Иерархическая база данных и реляционная база данных 2020
Содержание:
- Проектирование баз данных
- Как скачать и установить сборку
- Примеры
- Основные свойства типа hierarchyidKey Properties of hierarchyid
- 8.1. Иерархическая модель базы данных
- Как работают базы данных.
- Виды баз данных
- Отзывы и комментарии о сайте: cashbox.ru
- Как хранится информация в БД
- В чём преимущества
- Управляющая часть иерархической модели
- Ниже описаны подходы к индексированию иерархических данных:Indexing Strategies for Hierarchical Data
- Программы доступа к Webmoney
- Пример табличной базы данных
- BDB (BerkeleyDB)
- MyISAM
- Как отследить iPhone друга через Find My Friends?
- Бинарные связи
- История
- Достоинства и недостатки реляционной модели данных
- Как настроить роутер ASUS RT-N11P?
- Структурная часть иерархической модели
- Ошибка 0xc000021a – программное обеспечение не совместимо с операционной системой
- Тип поля
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Как скачать и установить сборку
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Основные свойства типа hierarchyidKey Properties of hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии.A value of the hierarchyid data type represents a position in a tree hierarchy. Значения hierarchyid обладают следующими свойствами.Values for hierarchyid have the following properties:
-
Исключительная компактностьExtremely compact
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла.The average number of bits that are required to represent a node in a tree with n nodes depends on the average fanout (the average number of children of a node). Для структур с низкой степенью ветвления (0-7) объем занимаемой памяти равен примерно 6*logA n бит, где A — среднее ветвление.For small fanouts, (0-7) the size is about 6*logA n bits, where A is the average fanout. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит.A node in an organizational hierarchy of 100,000 people with an average fanout of 6 levels takes about 38 bits. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.This is rounded up to 40 bits, or 5 bytes, for storage.
-
Сравнение проводится в порядке приоритета глубиныComparison is in depth-first order
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину.Given two hierarchyid values a and b, a<b means a comes before b in a depth-first traversal of the tree. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом.Indexes on hierarchyid data types are in depth-first order, and nodes close to each other in a depth-first traversal are stored near each other. Например, потомки некоторой записи хранятся рядом с этой записью.For example, the children of a record are stored adjacent to that record.
-
Поддержка произвольных вставок и удаленийSupport for arbitrary insertions and deletions
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами.By using the GetDescendant method, it is always possible to generate a sibling to the right of any given node, to the left of any given node, or between any two siblings. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее.The comparison property is maintained when an arbitrary number of nodes is inserted or deleted from the hierarchy. Большинство операций вставки и удаления сохраняют свойство компактности.Most insertions and deletions preserve the compactness property. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.However, insertions between two nodes will produce hierarchyid values with a slightly less compact representation.
8.1. Иерархическая модель базы данных
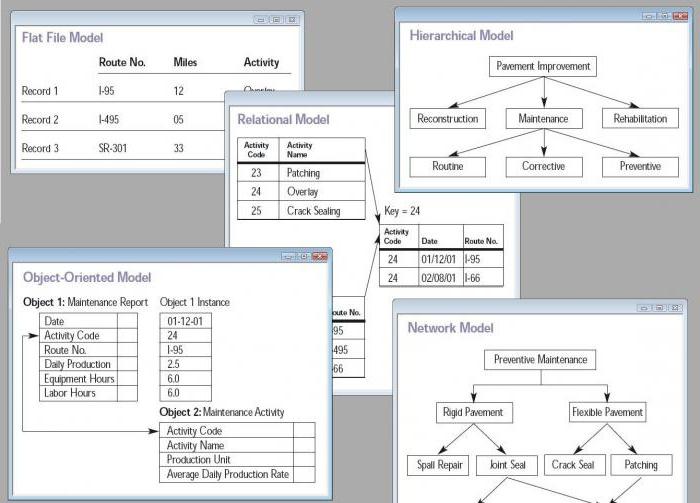
Иерархические
модели баз
данных исторически возникли одними из
первых. Информация в
иерархической базе организована по
принципу древовидной структуры, в виде
отношений «предок-потомок«.
Каждая запись может
иметь не более одной родительской записи
и несколько подчиненных. Связи записей
реализуются в виде физических указателей
с одной записи на другую. Основной
недостаток иерархической
структуры базы данных —
невозможность реализовать отношения
«многие-ко-многим«,
а также ситуации, когда запись имеет
несколько предков.
Иерархические
базы данных. Иерархические
базы данных графически
могут быть представлены как
перевернутое дерево,
состоящее из объектов различных уровней.
Верхний уровень (корень
дерева)
занимает один объект,
второй — объекты второго уровня и так
далее.
Между
объектами существуют связи,
каждый объект может
включать в себя несколько объектов
более низкого уровня. Такие объекты
находятся в отношении предка (объект,
более близкий к корню) к потомку
(объект более
низкого уровня), при этомобъект-предок
может не иметь потомков или иметь их
несколько, тогда как объект—потомок обязательно
имеет только одного предка. Объекты,
имеющие общего предка, называются
близнецами.

Рис.
6. Иерархическая
база данных
Организация
данных в СУБД иерархического
типа определяется в терминах: элемент,
агрегат, запись (группа),
групповоеотношение, база
данных.
|
Атрибут(элемент |
— |
|
Запись |
— |
|
Групповое |
— иерархическое |
|
Пример.
Поэтому,
Для
Рис. |

Из
этого примера видны недостатки
иерархических БД:
Частично
дублируется информация между
записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие
записи называют парными), причем
виерархической
модели данных не
предусмотрена поддержка соответствия
между парными записями.
Иерархическая
модель реализует отношение между
исходной и дочерней записью по схеме
1:N, то есть одной родительской записи
может соответствовать любое число
дочерних.
Допустим
теперь, что исполнитель может
принимать участие более чем в одном
контракте (т.е. возникает связь типа
M:N). В этом случае в базу данных необходимо
ввести еще одно групповое отношение,
в котором ИСПОЛНИТЕЛЬ будет
являться исходной записью, а КОНТРАКТ
— дочерней ( рис.
7 c). Таким образом, мы опять вынуждены
дублировать информацию.
Иерархическая
структура предполагаета неравноправие
между данными — одни жестко подчинены
другим. Подобные структуры, безусловно,
четко удовлетворяют требованиям многих,
но далеко не всех реальных задач.
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Виды баз данных
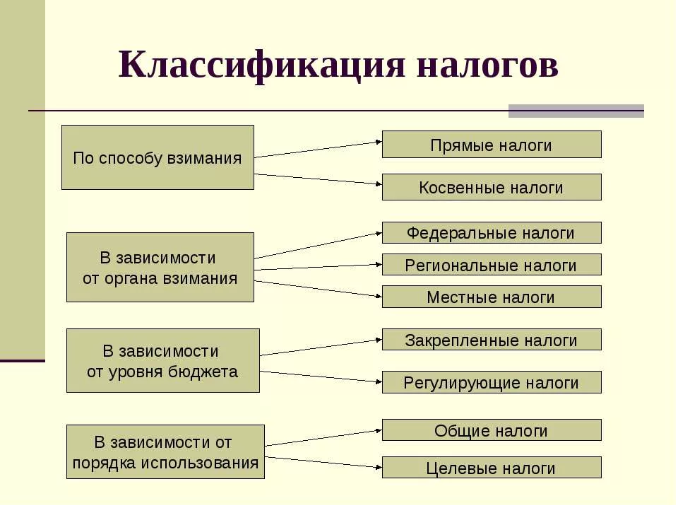
Как известно, различают четыре вида посторения БД:
- Реляционные — табличные СУБД, где информация представлена в виде строк-столбцов. По этому принципу строятся базы данных в «Аксесе», к примеру.
- Объектно-ориентированные — тесно связаны с ООП (программированием, в котором идет работа с объектами), и это их главный плюс, но, учитывая их небольшую производительность, они пока значительно уступают в распространенности реляционным.
- Гибридные — СУБД, вмещающие в себе сразу два указанных выше вида.
- Иерархические — объект внимания данной статьи. Это БД, характеризирующиеся древообразной структурой.
Наиболее известным примером иерархической базы данных является продукт, созданный компанией IBM («АйБиЭм»), под названием Information Management System (переводится как «Информационная система управления»), сокращенно IMS. Первая версия IMS вышла еще в прошлом, двадцатом веке, в шестьдесят восьмом году. Она используется для хранения и контроля данных и поныне.
Отзывы и комментарии о сайте: cashbox.ru
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Ниже описаны подходы к индексированию иерархических данных:Indexing Strategies for Hierarchical Data
Есть два подхода к индексированию иерархических данных:There are two strategies for indexing hierarchical data:
-
В глубинуDepth-first
В индексе преимущественно в глубину строки поддерева хранятся рядом друг с другом.A depth-first index stores the rows in a subtree near each other. Например, записи всех сотрудников, в цепи подчиненности которых есть данный руководитель, хранятся рядом с записью руководителя.For example, all employees that report through a manager are stored near their managers’ record.
В индексе преимущественно в глубину все узлы поддерева узла хранятся вместе.In a depth-first index, all nodes in the subtree of a node are co-located. Поэтому индекс преимущественно в глубину эффективен для обработки запросов по поддеревьям. Например, «найти все файлы в этой папке и ее подкаталогах».Depth-first indexes are therefore efficient for answering queries about subtrees, such as «Find all files in this folder and its subfolders».
-
В ширинуBreadth-first
Если используется индексирование в ширину, строки одного уровня иерархии хранятся вместе.A breadth-first stores the rows each level of the hierarchy together. Например, записи всех сотрудников, напрямую подчиненных одному и тому же руководителю, хранятся рядом друг с другом.For example, the records of employees who directly report to the same manager are stored near each other.
В индексе преимущественно в ширину все прямые потомки узла хранятся в одном месте.In a breadth-first index all direct children of a node are co-located. Поэтому индекс преимущественно в ширину эффективен для запросов по прямым потомкам. Например: «найти всех прямых подчиненных этого начальника».Breadth-first indexes are therefore efficient for answering queries about immediate children, such as «Find all employees who report directly to this manager».
Выбор стратегии индексирования (в глубину, в ширину или обе) и ключа кластеризации зависит от того, какие из вышеуказанных типов запросов обрабатываются чаще и какие операции более важны (SELECT или DML).Whether to have depth-first, breadth-first, or both, and which to make the clustering key (if any), depends on the relative importance of the above types of queries, and the relative importance of SELECT vs. DML operations. Пример использования стратегий индексирования см. в разделе Tutorial: Using the hierarchyid Data Type.For a detailed example of indexing strategies, see Tutorial: Using the hierarchyid Data Type.
Создание индексовCreating Indexes
Для организации данных в ширину можно использовать метод GetLevel().The GetLevel() method can be used to create a breadth first ordering. В следующем примере создаются оба типа индекса: преимущественно в глубину и преимущественно в ширину.In the following example, both breadth-first and depth-first indexes are created:
Программы доступа к Webmoney
Пример табличной базы данных
Рассмотрим базу данных «Компьютер» (рис.3), которая представляет собой перечень объектов (компьютеры), каждый из которых имеет свое имя (название). В качестве характеристик (свойств) будут выступать тип процессора и объем оперативной памяти.

Столбцы этой таблицы представляют поля, каждое из которых имеет свое имя (название соответствующего свойства) и тип данных, которые отражают значения этого свойства. Тип полей Название и Тип процессора — текстовый, а тип поля Оперативная память — числовой. При этом каждое поле имеет определенный набор свойств (размер, формат и др.). Так, для поля Оперативная память задается формат данных «целое число».
Определение 3
Полем базы данных является столбец таблицы, который включает в себя значения определенного свойства.
Строки таблицы представляют записи об объекте, которые разбиты столбцами таблицы на поля. Запись базы данных представляет собой строку таблицы, содержащую набор значений различных свойств объекта.
Замечание 3
Каждая таблица должна иметь хотя бы 1 ключевое поле, содержимое которого является уникальным для любой записи в данной таблице. Значениями ключевого поля однозначно определяются записи в таблице.
BDB (BerkeleyDB)
Таблицы типа BDB обслуживаются транзакционным обработчиком Berkeley DB, разработанным компанией Sleepycat. При создании таблиц данного типа формируются два файла: первый с расширением frm, в котором определяется структура базы данных, а второй с расширением db, в котором размещаются данные и индексы.
Особенности типа BDB:
- Для каждой таблицы ведется журнал. Это позволяет значительно повысить устойчивость базы и увеличить вероятность успешного восстановления после сбоя.
- Таблицы BDB хранятся в виде бинарных деревьев. Такое представление замедляет сканирование таблицы и увеличивает занимаемое место на жестком диске по сравнению с другими типами таблиц. С другой стороны, поиск отдельных значений в таких таблицах осуществляется быстрее.
- Каждая таблица BDB должна иметь первичный ключ, в случае его отсутствия создается скрытый первичный ключ, снабженный атрибутом AUTO_INCREMENT.
- Поддерживаются транзакции на уровне страниц.
- Подсчет числа строк в таблице при помощи встроенной функции count() осуществляется медленнее, чем для MyISAM, так как в отличие от последних, для BDB-таблиц не поддерживается подсчет количества строк в таблице, и MySQL вынужден каждый раз сканировать таблицу заново.
- Ключи не являются упакованными, и ключи занимают больше места.
- Если таблица займет все пространство на диске, то будет выведено сообщение об ошибке и выполнен откат транзакции.
- Для обеспечения блокировок таблиц на уровне операционной системы в файл db в момент создания таблицы записывается путь к файлу. Это приводит к тому, что файлы нельзя перемещать из текущего каталога в другой каталог.
- При создании резервных копий таблиц необходимо использовать утилиту mysqldump или создать резервные копии всех db файлов и файлов журналов. Обработчик таблицы хранит незавершенные транзакции в файлах журналов, их наличие требуется при запуске сервера MySQL.
MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
Как отследить iPhone друга через Find My Friends?
Приложение Find My Friends предоставляет пользователю возможность узнать, где находятся его друзья и близкие. Если на телефоне установлена операционная система iOS 9 или более поздняя версия, то программа должна быть установлена по умолчанию. На iOS 8 понадобится ручная установка приложения. Если войти в сервис iCloud на своем устройстве, то автоматически будет выполнен вход в приложение Find My Friends с таким же Apple ID.
Смартфон друга будет обнаружен, только если у него тоже установлена такая программа. Для добавления друга необходимо:
- запустить приложение Find Friends;
- нажать кнопку «Добавить»;
- выбрать необходимое имя из списка или ввести адрес электронной почты;
- нажать «Готово», после чего запрос будет отправлен.
Если друг согласен делиться своим местоположением на карте, он одобрит запрос. В дальнейшем его можно будет отслеживать онлайн через Find My Friends или веб-страницу iCloud.
При желании можно указать электронный адрес, который понадобится для отправки запросов. Если пользователь не хочет, чтобы его отслеживали, он может отключить запросы на дружбу в разделе «Приглашения».
Бинарные связи
Бинарные связи – это связи, в которые вступают ровно две сущности. Важнейшее свойство связи – кардинальное число.
Типы бинарных связей:
- Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан не более чем с одним экземпляром второй сущности и, наоборот, один экземпляр второй сущности связан не более чем с одним экземпляром первой сущности.
- Связь типа «один-ко-многим» означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности, но при этом один экземпляр второй сущности связан не более чем с один экземпляром первой сущности.
- Связь типа «много-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Эта связь должна быть заменена двумя связями типа один-ко-многим путем создания промежуточной сущности.
История
Иерархическая структура была разработана IBM в 1960-х годах и использовалась в ранних СУБД для мэйнфреймов . Отношения между записями образуют древовидную модель. Эта структура проста, но негибка, поскольку отношения ограничиваются отношениями «один ко многим». Система IBM Information Management (IMS) и RDM Mobile являются примерами иерархической системы баз данных с несколькими иерархий над теми же данными. RDM Mobile — это недавно разработанная встроенная база данных для мобильной компьютерной системы.
Иерархическая модель данных потеряли тракция Кодда «s реляционную модель стала стандартом де — факто используется практически во всех системах управления базами данных господствующих. Реализация иерархической модели в реляционной базе данных впервые была опубликована в 1992 г. (см. Также модель вложенных множеств ). Иерархические схемы организации данных вновь появились с появлением XML в конце 1990-х (см. Также базу данных XML ). Иерархическая структура сегодня используется в основном для хранения географической информации и файловых систем.
В настоящее время иерархические базы данных по-прежнему широко используются, особенно в приложениях, требующих очень высокой производительности и доступности, таких как банковское дело и телекоммуникации. Одна из наиболее широко используемых коммерческих иерархических баз данных — IMS. Другой пример использования иерархических баз данных реестра Windows в Microsoft Windows операционных систем.
Достоинства и недостатки реляционной модели данных
Достоинства
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
Недостатки
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
Как настроить роутер ASUS RT-N11P?
После всего этого можно смело открыть браузер и ввести адрес http://192.168.1.1, по которому находится вход в настройки роутера Асус. Здесь нужно отметить, что в зависимости от модификации, этот адрес может отличаться, например будет 192.168.0.1, 192.168.0.10 или 192.168.1.10. Чтобы этот момент уточнить, загляните в ту же самую этикетку, которая находится на нижней крышке маршрутизатора — там имеется вся необходимая информация для подключения.
После входа в панель управления мы попадаем в мастер быстрой настройки, что очень удобно для пошаговой установки подключения Асус к интернету, особенно для новичков. В первом окне просто жмем на «Перейти»
Далее нам предлагается сразу же сменить пароль на роутер, чтобы обеспечить безопасность входа в его настройки — задаем свой пароль.
Далее начнется процесс автоматического определения типа вашего подключения к интернету. Поскольку у меня в данный момент используется «Динамический IP», никаких дополнительных проверок и авторизаций проходить не нужно. Если же у вас другой тип, то его можно задать позже уже в полном меню настроек Асус.
На последнем шаге — установка имени для беспроводной сети и пароля для подключения (тут он называется «сетевой ключ»). В данной модели wifi работает только на частоте 2.4 ГГц. В некоторых других, у которых есть поддержка 5 ГГц, нужно было бы еще настроить и вторую сеть.
В заключительном окне отобразятся все только что заданные параметры нашей сети.
При этом наш wifi уже появился в списке беспроводных подключений
Для того, чтобы зайти обратно в маршрутизатор, теперь уже потребуется ввести логин и пароль, которые мы задали на первом шаге.
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Ошибка 0xc000021a – программное обеспечение не совместимо с операционной системой
Это в равной мере относится и к программам, и к драйверам, которые могут не соответствовать требованиям Windows 10 и работать некорректно. Обратитесь к сайту производителя вашего ПО или драйвером и скачайте новую версию, возможно она уже имеет поддержку Windows 10. В любом случае старую версию программы или драйвера нужно удалить и тогда ошибки не будет.
Тип поля
Тип поля определяется по типу данных, содержащихся в нем. В полях могут содержаться данные следующих типов:
- Счетчик, в нем содержится последовательность целых чисел, задаваемых автоматически при вводе записей. Пользователь данные числа не может изменить;
- Текстовый, в нем содержатся символы различных типов;
- Числовой, в нем содержатся числа различных типов;
- Дата/Время используется для содержания даты или времени;
- Картинка, используется для хранения изображения;
- Логический, имеет значения Истина (Да) или Ложь (Нет).
Для каждого типа характерен свой набор свойств. Наиболее важными из которых являются:
- размер поля используется для определения максимальной длины текстового или числового поля;
- формат поля используется для установления формата данных;
- обязательное поле используется для указания на то, что это поле обязательно нужно заполнить.