Row_number (transact-sql)row_number (transact-sql)
Содержание:
- ArgumentosArguments
- Esempi: Azure Synapse AnalyticsAzure Synapse Analytics e Parallel Data WarehouseParallel Data WarehouseExamples: Azure Synapse AnalyticsAzure Synapse Analytics and Parallel Data WarehouseParallel Data Warehouse
- RemarksRemarks
- 全般的な解説General Remarks
- Allgemeine HinweiseGeneral Remarks
- 参数Arguments
- Character Functions Returning Character Values
- ArgumentsArguments
- XML Functions
- SQL ROW_NUMBER() Function Overview
- АргументыArguments
- Comentários geraisGeneral Remarks
- BeispieleExamples
- RemarksRemarks
- Отправляйте сообщения в WhatsApp голосом через ассистент Siri
- Виды функций
- Функция NTILE
- SQL ROW_NUMBER() examples
- 示例Examples
- Osservazioni generaliGeneral Remarks
- ПримерыExamples
ArgumentosArguments
PARTITION BY value_expressionPARTITION BY value_expressionDivide o conjunto de resultados produzido pela cláusula FROM nas partições às quais a função ROW_NUMBER é aplicada.Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression especifica a coluna pela qual o conjunto de resultados é particionado.value_expression specifies the column by which the result set is partitioned. Se não for especificado, a função tratará todas as linhas do conjunto de resultados da consulta como um único grupo.If is not specified, the function treats all rows of the query result set as a single group. Para obter mais informações, consulte Cláusula OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
order_by_clauseorder_by_clauseA cláusula determina a sequência na qual as linhas recebem seu exclusivo em uma partição especificada.The clause determines the sequence in which the rows are assigned their unique within a specified partition. É obrigatório.It is required. Para obter mais informações, consulte Cláusula OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
Esempi: Azure Synapse AnalyticsAzure Synapse Analytics e Parallel Data WarehouseParallel Data WarehouseExamples: Azure Synapse AnalyticsAzure Synapse Analytics and Parallel Data WarehouseParallel Data Warehouse
E.E. Restituzione del numero di riga per i venditoriReturning the row number for salespeople
L’esempio seguente restituisce il valore per i venditori in base alle rispettive quote di vendita assegnate.The following example returns the for sales representatives based on their assigned sales quota.
Set di risultati parziale:Here is a partial result set.
F.F. Utilizzo di ROW_NUMBER() con PARTITIONUsing ROW_NUMBER() with PARTITION
Nell’esempio seguente viene illustrato l’utilizzo della funzione con l’argomento .The following example shows using the function with the argument. Ciò determina la numerazione, da parte della funzione , delle righe in ogni partizione.This causes the function to number the rows in each partition.
Set di risultati parziale:Here is a partial result set.
RemarksRemarks
Если выражение expressionToFind или expressionToSearch имеет тип данных Юникода (nchar или nvarchar), а второе выражение — нет, функция CHARINDEX преобразует такое другое выражение в тип данных Юникода.If either the expressionToFind or expressionToSearch expression has a Unicode data type (nchar or nvarchar), and the other expression does not, the CHARINDEX function converts that other expression to a Unicode data type. Функция CHARINDEX не поддерживает типы данных image, ntext и text.CHARINDEX cannot be used with image, ntext, or text data types.
Если выражение expressionToFind или expressionToSearch имеет значение NULL, то CHARINDEX возвращает значение NULL.If either the expressionToFind or expressionToSearch expression has a NULL value, CHARINDEX returns NULL.
Если функции CHARINDEXне удается найти expressionToFind в expressionToSearch, она возвращает 0.If CHARINDEX does not find expressionToFind within expressionToSearch, CHARINDEX returns 0.
Функция CHARINDEX выполняет сравнения на основе параметров сортировки входных данных.CHARINDEX performs comparisons based on the input collation. Для выполнения сравнения в указанных параметрах сортировки используйте функцию COLLATE, чтобы явно указать параметры сортировки для входных данных.To perform a comparison in a specified collation, use COLLATE to apply an explicit collation to the input.
Начальная возвращенная позиция начинается с 1, а не с 0.The starting position returned is 1-based, not 0-based.
Символ 0x0000 (char(0) ) не определен в параметрах сортировки Windows, и его нельзя включать в CHARINDEX.0x0000 (char(0)) is an undefined character in Windows collations and cannot be included in CHARINDEX.
全般的な解説General Remarks
以下の条件が満たされている場合を除き、 を使用したクエリによって返される行が、実行ごとにまったく同じ順序になるという保証はありません。There is no guarantee that the rows returned by a query using will be ordered exactly the same with each execution unless the following conditions are true.
-
パーティション分割された行の値が一意である。Values of the partitioned column are unique.
-
列の値が一意である。Values of the columns are unique.
-
パーティション分割された列と 列の値の組み合わせが一意である。Combinations of values of the partition column and columns are unique.
は非決定的です。 is nondeterministic. 詳細については、「 決定的関数と非決定的関数」を参照してください。For more information, see Deterministic and Nondeterministic Functions.
Allgemeine HinweiseGeneral Remarks
Es gibt keine Garantie, dass die mithilfe von zurückgegebenen Zeilen bei jeder Ausführung exakt gleich sind, es sei denn, die folgenden Bedingungen treffen zu.There is no guarantee that the rows returned by a query using will be ordered exactly the same with each execution unless the following conditions are true.
-
Werte der partitionierten Spalte sind eindeutig.Values of the partitioned column are unique.
-
Werte der -Spalten sind eindeutig.Values of the columns are unique.
-
Kombinationen der Werte der Partitionsspalte und -Spalten sind eindeutig.Combinations of values of the partition column and columns are unique.
ist nicht deterministisch. is nondeterministic. Weitere Informationen finden Sie unter Deterministic and Nondeterministic Functions.For more information, see Deterministic and Nondeterministic Functions.
参数Arguments
PARTITION BY value_expression PARTITION BY value_expression将 FROM 子句生成的结果集划分为应用 ROW_NUMBER 函数的分区。Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression 指定对结果集进行分区所依据的列 。value_expression specifies the column by which the result set is partitioned. 如果未指定 ,则此函数将查询结果集的所有行视为单个组。If is not specified, the function treats all rows of the query result set as a single group. 有关详细信息,请参阅 OVER 子句 (Transact-SQL)。For more information, see OVER Clause (Transact-SQL).
order_by_clause order_by_clause 子句可确定在特定分区中为行分配唯一 的顺序。The clause determines the sequence in which the rows are assigned their unique within a specified partition. 它是必需的。It is required. 有关详细信息,请参阅 OVER 子句 (Transact-SQL)。For more information, see OVER Clause (Transact-SQL).
Character Functions Returning Character Values
Character functions that return character values return values of the following data types unless otherwise documented:
-
If the input argument is or , then the value returned is .
-
If the input argument is or , then the value returned is .
The length of the value returned by the function is limited by the maximum length of the data type returned.
-
For functions that return or , if the length of the return value exceeds the limit, then Oracle Database truncates it and returns the result without an error message.
-
For functions that return values, if the length of the return values exceeds the limit, then Oracle raises an error and returns no data.
The character functions that return character values are:
ArgumentsArguments
PARTITION BY value_expressionPARTITION BY value_expressionDivise le jeu de résultats généré par la clause FROM en partitions auxquelles la fonction ROW_NUMBER est appliquée.Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression spécifie la colonne par laquelle le jeu de résultats est partitionné.value_expression specifies the column by which the result set is partitioned. Si n’est pas spécifié, la fonction traite toutes les lignes du jeu de résultats de la requête comme un seul groupe.If is not specified, the function treats all rows of the query result set as a single group. Pour plus d’informations, consultez Clause OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
order_by_clauseorder_by_clauseLa clause détermine la séquence dans laquelle les lignes d’une partition spécifique reçoivent leur valeur unique.The clause determines the sequence in which the rows are assigned their unique within a specified partition. Elle est obligatoire.It is required. Pour plus d’informations, consultez Clause OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
XML Functions
The XML functions operate on or return XML documents or fragments. These functions use arguments that are not defined as part of the ANSI/ISO/IEC SQL Standard but are defined as part of the World Wide Web Consortium (W3C) standards. The processing and operations that the functions perform are defined by the relevant W3C standards. The table below provides a link to the appropriate section of the W3C standard for the rules and guidelines that apply to each of these XML-related arguments. A SQL statement that uses one of these XML functions, where any of the arguments does not conform to the relevant W3C syntax, will result in an error. Of special note is the fact that not every character that is allowed in the value of a database column is considered legal in XML.
For more information about selecting and querying XML data using these functions, including information on formatting output, refer to .
The SQL XML functions are:
SQL ROW_NUMBER() Function Overview
The is a window function that assigns a sequential integer number to each row in the query’s result set.
The following illustrates the syntax of the function:
In this syntax,
- First, the clause divides the result set returned from the clause into partitions. The clause is optional. If you omit it, the whole result set is treated as a single partition.
- Then, the clause sorts the rows in each partition. Because the is an order sensitive function, the clause is required.
- Finally, each row in each partition is assigned a sequential integer number called a row number. The row number is reset whenever the partition boundary is crossed.
АргументыArguments
integer_expressioninteger_expressionЭто положительное целое выражение, указывающее число групп, на которые необходимо разделить каждую секцию.Is a positive integer expression that specifies the number of groups into which each partition must be divided. integer_expression может иметь тип int или bigint.integer_expression can be of type int, or bigint.
<partition_by_clause>Делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция.Divides the result set produced by the FROM clause into partitions to which the function is applied. Синтаксис PARTITION BY см. в статье Предложение OVER (Transact-SQL).For the PARTITION BY syntax, see OVER Clause (Transact-SQL).
<order_by_clause>Определяет порядок назначения значений функции NTILE строкам секции.Determines the order in which the NTILE values are assigned to the rows in a partition. Целое значение не может представлять столбец при использовании <order_by_clause> в ранжирующей функции.An integer cannot represent a column when the <order_by_clause> is used in a ranking function.
Comentários geraisGeneral Remarks
Não há nenhuma garantia de que as linhas retornadas por uma consulta que usa serão ordenadas exatamente da mesma maneira com cada execução, a menos que as condições a seguir sejam verdadeiras.There is no guarantee that the rows returned by a query using will be ordered exactly the same with each execution unless the following conditions are true.
-
Os valores da coluna particionada sejam exclusivos.Values of the partitioned column are unique.
-
Os valores das colunas são exclusivos.Values of the columns are unique.
-
As combinações de valores da coluna de partição e colunas são exclusivas.Combinations of values of the partition column and columns are unique.
é não determinístico. is nondeterministic. Para obter mais informações, veja Funções determinísticas e não determinísticas.For more information, see Deterministic and Nondeterministic Functions.
BeispieleExamples
A.A. Einfache BeispieleSimple examples
Die folgende Abfrage gibt vier Systemtabellen in alphabetischer Reihenfolge zurück.The following query returns the four system tables in alphabetic order.
Hier ist das Resultset.Here is the result set.
| namename | recovery_model_descrecovery_model_desc |
|---|---|
| mastermaster | SIMPLESIMPLE |
| modelmodel | FULLFULL |
| msdbmsdb | SIMPLESIMPLE |
| tempdbtempdb | SIMPLESIMPLE |
Fügen Sie mit der -Funktion eine Spalte namens (in diesem Fall) hinzu, um eine Spalte für Zeilennummern vor jeder Zeile hinzuzufügen.To add a row number column in front of each row, add a column with the function, in this case named . Sie müssen die -Klausel bis zur -Klausel verschieben.You must move the clause up to the clause.
Hier ist das Resultset.Here is the result set.
| Row#Row# | namename | recovery_model_descrecovery_model_desc |
|---|---|---|
| 11 | mastermaster | SIMPLESIMPLE |
| 22 | modelmodel | FULLFULL |
| 33 | msdbmsdb | SIMPLESIMPLE |
| 44 | tempdbtempdb | SIMPLESIMPLE |
Durch das Hinzufügen einer -Klausel zur -Spalte wird die Nummerierung neu gestartet, wenn der -Wert sich verändert.Adding a clause on the column, will restart the numbering when the value changes.
Hier ist das Resultset.Here is the result set.
| Row#Row# | namename | recovery_model_descrecovery_model_desc |
|---|---|---|
| 11 | modelmodel | FULLFULL |
| 11 | mastermaster | SIMPLESIMPLE |
| 22 | msdbmsdb | SIMPLESIMPLE |
| 33 | tempdbtempdb | SIMPLESIMPLE |
Im folgenden Beispiel wird eine Zeilennummer für die Vertriebsmitarbeiter in Adventure Works CyclesAdventure Works Cycles auf Grundlage der Verkaufszahlen des laufenden Jahres berechnet.The following example calculates a row number for the salespeople in Adventure Works CyclesAdventure Works Cycles based on their year-to-date sales ranking.
Hier ist das Resultset.Here is the result set.
C.C. Zurückgeben einer Teilmenge von ZeilenReturning a subset of rows
Im folgenden Beispiel werden Zeilennummern für alle Zeilen in der -Tabelle in der Reihenfolge des berechnet und nur die Zeilen bis (einschließlich) zurückgegeben.The following example calculates row numbers for all rows in the table in the order of the and returns only rows to inclusive.
D:D. Verwenden von ROW_NUMBER () mit PARTITIONUsing ROW_NUMBER() with PARTITION
Im folgenden Beispiel wird das Argument zum Partitionieren des Abfrageresultset nach der Spalte verwendet.The following example uses the argument to partition the query result set by the column . Durch die -Klausel in der -Klausel werden die Zeilen in jeder Partition nach der Spalte sortiert.The clause specified in the clause orders the rows in each partition by the column . Die -Klausel in der -Anweisung sortiert das gesamte Abfrageresultset nach .The clause in the statement orders the entire query result set by .
Hier ist das Resultset.Here is the result set.
RemarksRemarks
Инструкции Transact-SQLTransact-SQL могут устанавливать значение в @@ROWCOUNT указанными ниже способами.Transact-SQLTransact-SQL statements can set the value in @@ROWCOUNT in the following ways:
-
Установка значения @@ROWCOUNT в число считанных или измененных строк.Set @@ROWCOUNT to the number of rows affected or read. Строки могут быть отосланы или не отосланы клиенту.Rows may or may not be sent to the client.
-
Сохранение значения @@ROWCOUNT из предыдущего выполнения инструкции.Preserve @@ROWCOUNT from the previous statement execution.
-
Сброс значения @@ROWCOUNT в 0 без возврата значения клиенту.Reset @@ROWCOUNT to 0 but do not return the value to the client.
Инструкции, которые выполняют простые присваивания, всегда устанавливают значение @@ROWCOUNT равным 1.Statements that make a simple assignment always set the @@ROWCOUNT value to 1. Строки не отправляются клиенту.No rows are sent to the client. Примерами таких инструкций являются: SET @локальная_переменная, RETURN, READTEXT и инструкции SELECT без запроса, такие как SELECT GETDATE() или SELECT ‘Обычный текст’ .Examples of these statements are: SET @local_variable, RETURN, READTEXT, and select without query statements such as SELECT GETDATE() or SELECT ‘Generic Text’.
Инструкции, которые осуществляют присвоение в запросе или используют RETURN, устанавливают значение функции @@ROWCOUNT в число строк, задействованных или считанных запросом, например SELECT @локальная_переменная = c1 FROM t1.Statements that make an assignment in a query or use RETURN in a query set the @@ROWCOUNT value to the number of rows affected or read by the query, for example: SELECT @local_variable = c1 FROM t1.
Инструкции языка обработки данных DML задают значение @@ROWCOUNT равным числу строк, задействованных в запросе, и возвращают это значение клиенту.Data manipulation language (DML) statements set the @@ROWCOUNT value to the number of rows affected by the query and return that value to the client. DML-инструкции могут не отправлять строки клиенту.The DML statements may not send any rows to the client.
Инструкции DECLARE CURSOR и FETCH задают значение @@ROWCOUNT равным 1.DECLARE CURSOR and FETCH set the @@ROWCOUNT value to 1.
Инструкции EXECUTE сохраняют предыдущее значение @@ROWCOUNT.EXECUTE statements preserve the previous @@ROWCOUNT.
Такие инструкции, как USE, SET <option>, DEALLOCATE CURSOR, CLOSE CURSOR, PRINT, RAISERROR, BEGIN TRANSACTION или COMMIT TRANSACTION, сбрасывают значение ROWCOUNT в 0.Statements such as USE, SET <option>, DEALLOCATE CURSOR, CLOSE CURSOR, PRINT, RAISERROR, BEGIN TRANSACTION, or COMMIT TRANSACTION reset the ROWCOUNT value to 0.
Скомпилированные в собственном коде хранимые процедуры сохраняют предыдущее значение @@ROWCOUNT.Natively compiled stored procedures preserve the previous @@ROWCOUNT. Инструкции Transact-SQLTransact-SQL, находящиеся внутри скомпилированных в собственном коде хранимых процедур, не устанавливают значение @@ROWCOUNT.Transact-SQLTransact-SQL statements inside natively compiled stored procedures do not set @@ROWCOUNT. Дополнительные сведения см. в статье Хранимые процедуры, скомпилированные в собственном коде.For more information, see Natively Compiled Stored Procedures.
Отправляйте сообщения в WhatsApp голосом через ассистент Siri
Несколько версий iOS тому назад голосовой ассистент Siri научился работать со сторонними приложениями. И в WhatsApp практически сразу появилась возможность отправлять голосовые сообщения голосом.
Тем не менее, работало это только с одиночными диалогами, и это многих ставило в тупик. Про групповые чаты просто забыли.
Не прошло и пары лет, а в последних обновлениях мессенджера появилась возможность отправки сообщений в групповые чаты голосом. Для этого активируйте Siri, надиктуйте сообщение и попросите отправить по названию чата.
Это значительно упрощает общение с групповыми диалогами, когда вы стеснены в движениях.
Например, с помощью этой возможности вы можете общаться с друзьями и коллегами, когда едете за рулем. Достаточно сказать «Привет, Siri» и надиктовать сообщение. Еще проще делать это с помощью AirPods.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders

Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders

Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG или LEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders

Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders

Функция NTILE
Эта функция позволяет разбивать строки в секции окна на примерно равные по размеру подгруппы (tiles) в соответствии с заданным числом подгрупп и упорядочением окна. Допустим, что нужно разбить строки представления OrderValues на 10 подгрупп одинакового размера на основе упорядочения по val. В представлении 830 строк, поэтому требуется 10 подгрупп, размер каждой будет составлять 83 (830 деленное на 10). Поэтому первым 83 строкам (одной десятой части), упорядоченным по val, будет назначен номер группы 1, следующим 83 строкам — номер подгруппы 2 и т. д. Вот запрос, вычисляющий номера как строк, так и подгрупп:

Если вы думаете, что разбиение на подгруппы похоже на разбиение на страницы, хочу вас предупредить, что не стоит их путать. При разбиении на страницы, размер страницы является константой, а число страниц меняется динамически — оно определяется делением числа строк в результате запроса на размер страницы. При разбиении на подгруппы число подгрупп является константой, а размер подгруппы меняется и определяется как число строк деленное на заданное число подгрупп. Ясно, для чего нужно разбиение на страницы, а разбиение на подгруппы обычно используется для аналитических задач — когда нужно распределить данные среди заданного числа равных по размеру сегментов с использованием упорядочения по определенному измерению.
Но вернемся к результату запроса, вычисляющего номера как строк, так и подгрупп: как видите они тесно связаны друг с другом. По сути, можно считать, что номер подгруппы вычисляется на основе номера строки. В предыдущем разделе мы говорили, что если упорядочение окна не является уникальным, функция ROW_NUMBER является недетерминистической. Если разбиение на подгруппы принципиально основано на номерах строк, то это означает, что вычисление NTILE также недетерминистично, если упорядочение окна не уникально. Это означает, что у данного запроса может быть несколько правильных результатов. Можно посмотреть на это с другой стороны: двум строкам с одним значением упорядочения могут быть назначены разные номера подгрупп. Если нужен гарантированный детерминизм, можно следовать моим рекомендациям по получению детерминистических номеров строк, а именно добавить в упорядочение окна дополнительный параметр:
Теперь у запроса только один правильный результат. Ранее, при описании функции NTILE я пояснил, что она позволяет разбить строки в секции окна на примерно равные подгруппы. Я использовал слово «примерно», потому что число строк, полученное в базовом запросе, может не делиться нацело на число подгрупп. Допустим, вы хотите разбить строки представления OrderValues на 100 подгрупп. При делении 830 на 100 получаем частное 8 и остаток 30. Это означает, что базовая размерность подгрупп будет 8, но часть подгрупп получать дополнительную строку. Функция NTILE не пытается распределять дополнительные строки среди подгрупп с равным расстоянием между подгруппами — она просто добавляет по одному ряду в первые подгруппы, пока не распределит остаток. При наличии остатка 30 размерность первых 30 подгрупп будет на единицу больше базовой размерности. Поэтому первые 30 будут содержать 9 рядов, а последние 70 — 8, как показано в следующем запросе:
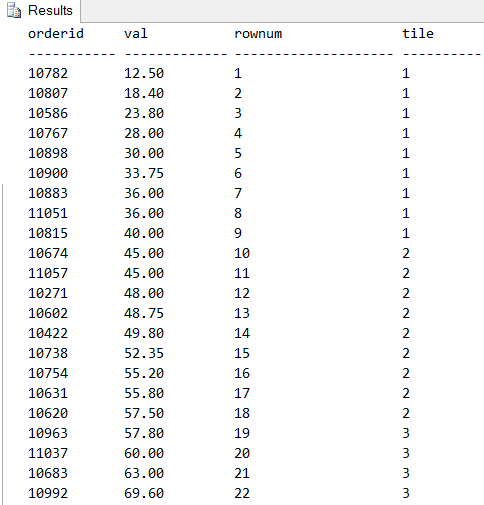
Следуя привычному методу, попытаемся создать альтернативные решения, заменяющие функцию NTILE и не содержащие оконных функций.
Я покажу один способ решения задачи. Для начала, вот код, который вычисляет число подгрупп по заданным размерности, числу подгрупп и числу строк:
Вычисление вполне очевидно. Для входных данных код возвращает 5 в качестве числа подгрупп.
Затем применим эту процедуру к строкам представления OrderValues. Используйте агрегат COUNT, чтобы получить размерность результирующего набора, а не входные данные @cnt, а также примените описанную ранее логику для вычисления номеров строк без использования оконных функций вместо входных данных @rownum:
Как обычно, не пытайтесь повторить это в производственной среде! Это пример предназначен для обучения, а его производительность в SQL Server ужасна по сравнению с функцией NTILE.
SQL ROW_NUMBER() examples
We will use the and tables from the sample database for the demonstration:
A) Simple SQL example
The following statement finds the first name, last name, and salary of all employees. In addition, it uses the function to add sequential integer number to each row.
The following picture shows the partial result set:
B) Using SQL for pagination
The function can be used for pagination. For example, if you want to display all employees on a table in an application by pages, which each page has ten records.
- First, use the function to assign each row a sequential integer number.
- Second, filter rows by requested page. For example, the first page has the rows starting from one to 9, and the second page has the rows starting from 11 to 20, and so on.
The following statement returns the records of the second page, each page has ten records.
The following shows the output:
If you want to use the common table expression (CTE) instead of the subquery, here is the query:
C) Using SQL for finding nth highest value per group
The following example shows you how to find the employees whose have the highest salary in their departments:
In the subquery:
- First, the clause distributes the employees by departments.
- Second, the clause sorts the employee in each department by salary in the descending order.
- Third, the assigns each row a sequential integer number. It resets the number when the department changes.
The following shows the result set of the subquery:
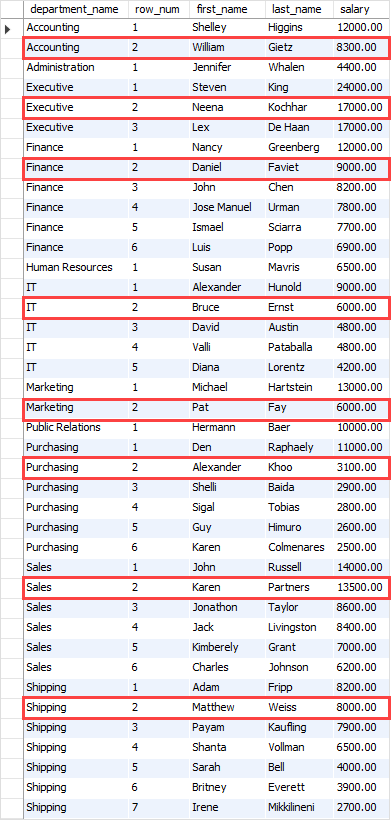
In the outer query, we selected only the employee rows which have the with the value 1.
Here is the output of the whole query:
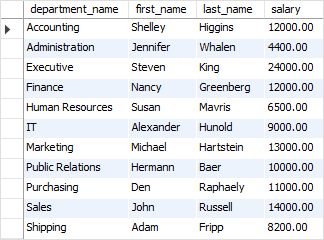
If you change the predicate in the clause from 1 to 2, 3, and so on, you will get the employees who have the second highest salary, third highest salary, and so on.
In this tutorial, you have learned how to use the SQL function to assign a sequential integer number to each row in the result set of a query.
- Was this tutorial helpful ?
示例Examples
A.A. 简单示例Simple examples
以下查询按字母顺序返回四个系统表。The following query returns the four system tables in alphabetic order.
下面是结果集:Here is the result set.
| namename | recovery_model_descrecovery_model_desc |
|---|---|
| 主master | SIMPLESIMPLE |
| 模型model | FULLFULL |
| msdbmsdb | SIMPLESIMPLE |
| tempdbtempdb | SIMPLESIMPLE |
要在每行的前面添加一个行编号列,请使用 函数添加一个列(此示例中名为 )。To add a row number column in front of each row, add a column with the function, in this case named . 必须将 子句向前移动到 子句处。You must move the clause up to the clause.
下面是结果集:Here is the result set.
| Row#Row# | namename | recovery_model_descrecovery_model_desc |
|---|---|---|
| 11 | 主master | SIMPLESIMPLE |
| 22 | 模型model | FULLFULL |
| 33 | msdbmsdb | SIMPLESIMPLE |
| 44 | tempdbtempdb | SIMPLESIMPLE |
若是在 列上添加 子句,当 值发生更改时将重新开始编号。Adding a clause on the column, will restart the numbering when the value changes.
下面是结果集:Here is the result set.
| Row#Row# | namename | recovery_model_descrecovery_model_desc |
|---|---|---|
| 11 | 模型model | FULLFULL |
| 11 | 主master | SIMPLESIMPLE |
| 22 | msdbmsdb | SIMPLESIMPLE |
| 33 | tempdbtempdb | SIMPLESIMPLE |
B.B. 返回销售人员的行号Returning the row number for salespeople
以下示例根据销售人员年初至今的销售额,计算 Adventure Works CyclesAdventure Works Cycles 中销售人员的行号。The following example calculates a row number for the salespeople in Adventure Works CyclesAdventure Works Cycles based on their year-to-date sales ranking.
下面是结果集:Here is the result set.
C.C. 返回行的子集Returning a subset of rows
下面的示例按 的顺序计算 表中所有行的行号,并只返回行 到 (含)。The following example calculates row numbers for all rows in the table in the order of the and returns only rows to inclusive.
D.D. 将 ROW_NUMBER () 与 PARTITION 一起使用Using ROW_NUMBER() with PARTITION
以下示例使用 参数按列 对结果集进行分区。The following example uses the argument to partition the query result set by the column . 在 子句中指定的 子句按列 对每个分区中的行进行排序。The clause specified in the clause orders the rows in each partition by the column . 语句中的 按 子句对整个查询结果集进行排序。The clause in the statement orders the entire query result set by .
下面是结果集:Here is the result set.
Osservazioni generaliGeneral Remarks
Non esiste alcuna garanzia che le righe restituite da una query che usa vengano ordinate esattamente allo stesso modo a ogni esecuzione, a meno che le condizioni seguenti non siano vere.There is no guarantee that the rows returned by a query using will be ordered exactly the same with each execution unless the following conditions are true.
-
Univocità dei valori della colonna partizionata.Values of the partitioned column are unique.
-
Univocità dei valori delle colonne .Values of the columns are unique.
-
Univocità delle combinazioni di valori della colonna di partizione e delle colonne .Combinations of values of the partition column and columns are unique.
è non deterministico. is nondeterministic. Per altre informazioni, vedere Funzioni deterministiche e non deterministiche.For more information, see Deterministic and Nondeterministic Functions.
ПримерыExamples
A.A. Простые примерыSimple examples
Приведенный ниже запрос возвращает четыре системные таблицы в алфавитном порядке.The following query returns the four system tables in alphabetic order.
Результирующий набор:Here is the result set.
| namename | recovery_model_descrecovery_model_desc |
|---|---|
| mastermaster | ПРОСТОЙSIMPLE |
| modelmodel | FULLFULL |
| msdbmsdb | ПРОСТОЙSIMPLE |
| tempdbtempdb | ПРОСТОЙSIMPLE |
Чтобы добавить столбец с номерами строк перед каждой строкой, добавьте столбец с помощью функции , в данном случае с именем .To add a row number column in front of each row, add a column with the function, in this case named . Предложение необходимо переместить к предложению .You must move the clause up to the clause.
Результирующий набор:Here is the result set.
| Номер строкиRow# | namename | recovery_model_descrecovery_model_desc |
|---|---|---|
| 11 | mastermaster | ПРОСТОЙSIMPLE |
| 22 | modelmodel | FULLFULL |
| 33 | msdbmsdb | ПРОСТОЙSIMPLE |
| 44 | tempdbtempdb | ПРОСТОЙSIMPLE |
Добавление предложения для столбца приведет к тому, что нумерация начнется заново при изменении значения .Adding a clause on the column, will restart the numbering when the value changes.
Результирующий набор:Here is the result set.
| Номер строкиRow# | namename | recovery_model_descrecovery_model_desc |
|---|---|---|
| 11 | modelmodel | FULLFULL |
| 11 | mastermaster | ПРОСТОЙSIMPLE |
| 22 | msdbmsdb | ПРОСТОЙSIMPLE |
| 33 | tempdbtempdb | ПРОСТОЙSIMPLE |
Б.B. Возврат номера строки для salespeopleReturning the row number for salespeople
В следующем примере показан расчет номера строки для salespeople в Компания Adventure Works CyclesAdventure Works Cycles, выполняемый на основе ранжирования продаж за текущий год.The following example calculates a row number for the salespeople in Компания Adventure Works CyclesAdventure Works Cycles based on their year-to-date sales ranking.
Результирующий набор:Here is the result set.
В.C. Возврат подмножества строкReturning a subset of rows
В следующем примере показан расчет номеров всех строк в таблице в порядке с последующим возвращением строк с номерами от до включительно.The following example calculates row numbers for all rows in the table in the order of the and returns only rows to inclusive.
Г.D. Использование ROW_NUMBER() с PARTITIONUsing ROW_NUMBER() with PARTITION
В следующем примере аргумент используется для секционирования результирующего набора запроса по столбцу .The following example uses the argument to partition the query result set by the column . Предложение , указанное в предложении , упорядочивает строки каждой секции по столбцу .The clause specified in the clause orders the rows in each partition by the column . Предложение в инструкции упорядочивает полный результирующий набор запроса по .The clause in the statement orders the entire query result set by .
Результирующий набор:Here is the result set.