Все о файле «robots.txt» по-русски
Содержание:
- Разблокировка Flash Player в Гугл Хром
- Немного теории перед подключением роутера
- Описание robots.txt
- Принцип работы поисковых роботов и их функции
- Операторы в robots.txt
- Проверка robots.txt в Яндекс и Гугл вебмастере
- Robots.txt для WordPress
- Последние материалы из раздела «Автотовары»
- Поддерживаемые Google строки вне групп
- Практическая реализация заголовка X-Robots-Tag
- Для чего нужна проверка robots.txt
- Директивы robots.txt
Разблокировка Flash Player в Гугл Хром
Немного теории перед подключением роутера
Маршрутизатор (он же роутер) – это прибор, имеющий отдельную флэш-память, в которой размещена индивидуальная операционная система. По этой причине при подключении он не будет отображён компьютером в диспетчере устройств.
Беспроводные вай-фай маршрутизаторы от Ростелеком могут функционировать благодаря наличию основного устройства (например, домашнего компьютера). При этом используется специальная SIM-карта от Ростелеком, по которой в соответствии с выбранным и оплаченным тарифом будет передаваться определённый объём интернет-трафика.
Маршрутизатор начинает функционировать только после подключения к питанию (аккумулятору, электросети). Первичная настройка при подключении WiFi роутера Ростелеком к принимающему устройству осуществляется при помощи кабеля. Прежде всего, потребуется убедиться в стабильной работе интернета. Далее можно заняться настройкой беспроводного подключения.
Подключённый к питанию маршрутизатор сразу же начинает осуществлять раздачу собственного сигнала. Даже при отсутствии сетевого кабельного соединения на панели устройства светится вай-фай индикатор. Наименование включённого оборудования отображается в перечне доступных сетей на расположенных в пределах квартиры (дома) мобильных или планшетах.
Однако неправильная настройка или неверное подключение вай-фай роутера Ростелеком могут воспрепятствовать нормальной работе интернета.
Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots.txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots.txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
| URL Сайта | URL файла robots.txt |
| http://www.w3.org/ | http://www.w3.org/robots.txt |
| http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
| http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
| http://w3.org/ | http://w3.org/robots.txt |
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
| Неправильное расположение robots.txt | |
| http://www.w3.org/admin/robots.txt | Файл находится не в корне сайта |
| http://www.w3.org/~timbl/robots.txt | Файл находится не в корне сайта |
| ftp://ftp.w3.com/robots.txt | Роботы не индексируют ftp |
| http://www.w3.org/Robots.txt | Название файла не в нижнем регистре |
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
Либо вы можете запретить все запрещенные к индексации файлы:
Принцип работы поисковых роботов и их функции
Поисковая выдача формируется в три этапа:
- Сканирование — сбор всех данных с веб-страниц ботами, включая тексты, картинки и видеоматериалы. Данный процесс происходит регулярно с учётом частоты обновлений ресурса.
- Индексация — внесение собранной информации в базу данных поисковых систем с присвоением определённого индекса для быстрого поиска. На крупных новостных порталах контент индексируется практически сразу после публикации.
- Выдача результатов — поиск информации по индексу и ранжирование страниц с учётом релевантности запросу.
Иногда процесс индексации страниц происходит даже без их предварительного сканирования. В файле robots.txt указываются правила для сканирования, но не индексирования страниц. Поэтому если поисковый робот обнаружит страницу другим способом, например, если на неё ссылаются сторонние ресурсы, то может добавить её в базу.
В данном случае необходимо убрать запрет на сканирование этих служебных страниц из файла robots.txt, используя только запрет индексации на страницах:
<meta name=»robots» content=»noindex» />
2.1. Рекомендации роботам по доступу к контенту сайта
Рекомендации по индексации материалов на сайте можно задавать с помощью файлов sitemap.xml и robots.txt:
В sitemap.xml можно указать частоту обновления и приоритет каждой страницы, используя теги и . Частоту обновления задают в зависимости от типа ресурса и страницы — от новостных ресурсов до статичных страниц, например, раздела с контактами компании
Приоритет страницы устанавливается в зависимости от её важности для продвижения — от 0,0 до 1,0.
В robots.txt указываются правила сканирования страниц. Для SEO-продвижения важно, чтобы в индекс не попадали служебные страницы, дубли и другой малополезный контент
Однако вопреки указанным директивам, краулеры могут всё равно проиндексировать закрытые страницы. Если на сайте необходимо гарантированно запретить индексацию каких-либо материалов, лучше использовать метатег robots или делать их доступными для пользователей после аутентификации.
В robots.txt для запрета индексации используется директива Disallow. Например, чтобы полностью запретить доступ всех ботов к сайту, прописываются такие строчки кода:
User-agent: *
Disallow:
При добавлении директив их порядок не принципиален, после данной команды можно открыть какой-либо раздел сайта для индексации при помощи директивы Allow.
Операторы в robots.txt
Прежде, чем мы перейдём к обзору директив, ознакомимся с дополнительными операторами. Про символ # мы поговорили выше. Кроме него вам могут потребоваться следующие операторы:
* сообщает, что допускается любое число символов или таковые отсутствуют;
$ поясняет, что находящийся перед ним символ является последним.
Директива User-agent
Адресует ваши команды определённому боту-поисковику. Именно с неё вы начинаете прописывать robots.txt.
(правила задаются для всех роботов Яндекса)
(правила задаются для всех роботов Google)
(правила задаются для всех поисковых систем)
Обращаю ваше внимание: когда поисковой робот обнаруживает своё имя после User-agent, то он не воспринимает все команды, которые вы зададите в блоке User-agent: *. И ещё, у отдельных поисковых систем существует целая группа ботов, команды для которых можно задавать в индивидуальном порядке
При этом блоки с рекомендациями для таких ботов разбиваются путём оставления пустой строки.
Поисковые роботы Google:
Googlebot – основной бот системы;
Googlebot-Image – обрабатывает изображения;
Googlebot-Video – отслеживает видео-контент;
Googlebot-Mobile – работает со страницами для мобильных девайсов;
Adsbot-Google – анализирует качество рекламы на веб-страницах для персональных компьютеров;
Googlebot-News – определяет веб-страницы, которые следует внести в Новости Google.
Поисковые роботы Yandex:
YandexBot – основной бот системы;
YandexImages – обрабатывает изображения;
YandexNews – определяет веб-страницы для добавления в Яндекс.Новости;
YandexMedia – отслеживает мультимедиа контент;
YandexMobileBot – работает со страницами для мобильных девайсов.
Директива Disallow
Самая популярная команда – выдаёт запрет на индексацию страниц.
Примеры:
(закрытие доступа ко всему веб-ресурсу)
(закрытие доступа к панели администратора)
(закрытие доступа на обработку документов заданного типа)
Директива Allow
Даёт право обрабатывать поисковикам заданные вами веб-страницы. Это особенно актуально в процессе ведения техработ на сайте. Например, вы модернизируете веб-ресурс, но каталог с товарами не подлежит изменениям. Вы закрываете доступ к своему сайту, а ботов направляете только к нужному вам разделу.
Пример:
Директива Host
До недавнего времени применялась для показа роботам Яндекса основного зеркала веб-сайта – с www или без. Весной 2018 г. российская ИТ-компания проинформировала пользователей, что директива заменяется на редирект 301 – универсальный метод для всех работающих поисковиков, который указывает на основной сайт.
На сегодняшний день эта команда бесполезна. Но если она проставлена в файле, то ничего страшного – поисковые боты её просто игнорируют.
Директива Sitemap
Предназначена для указания пути к Карте вашего ресурса. По-хорошему, sitemap.xml должен храниться в корне веб-сайта. В случае, когда путь отличается, эта команда позволяет найти поисковикам Карту.
Директива Clean-param
Её задача – пояснить боту, что нет необходимости в индексировании страницы с определёнными параметрами. Это относится к динамическим ссылкам, ведь они периодически формируются в ходе работы веб-сайта и образуют дубли – то есть одинаковая страница становится доступна на нескольких адресах. Тогда применяется «ref» – параметр, позволяющий выявить источник ссылки.
Пример:
Результат:
Таким образом поисковик сведёт все URL к одной странице. Она будет участвовать в поисковой выдаче при условии её наличия на веб-сайте:
Директива Crawl-Delay
Команда предназначена, чтобы уведомить бота-поисковика о продолжительности загрузки страницы (в секундах). Она позволяет снизить нагрузку на веб-ресурс. Это актуально, когда веб-сайт размещён на слабом сервере.
Выглядит это так:
(вы уведомили поисковика, что можно скачивать данные каждые 3.5 секунд)
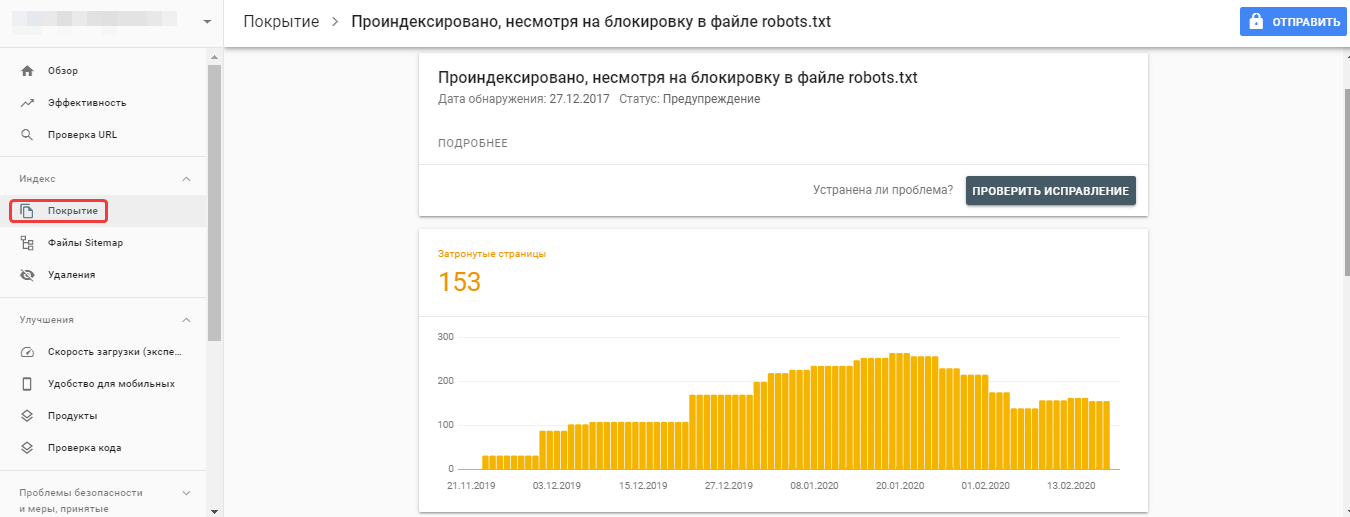
Проверка robots.txt в Яндекс и Гугл вебмастере
Как я уже упоминал, разные поисковые системы некоторые директивы могут интерпритировать по разному. Поэтому имеет смысл проверять написанный вами файл роботс.тхт в панелях для вебмастеров обоих систем. Как проверять?
- Зайти в инструменты проверки Яндекса и Гугла.
-
Убедиться, что в панель вебмастера загружена версия файла с внесенными вами изменениями. В Яндекс вебмастере загрузить измененный файл можно с помощью показанной на скриншоте иконки:
В Гугл Вебмастере нужно нажать кнопку «Отправить» (справа под списком директив роботса), а затем в открывшемся окне выбрать последний вариант нажатием опять же на кнопку «Отправить»:
-
Набрать список адресов страниц своего сайта (по Урлу в строке), которые должны индексироваться, и вставить их скопом (в Яндексе) или по одному (в Гугле) в расположенную снизу форму. После чего нажать на кнопку «Проверить».
Если возникли нестыковки, то выяснить причины, внести изменения в robots.txt, загрузить обновленный файл в панель вебмастеров и повторить проверку. Все ОК?
Тогда составляйте список страниц, которые не должны индексироваться, и проводите их проверку. При необходимости вносите изменения и проверку повторяйте. Естественно, что проверять следует не все страницы сайта, а ярких представителей своего класса (страницы статей, рубрики, служебные страницы, файлы картинок, файлы шаблона, файлы движка и т.д.)
Причины ошибок выявляемых при проверке файла роботс.тхт
- Файл должен находиться в корне сайта, а не в какой-то папке (это не .htaccess, и его действия распространяются на весь сайт, а не на каталог, в котором его поместили), ибо поисковый робот его там искать не будет.
- Название и расширение файла robots.txt должно быть набрано в нижнем регистре (маленькими) латинскими буквами.
- В названии файла должна быть буква S на конце (не robot.txt, как многие пишут)
- Часто в User-agent вместо звездочки (означает, что этот блок robots.txt адресован всем ботам) оставляют пустое поле. Это не правильно и * в этом случае обязательна
User-agent: * Disallow: /
- В одной директиве Disallow или Allow можно прописывать только одно условие на запрет индексации директории или файла. Так нельзя:
Disallow: /feed/ /tag/ /trackback/
Для каждого условия нужно добавить свое Disallow:
Disallow: /feed/ Disallow: /tag/ Disallow: /trackback/
- Довольно часто путают значения для директив и пишут:
User-agent: / Disallow: Yandex
вместо
User-agent: Yandex Disallow: /
- Порядок следования Disallow (Allow) не важен — главное, чтобы была четкая логическая цепь
- Пустая директива Disallow означает то же, что «Allow: /»
- Нет смысла прописывать директиву sitemap под каждым User-agent, если будете указывать путь до карты сайта (читайте об этом ниже), то делайте это один раз, например, в самом конце.
- Директиву Host лучше писать под отдельным «User-agent: Yandex», чтобы не смущать ботов ее не поддерживающих
Robots.txt для WordPress
Для создания файла нам нужно точно так же забросить robots.txt в корень сайта. Изменять его содержимое в таком случае можно будет с помощью все тех же FTP и файловых менеджеров.
Есть и более удобный вариант – создать файл с помощью плагинов. В частности, такая функция есть у Yoast SEO. Править роботс прямо из админки куда удобнее, поэтому сам я использую именно такой способ работы с robots.txt.
Как вы решите создать этот файл – дело ваше, нам важнее понять, какие именно директивы там должны быть. На своих сайтах под управлением WordPress использую такой вариант:
User-agent: * # правила для всех роботов, за исключением Гугла и Яндекса
Disallow: /cgi-bin # папка со скриптами
Disallow: /? # параметры запросов с домашней страницы
Disallow: /wp- # файлы самой CSM (с приставкой wp-)
Disallow: *?s= # \
Disallow: *&s= # все, что связано с поиском
Disallow: /search/ # /
Disallow: /author/ # архивы авторов
Disallow: /users/ # и пользователей
Disallow: */trackback # уведомления от WP о том, что на вас кто-то ссылается
Disallow: */feed # фид в xml
Disallow: */rss # и rss
Disallow: */embed # встроенные элементы
Disallow: /xmlrpc.php # WordPress API
Disallow: *utm= # UTM-метки
Disallow: *openstat= # Openstat-метки
Disallow: /tag/ # тэги (при наличии)
Allow: */uploads # открываем загрузки (картинки и т. д.)
User-agent: GoogleBot # для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js # открываем JS-файлы
Allow: /*/*.css # и CSS
Allow: /wp-*.png # и картинки в формате png
Allow: /wp-*.jpg # \
Allow: /wp-*.jpeg # и в других форматах
Allow: /wp-*.gif # /
Allow: /wp-admin/admin-ajax.php # работает вместе с плагинами
User-agent: Yandex # для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # чистим UTM-метки
Clean-Param: openstat # и про Openstat не забываем
Sitemap: # прописываем путь до карты сайта
Host: https://site.ru # главное зеркало
Внимание! При копировании строк в файл – не забудьте удалить все комментарии (текст после #). Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP
Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее
Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP. Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее.
Последние материалы из раздела «Автотовары»
Поддерживаемые Google строки вне групп
Практическая реализация заголовка X-Robots-Tag
Заголовок можно добавить в HTTP-ответы с помощью файлов конфигурации в серверном ПО сайта. Например, на серверах Apache такие настройки хранятся в файлах .HTACCESS и HTTPD.CONF. Преимущество использования заголовка в HTTP-ответах состоит в том, что с его помощью можно задать директивы сканирования на уровне всего сайта. А поддержка регулярных выражений обеспечивает дополнительную гибкость.
Например, чтобы добавить заголовок с директивой в HTTP-ответ для PDF-файлов со всего сайта, включите небольшой фрагмент кода в корневой файл .HTACCESS/HTTPD.CONF (Apache) или CONF (NGINX).
Apache:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
NGINX:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Заголовки можно использовать для тех файлов, для которых HTML-метатеги robots недоступны, например для изображений. В приведенном ниже примере директива добавляется для файлов изображений (PNG, JPEG, JPG, GIF) на всём сайте:
Apache:
<Files ~ "\.(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Files>
NGINX:
location ~* \.(png|jpe?g|gif)$ {
add_header X-Robots-Tag "noindex";
}
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Директивы robots.txt
Порядок включения директив:
|
<Директива><двоеточие><пробел><документ, к которому применяется директива> |
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent – указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс – Yandex (, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google – Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится – «*»
Disallow – директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
 Рис. 1 Директива Disallow
Рис. 1 Директива Disallow
Allow – директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
Стоит обратить внимание на : «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
 Рис. 2 Директива Allow
Рис. 2 Директива Allow
Sitemap – директива для указания пути к файлу xml-карты сайта.
Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
|
User-agent: * Sitemap: http://site.ru/sitemap-1.xml Sitemap: http://site.ru/sitemap-2.xml |
Спецсимволы
- * — означает любую последовательность символов. Добавляется по умолчанию к концу каждой директивы (красная стрелочка на рисунке 3).
- $ — используется для отмены знака «*» на конце директивы (синяя стрелочка на рисунке 3).
- # — знак описания комментариев. Все что указывается справа от этого знака не будет учитываться роботами.

Рис. 3 Спецсимволы
Host – директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
- Данная директива может склеить не только зеркала вида www.site.ru и site.ru но и другие сайты, в robots.txt которых указан соответствующий Host.
- Если зеркало доступно только по защищенному протоколу, указывается адрес с протоколом (https://site.ru). В других случаях протокол не указывается.
- Для настройки главного зеркала в поисковой системе Google используется функция «Настройки сайта» в Google Search Console.
Crawl-delay – директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
Clean-param – директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
 Рис. 4 Clean-param
Рис. 4 Clean-param