражениями в JavaScript
Регулярные выражения, создаваемые с использованием флагов и последовательностей символов, которые мы обсуждали ранее в этой статье, предназначены для использования с различными методами JavaScript для поиска, замены или разделения строк.
Вот некоторые методы, связанные с регулярными выражениями.
► test() – проверяет, содержит ли основная строка подстроку, которая соответствует шаблону, заданному данным регулярным выражением. При успешном совпадении метод возвращает true, в противном случае — false.
JavaScript
var textA = 'I like APPles very much'; var textB = 'I like APPles'; var regexOne = /apples$/i // вернет false console.log(regexOne.test(textA)); // вернет true console.log(regexOne.test(textB));
В приведённом выше примере приведено регулярное выражение, предназначенное для поиска слова “apples” в случае, если оно расположено в конце строки. Поэтому в первом случае метод вернет false.
► search() – проверяет, содержит ли основная строка подстроку, которая соответствует шаблону, заданному данным регулярным выражением. Метод возвращает индекс совпадения при успехе и -1 в противном случае.
JavaScript
var textA = 'I like APPles very much'; var regexOne = /apples/; var regexTwo = /apples/i; // Результат: -1 console.log(textA.search(regexOne)); // Результат: 7 console.log(textA.search(regexTwo));
В данном примере проверка по превому регулярному выражению вернет -1, потому что не указан флаг нечувствительности к регистру.
► match() – осуществляет поиск подстроки в основной строке. Подстрока должна соответствовать шаблону, заданному данным регулярным выражением. Если используется флаг g, то несколько совпадений будут возвращены в виде массива.
JavaScript
var textA = 'All I see here are apples, APPles and apPleS'; var regexOne = /apples/gi; // Результат: console.log(textA.match(regexOne));
► exec() – производит поиск подстроки в основной строке. В случае, если подстрока соответствует шаблону, заданному данным регулярным выражением, возвращает массив с результатами или null. В свойстве input хранится оригинальная строка
JavaScript
var textA = 'Do you like apples?'; var regexOne = /apples/; // Результат: apples console.log(regexOne.exec(textA)); // Результат : Do you like apples? console.log(regexOne.exec(textA).input);
► replace() – ищет подстроку, соответствующую заданному шаблону и заменяет ее на предоставленную заменяющую строку.
JavaScript
var textA = 'Do you like aPPles?'; var regexOne = /apples/i // Результат: Do you like mangoes? console.log(textA.replace(regexOne, 'mangoes'));
► split() – Этот метод позволит вам разбить основную строку на подстроки на основе разделителя, представленного в виде регулярного выражения.
JavaScript
var textA = 'This 593 string will be brok294en at places where d1gits are.'; var regexOne = /\d+/g // Результат : console.log(textA.split(regexOne))
JavaScript
JS Array
concat()
constructor
copyWithin()
entries()
every()
fill()
filter()
find()
findIndex()
forEach()
from()
includes()
indexOf()
isArray()
join()
keys()
length
lastIndexOf()
map()
pop()
prototype
push()
reduce()
reduceRight()
reverse()
shift()
slice()
some()
sort()
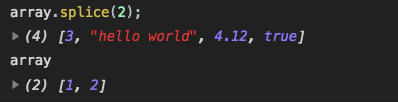
splice()
toString()
unshift()
valueOf()
JS Boolean
constructor
prototype
toString()
valueOf()
JS Classes
constructor()
extends
static
super
JS Date
constructor
getDate()
getDay()
getFullYear()
getHours()
getMilliseconds()
getMinutes()
getMonth()
getSeconds()
getTime()
getTimezoneOffset()
getUTCDate()
getUTCDay()
getUTCFullYear()
getUTCHours()
getUTCMilliseconds()
getUTCMinutes()
getUTCMonth()
getUTCSeconds()
now()
parse()
prototype
setDate()
setFullYear()
setHours()
setMilliseconds()
setMinutes()
setMonth()
setSeconds()
setTime()
setUTCDate()
setUTCFullYear()
setUTCHours()
setUTCMilliseconds()
setUTCMinutes()
setUTCMonth()
setUTCSeconds()
toDateString()
toISOString()
toJSON()
toLocaleDateString()
toLocaleTimeString()
toLocaleString()
toString()
toTimeString()
toUTCString()
UTC()
valueOf()
JS Error
name
message
JS Global
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
escape()
eval()
Infinity
isFinite()
isNaN()
NaN
Number()
parseFloat()
parseInt()
String()
undefined
unescape()
JS JSON
parse()
stringify()
JS Math
abs()
acos()
acosh()
asin()
asinh()
atan()
atan2()
atanh()
cbrt()
ceil()
clz32()
cos()
cosh()
E
exp()
expm1()
floor()
fround()
LN2
LN10
log()
log10()
log1p()
log2()
LOG2E
LOG10E
max()
min()
PI
pow()
random()
round()
sign()
sin()
sqrt()
SQRT1_2
SQRT2
tan()
tanh()
trunc()
JS Number
constructor
isFinite()
isInteger()
isNaN()
isSafeInteger()
MAX_VALUE
MIN_VALUE
NEGATIVE_INFINITY
NaN
POSITIVE_INFINITY
prototype
toExponential()
toFixed()
toLocaleString()
toPrecision()
toString()
valueOf()
JS OperatorsJS RegExp
constructor
compile()
exec()
g
global
i
ignoreCase
lastIndex
m
multiline
n+
n*
n?
n{X}
n{X,Y}
n{X,}
n$
^n
?=n
?!n
source
test()
toString()
(x|y)
.
\w
\W
\d
\D
\s
\S
\b
\B
\0
\n
\f
\r
\t
\v
\xxx
\xdd
\uxxxx
JS Statements
break
class
continue
debugger
do…while
for
for…in
for…of
function
if…else
return
switch
throw
try…catch
var
while
JS String
charAt()
charCodeAt()
concat()
constructor
endsWith()
fromCharCode()
includes()
indexOf()
lastIndexOf()
length
localeCompare()
match()
prototype
repeat()
replace()
search()
slice()
split()
startsWith()
substr()
substring()
toLocaleLowerCase()
toLocaleUpperCase()
toLowerCase()
toString()
toUpperCase()
trim()
valueOf()
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Quantifiers
| Quantifier | Description |
|---|---|
| n+ | Matches any string that contains at least one n |
| n* | Matches any string that contains zero or more occurrences of n |
| n? | Matches any string that contains zero or one occurrences of n |
| n{X} | Matches any string that contains a sequence of X n‘s |
| n{X,Y} | Matches any string that contains a sequence of X to Y n‘s |
| n{X,} | Matches any string that contains a sequence of at least X n‘s |
| n$ | Matches any string with n at the end of it |
| ^n | Matches any string with n at the beginning of it |
| ?=n | Matches any string that is followed by a specific string n |
| ?!n | Matches any string that is not followed by a specific string n |