Все возможности яндекс вордстат
Содержание:
- LearnAtHome
- Как составить документ об отказе от страховки?
- LiveInternet – самые популярные запросы БЕСПЛАТНО
- Используем минус-слова для фильтрации нецелевых запросов
- Статистика поисковых запросов Mail.ru
- Проверка частотности в «Яндексе»
- Основные возможности Парсера Wordstat в PromoPult:
- Распределение кликабельности на первой странице выдачи
- Запрос что это значит
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Делаем буквицу
- Частотность запросов
- Виды частотности
- Операторы Яндекс.Вордстат
- Пошаговая инструкция по работе с Yandex Wordstat
- Заключение
LearnAtHome
Как составить документ об отказе от страховки?
LiveInternet – самые популярные запросы БЕСПЛАТНО
Воспользуемся для этого сервисом статистики Liveinternet. К сожалению, использование данных этого сервиса не даст на 100% совпадения с данными поисковых систем Яндекс или Гугл, так как не все сайты интернета используют счетчики посещаемости от ЛайвИнтернет и не все кто используют делают свою статистику открытой, но выборка там очень большая, поэтому, для реальной работы более чем достаточна. В конце концов, нам же нужен список, а точные цифры потом по Wordstat пробьем.
Полезная штука в Liveinternet – есть возможность сразу делать сортировку по категориям – копать поисковые запросы не по всему интернету, а в конкретной теме (хотя, можно и по всему интернету тоже).
Открываем сайт – liveinternet.ru
Если нам нужны данные по поисковым запросам общим по сети, то переходим сразу в рейтинг сайтов, если нужные ключевые фразы по определенной тематике, то выбираем одну из рубрик.
Для примера я выбрал группу компьютеры. Теперь нам нужна статистика группы – это такая ссылка с пиктограммой графика сверху списка сайтов в рейтинге
Обратите внимание, что мы можем уточнить страну и регион – для сайтов, которые имеют привязку к территории, нужны запросы популярные в заданной местности
В статистике мы увидим общие цифры посещаемости и много чего еще, но интересует нас левый столбец меню и, конкретно, пункт «По поисковым фразам».
Существенная доля запросов тут спрятана под кодовым названием «Другие», но пусть вас это не смущает, наиболее популярные открыты.
Чтобы выборку сделать максимально удобной в настройках итоговой таблицы выберите «По месяцам» и «Суммарные». Снизу можно настроить определенное число строк, одновременно выводимое на страницу (от 10 до 100).
Таким образом, мы получаем список наиболее популярных запросов в заданной категории. Не стоит удивляться, если среди запросов будут проскакивать не тематические – это происходит от того, что выборка идет не по реальным категориям запросов, а по сайтам, которые есть в рейтинге Liveinternet. И часто бывает так, что сайт ошибочно помещен не в ту категорию и его запросы учтены. Случается и так, что сайт тематический, но на нем есть страница с текстом другой тематики, которая дает ощутимый поисковый трафик, не относящийся к заданной категории.
Так что, самые популярные слова и словосочетания нужные вам надо будет отобрать руками.
Теперь мы можем расширить нашу выборку для подбора конкретных ключевых фраз под написание статей для своего сайта. Для этого берем список слов выписанных из Лайвинтернета и возвращаемся к любимому Яндекс Wordstat. Поочередно внося слова, мы получим более узкие значения популярных запросов, но, главное, в правой колонке мы найдем схожие по теме запросы, расширяющие нашу первоначальную выборку.
Используем минус-слова для фильтрации нецелевых запросов
При проверке фразы в Вордстате сервис покажет поисковые запросы, которые могут содержать нерелевантные слова. Такие слова желательно исключить, чтобы оценить чистый спрос на вашу услугу или товар.
Эту фразу пользователи ищут примерно 690 тысяч раз в месяц. При этом запросы с этой фразой иногда содержат слово «недорогой».
Если такой запрос для нас является нецелевым (например, вы продаете только геймерские ноутбуки с топовой начинкой), его лучше исключить из статистики.
Для этого используем минус-слова. Вводим в поисковую строку Вордстата запрос «купить ноутбук» и добавляем минус-слово «-недорогой». Жмем «Подобрать» и видим: количество запросов стало меньше, а в блоке «Что искали со словом» — нет результатов, содержащих слово «недорогой».
Также к основной фразе можно добавить несколько минус-слов, чтобы исключить другие нерелевантные запросы. Посмотрите запросы из левой и правой колонок, найдите слова или фразы, которые вам не подходят, и укажите их в качестве минус-слов.
На выходе вы получите чистые данные по релевантным запросам, что поможет качественно оценить спрос.
Какие группы слов часто используют в качестве минус-слов в контекстной рекламе:
- DIY-слова — «сделать», «своими руками», «самостоятельно» и т. д.;
- маркеры информационных запросов («почему», «как», «чем», «какой» и т. п.);
- слова «мусорного» спроса — «бесплатно», «giveaway», «в дар» и т. п.
- маркеры вторичного рынка — «бу», «подержанный»;
- характеристики или свойства продукта, которые не подходят для вашей кампании. Например, если вы продаете только мужские кроссовки, исключите из статистики слова «женские» и «детские».
Операторы поиска: уточняем статистику по запросам
С помощью операторов поиска можно уточнить запрос и посмотреть точную статистику показов по фразе в нужной форме или с определенным порядком слов. Использование операторов доступно в разделах «По словам» и «По регионам».
Кавычки » » (фиксация слов)
При указании запроса в кавычках вы увидите статистику только по указанному словосочетанию (без добавления других слов). При этом порядок слов и окончания могут меняться.
Восклицательный знак! (фиксация словоформы)
Используется для фиксации окончания в указанном виде и размещается перед словом, в котором его нужно зафиксировать.
Обратите внимание! Используйте оператор «кавычки» совместно с оператором «!». Так вы сможете узнать точную частотность любого запроса
Плюс + (фиксация стоп-слов)
Используется для проверки частотности по запросам, содержащим стоп-слова (служебные части речи, местоимения и др.). По умолчанию в Яндекс.Вордстате они не учитываются. Например, если мы введем в Вордстате фразу «двери для», сервис покажет статистику без учета предлога «для».
Сравните сами. По запросу «двери» сервис показывает 9 631 111 показов в месяц:
А вот статистика по запросу «двери для» (результат аналогичный):
А теперь фиксируем стоп-слово «для» и получаем уже 831 973 показов в месяц, а не 9 631 111.
Вертикальный слэш | (логический оператор «или»)
Применяется для объединения статистики по разным запросам. Например, если мы продаем входные двери, полезно узнать количество запросов от владельцев квартир и загородных домов. Для этого используем оператор | — вводим в Вордстате такую фразу:
В результатах подбора будет статистика по запросам, содержащим любое из словосочетаний, указанных в круглых скобках.
Квадратные скобки [] (фиксация порядка слов)
При использовании этого оператора система покажет статистику по запросам, в которых содержатся указанные слова в заданном порядке.
Использование [] поможет исключить запросы с иным порядком слов и зафиксировать нужный порядок слов
Это важно, например, если вы рекламируете продажу билетов по конкретным направлениям
Статистика поисковых запросов Mail.ru
Майл.ру обновил инструмент показывающий статистику поисковых запросов http://webmaster.mail.ru/querystat . Главная фишка сервиса — это распределение запросов по полу и возрасту.
Можно предположить, что сервис подбора слов Яндекса также учитывает запросы из Mail, т.к. в данный момент поисковая система Mail.ru показывает рекламу Яндекса, а сервис в основном рассчитан на рекламодателей. А раньше кстати, в Mail.ru показывалась реклама Google.
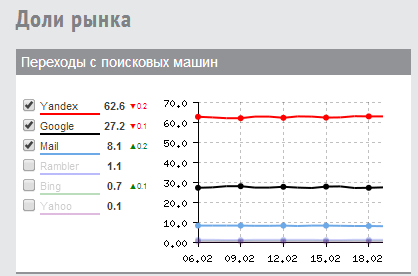
Кроме того, можно пользоваться такой хитростью. Примерное распределение аудитории между поисковиками такое: Яндекс — 60%, Гугл — 30%, Mail — 10%. Конечно, в зависимости от аудитории, соотношение может меняться. (Например, программисты могут отдавать предпочтение Google.)
Тогда можно посмотреть статистику в Яндекс и делить на 6. Получаем приблизительное количество поисковых запросов в Mail.ru
Кстати, точное распределение аудитории между поисковиками на Февраль 2014 года можно увидеть на скриншоте снизу:
Проверка частотности в «Яндексе»
Низкочастотные, высокочастотные и среднечастотные запросы рассчитываются на основании числа показов за месяц. Они не отражают точную статистику, но при продвижении ресурса их используют как грубое округление. Без точных показателей они разделяются таким образом: запрос в 100 показов – низкочастотный, более 5 тысяч – высокочастотный. Точно выявить среднечастотный запрос невозможно – каждый SEO-специалист определяет его самостоятельно для себя. В различных поисковых системах применяются разные сервисы проверки частотности. В «Яндексе» оценить интерес пользователей к конкретным тематикам помогает сервис WordStat. Для этого требуется ввести запрос. В качестве ответа предоставляется статистика по фразе и ее словоформам. Для уточнения применяются дополнительные операторы. Например, при заключении фразы во французские кавычки можно узнать частотность запроса, который состоит лишь из указанных слов, написанных в любой последовательности и форме.

Основные возможности Парсера Wordstat в PromoPult:
- массовая проверка частотностей из левой колонки Wordstat для указанных фраз;
- загрузка фраз списком или с помощью файла XLSX;
- возможность парсить частотность в любом регионе Яндекса;
- учет типа соответствия при парсинге (операторы «фраза
«, «!фраза
» и [фраза
]); - сохранение всех отчетов «в облаке».
Особенности сервиса:
- неограниченное количество поисковых запросов при проверке за один раз;
- сбор частотностей онлайн — не нужно устанавливать софт;
- не нужно создавать фейковые аккаунты в Яндексе специально для парсинга или рисковать собственными аккаунтами;
- не нужно использовать прокси-серверы и вводить капчу;
- суммирование в отчете частотностей по указанным регионам или разбивка по каждому региону;
- высокая скорость парсинга;
- удобный для последующей обработки отчет в формате XLSX.
Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
В общем-то да!
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
- ТОП-1: 15-35%
- ТОП-2: 10-25%
- ТОП-3: 7-20%
- ТОП-4: 5-15%
- ТОП-5 – ТОП-10: 3-12%
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR. Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Запрос что это значит
Запрос (поисковый/информационный) – слово или фраза, которая вводится в строку браузера с целью поиска нужной информации. Иначе говоря, это намерение пользователя с помощью поисковой системы найти ответ, максимально соответствующий его ожиданиям.
Но это существительное связано не только с интернет-технологиями. Слово имеет и другие значения:
- официальное обращение, содержащее требование или просьбу дать объяснения, сообщить какие-либо сведения;
- коммерческий документ – официальное обращение организации с предложением предоставить подробную информацию о товарах или услугах;
- намеренное назначение за что-либо цены более высокой, чем требуется.
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:

Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/

Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:

Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».

Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:

Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:

Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:

Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:

И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:

Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Делаем буквицу
Разобравшись, что это такое и как она выглядит в программе, можно переходить непосредственно к тому, как сделать буквицу в «Ворде». Итак, у нас есть текст, который разбит на главы. Перед пользователем стоит задача первую букву новой главы выделить, то есть сделать буквицу. Для этого:
- Установите курсор перед тем словом, из первой буквы которого нужно сделать буквицу.
- На панели инструментов перейдите на вкладку «Вставка».
- В области инструментов «Текст» нажмите по кнопке «Буквица».
- В появившемся дополнительном меню выберите тип буквицы, который вам подходит.

Всего есть два типа: «В тексте» и «На поле». О них было рассказано в начале этой статьи. Каждый тип озаглавлен иконкой, на которой продемонстрирован итоговый вид вставляемой буквицы. Кликните по понравившемуся расположению, и буквица будет установлена. Как можно заметить, делать ее не так уж и сложно, всего понадобилось четыре действия, чтобы справиться с поставленной задачей.
Частотность запросов
Прежде всего, снова определимся, как мы будем группировать запросы. Уже ни для кого не секрет, что выделяются низкочастотники (НЧ), среднечастотники (СЧ) и высокочастотники (ВЧ). Но как определить, к какой группе отнести запрос? Ранее я предложил такую схему:
- НЧ – до 700 запросов в месяц;
- СЧ – до 2000 запросов в месяц;
- ВЧ – все остальные.
Эта схема и сейчас справедлива, но применима она для сео-тематики.
В действительности же большинство сеошников руководствуются следующей схемой:
- до 1000 – низкочастотные;
- 1 – 10 тыс. – среднечастотники;
- свыше 10 тыс. – высокочастотники.
Эта формула также верна, но она считается общей. Если же вы работаете в конкурентных тематиках, где пробиться в ТОП поисковиков крайне сложно, то эти цифры снижаются.
Теперь вы понимаете, что частотность лучше определять в зависимости от того, к какой тематике принадлежит ваш ресурс.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.
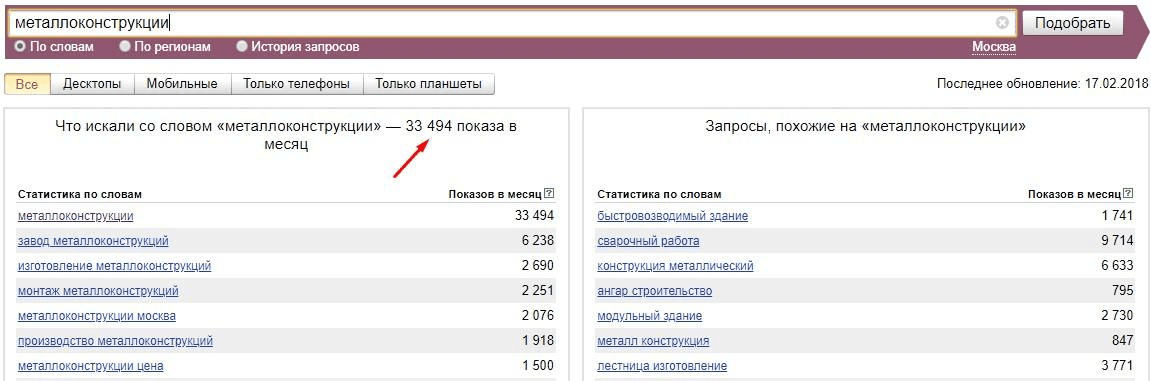
Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке. Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:

Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:

В многословных запросах восклицательный знак нужно ставить перед каждым словом, так как данный оператор фиксирует словоформу каждого слова запроса по отдельности.
Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить!металлоконструкции” и “!металлоконструкции!купить”, то обнаружим, что странным образом частотность у них будет одинаковая:
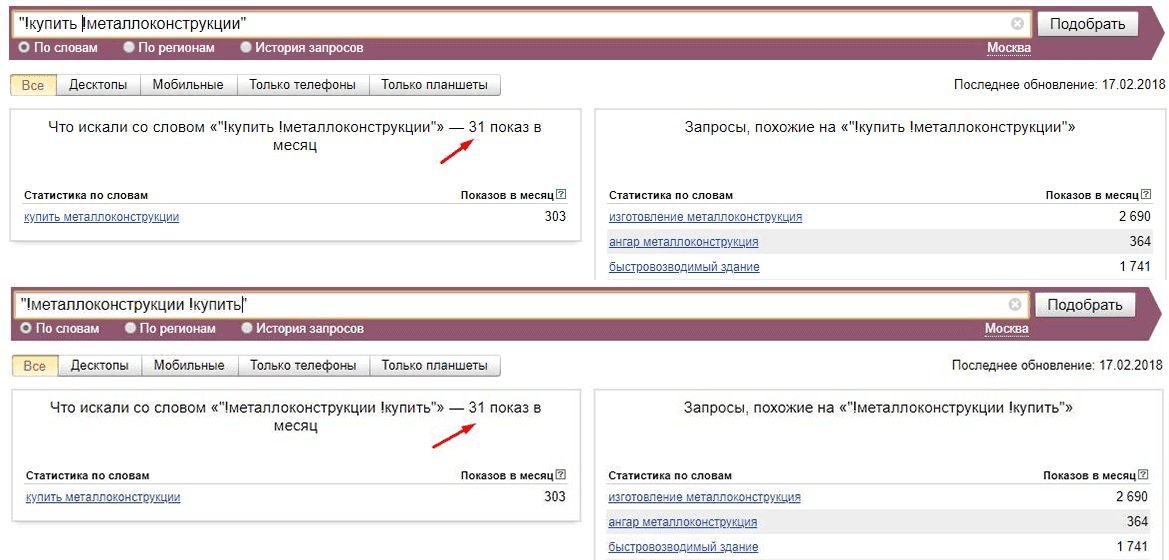
Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов.
Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “”:

Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона. В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».
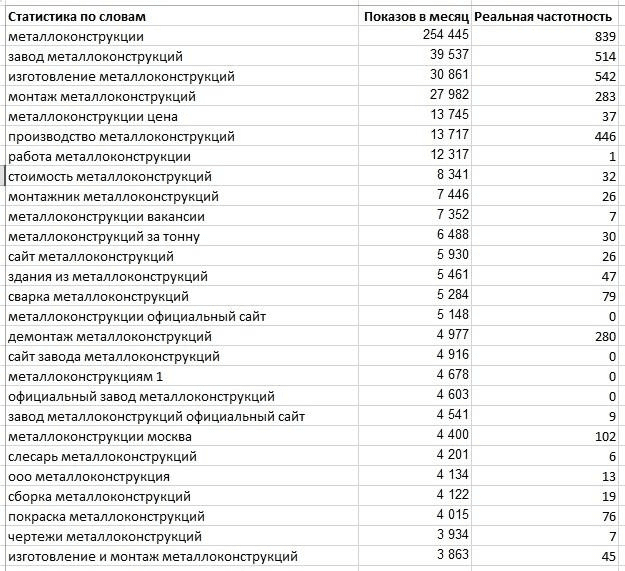
Как видно, точная частотность значительно меньше базовой. Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Операторы Яндекс.Вордстат
Все вышеприведенные примеры демонстрируют статистику по запросам широкого спектра. То есть, когда мы запрашиваем у Вордстата статистику по запросу «велосипед» и видим цифру 6 887 204, то это вовсе не значит, что пользователи искали слово «велосипед» такое количество раз. Статистика показывает сумму различных запросов, включающих это слово, в том числе «купить велосипед», «велосипед цена» и т. д.
Уточнить статистику запросов можно с помощью различных операторов.
Недостатки операторов Wordstat
Операторы Яндекс.Вордстат — штука удобная. Они позволяют получать точные данные по большому числу запросов за короткое время. Но даже у них есть недоработки.
Во-первых, некоторые операторы не комбинируются между собой. Так, например, нельзя одновременно использовать операторы «» и (|), а хотелось бы. Однако задействовать операторы «» и! одновременно можно:

Во-вторых, операторы не работают при просмотре истории запросов. Поэтому просматривать историю и сезонность мы можем только по запросам широкого спектра.
Пошаговая инструкция по работе с Yandex Wordstat
Для грамотного использования Яндекс Вордстат необходимо:
- Зарегистрироваться и войти в свою почту (аккаунт) на Яндексе;
- Записать в поле запрос и кликнуть «Подобрать».
Если вы не залогинились в своем аккаунте, то Yandex Wordstat при заходе в него предложит вам сделать это.
Давайте пробежимся по функционалу интерфейса.
Под основной строкой для ввода ключевого слова есть три флажка:
- «По словам»;
- «По регионам»;
- «История запросов».
Подробнее работу с каждым из них мы рассмотрим далее.
Справа ссылка «Все регионы» — позволит выбрать и посмотреть статистику ключевика по заданному региону.
Сбор запросов по словам
Как видно из вышеприведенного скриншота в Яндекс Вордстат этот вариант стоит «по умолчанию». Он показывает статистику запросов по региону, если тот выбран, если нет, то статистика показывается по всем регионам.
Давайте введем в основное поле фразу «Стройматериалы» и посмотрим, что покажет нам Wordstat. Возможно, вам придется ввести капчу. У меня обошлось без этого.
Система выдаст две колонки, которые будут содержать различные вариации заданного ключевого слова.
В левом столбце Яндекс Вордстат будут все прямые и непрямые вхождения. Правый — отобразит похожие запросы — «стройматериалы», «строительные материалы», «строительный рынок» и т.д. Т.е. отсюда можно выбрать достаточно интересные ключи для продвижения и этим не стоит пренебрегать.
Цифры, расположенные справа от запросов — это количество показов в месяц. Но это всего лишь прогнозируемый Яндексом результат, который вычисляется из статистики поисковика. Т.е. реальный результат может быть больше или меньше прогнозируемого. Но в принципе, плюс/минус Яша всегда показывает «правду».
Еще можно посмотреть статистику отдельно для десктопов, мобильников и т.п., просто переключив флажок в соответствующее поле, под основным полем ввода исследуемой фразы.
Сбор ключевых слов по регионам
При просмотре ключей по регионам на выбор предлагается 3 вкладки:
- Регионы;
- Города;
- Все вместе.
Справа, напротив каждого запроса мы видим соотношение популярности ключа к тому или иному региону. Если кликнуть на соответствующую ссылку, то можно отсортировать запросы по региональной популярности.
Можно посмотреть частотности ключевых слов, показываемые на том или ином устройстве: смартфоне, планшете, ПК и т.д.
Кликнув по вкладке «Карта» откроется интерактивная карта. Наведя мышку на интересующую область, отобразится статистика по этому региону. Желтые области на карте относятся к наиболее популярным, красные к менее популярным.
Как посмотреть историю запросов
Установив флажок в поле «История запросов» можно посмотреть частоту показа этого запроса в определенный период времени (неделя, месяц, год). Таким образом определяются сезонные фразы.
Что это значит? Сезонные запросы – это те запросы, которые пользователи вбивают только в определенное время. Например, фраза «купить велосипед» будет вводиться в поиске Яндекса гораздо чаще весной и летом, чем осенью и зимой. Думаю, что вы со мной согласитесь.
График показывает наглядное изменение количества вводимых фраз за период с 2018 года по 2019. Здесь же можно сделать группировку по неделям и месяцам и выбрать требуемое устройство, как и на предыдущей вкладке.
На графике показаны две кривые – с абсолютным и относительным значениями. Абсолютное показывает значение в данный момент, а относительное – отношение реального количества к общему числу показов за неделю или за месяц. Это общая популярность фразы.
Специальные операторы
Например, вам надо, чтобы сервис показал только определенные фразы в точной словоформе, падеже, числе и тому подобное. Для этого надо обрамить фразу в кавычки и поставить перед каждым словом восклицательный знак. Например, «!жилье !за !границей».
| Оператор | Значение |
| — | Если фраза содержит знак минус, то это слово удаляется. |
|
+ |
Если фраза содержит знак плюс, то показываются только те запросы, которые содержат это слово. |
|
«» |
Фраза в кавычках показывает все слова из данного запросов в любом порядке и словоформе. |
| «!» | Точное вхождение. |
Например, если мы ищем «жилье за -границей», то нам будут показаны только фразы с «жилье за». Слово «граница» не будет учитываться.