Потоки ввода-вывода. работа с файлами
Содержание:
- Новые возможности пакета java.uti.concurrent
- Проблемы, которые создает многопоточность
- Дополнительные материалы
- 1 Потоки данных
- Ограничения классического подхода
- Что такое многопоточность в Java?
- Методы wait и notify
- Классический подход к запуску задач в многопоточном режиме
- Looper
- Запуск задач с помощью java.util.concurrent.ExecutorService
- Почему поток пулов?
- Как выбирать производителя твердотельных накопителей
- Закрытие потоков
Новые возможности пакета java.uti.concurrent
Платформа Java постоянно развивается, и поэтому к существующей функциональности все время добавляются новые возможности. Иногда новая функциональность берется из уже существующих сторонних библиотек, при этом речь не идет о банальном копировании, а скорее о переосмыслении и доработке уже существующих решений. Подобным способом в версию Java 5 был добавлен пакет java.util.concurrent, включающий в себя множество уже проверенных и хорошо зарекомендовавших себя приемов для параллельного выполнения задач (этот пакет — только одно из множества важных нововведений, представленных в Java 5).
В рамках этой статьи интерес представляют уже готовые к использованию реализации шаблонов WorkerThread и ThreadPool, а также еще один способ реализации задач для параллельного выполнения, кроме упоминавшихся класса Thread и интерфейса Runnable. Ещё в пакете java.util.concurrent находятся два подпакета: java.util.concurrent.locks и java.util.concurrent.atomic, с которыми тоже стоит ознакомиться, так как они значительно упрощают организацию взаимодействия между потоками и параллельного доступа к данным.
Проблемы, которые создает многопоточность
Deadlock
- Поток-1 перестанет работать с Объектом-1 и переключится на Объект-2, как только Поток-2 перестанет работать с Объектом 2 и переключится на Объект-1.
- Поток-2 перестанет работать с Объектом-2 и переключится на Объект-1, как только Поток-1 перестанет работать с Объектом 1 и переключится на Объект-2.
Потоки никогда не поменяются местами и будут ждать друг друга вечно. deadlock
Поток-0 достает яйца из холодильника.
Поток-1 включает плиту.
Поток-2 достает сковородку и ставит на плиту.
Поток-3 зажигает огонь на плите.
Поток-4 выливает на сковороду масла.
Поток-5 разбивает яйца и выливает их на сковороду.
Поток-6 выбрасывает скорлупу в мусорное ведро.
Поток-7 снимает готовую яичницу с огня.
Поток-8 выкладывает яичницу в тарелку.
Поток-9 моет посуду.Выполнен поток Thread-0
Выполнен поток Thread-2
Выполнен поток Thread-1
Выполнен поток Thread-4
Выполнен поток Thread-9
Выполнен поток Thread-5
Выполнен поток Thread-8
Выполнен поток Thread-7
Выполнен поток Thread-3
Выполнен поток Thread-6
Дополнительные материалы
Чтение
- Блог Алексея Шипилёва — знаю, что очевидно, но просто грех не упомянуть
- Блог Черемина Руслана — последнее время не пишет активно, нужно искать в блоге его старые записи, поверьте это стоит того — там кладезь
- Хабр Глеба Смирнова — есть отличные статьи про многопоточность и модель памяти
- Блог Романа Елизарова — заброшен, но археологические раскопки провести нужно. В целом Роман очень много сделал для просветления народа в области теории многопоточного программирования, ищите его в медиа.
Подкасты
- SDCast #62: в гостях Александр Титов и Амир Аюпов, инженеры из Intel и Алексей Маркин, программист из МЦСТ
- SDCast #63: в гостях Алексей Маркин, программист из МЦСТ
- Разбор Полетов: #107 Истории альпинистов
- Разбор Полетов: #154 Кишочки — Атака на Новый Год
Видео
- Computer Science Center — Лекция 11. Модели памяти и проблемы видимости
- Теория и практика многопоточного программирования
1 Потоки данных
Любая программа редко существует сама по себе. Обычно она как-то взаимодействует с «внешним миром». Это может быть считывание данных с клавиатуры, отправка сообщений, загрузка страниц из интернета или, наоборот, загрузка файлов на удалённый сервер.
Все эти вещи мы можем назвать одним словом — процесс обмена данными между программой и внешним миром. Хотя это уже не одно слово.
Сам процесс обмена данными можно разделить на два типа: получение данных и отправка данных. Например, вы считываете данные с клавиатуры с помощью объекта — это получение данных. И выводите данные на экран с помощью команды — это отправка данных.
Для описания процесса обмена данными в программировании используется термин поток. Откуда вообще взялось такое название?
В реальной жизни им может быть поток воды или поток людей (людской поток). В программировании же под потоком подразумевают поток данных.
Потоки — это универсальный инструмент. Они позволяют программе получать данные откуда угодно (входящие потоки) и отправляют данные куда угодно (исходящие потоки). Делятся на два вида:
- Входящий поток (Input): используется для получения данных
- Исходящий поток (Output): используется для отправки данных
Чтобы потоки можно было «потрогать руками», разработчики Java написали два класса: и .
У класса есть метод , который позволяет читать из него данные. А у класса есть метод , который позволяет записывать в него данные. У них есть и другие методы, но об этом после.
Байтовые потоки
Что же это за данные и в каком виде их можно читать? Другими словами, какие типы данных поддерживаются этими классами?
О, это универсальные классы, и поэтому они поддерживают самый распространённый тип данных — . В можно записывать байты (и массивы байт), а из объекта можно читать байты (или массивы байт). Все — никакие другие типы данных они не поддерживают.
Поэтому такие потоки еще называют байтовыми потоками.
Особенность потоков в том, что данные из них можно читать (писать) только последовательно. Вы не можете прочитать данные из середины потока, не прочитав все данные перед ними.
Именно так работает чтение с клавиатуры через класс : вы читаете данные с клавиатуры последовательно: строка за строкой. Прочитали строку, прочитали следующую строку, прочитали следующую строку и т.д. Поэтому метод чтения строки и называется (дословно — «следующая срока»).
Запись данных в поток тоже происходит последовательно. Хороший пример — вывод на экран. Вы выводите строку, за ней еще одну и еще одну. Это последовательный вывод. Вы не можете вывести 1-ю строку, затем 10-ю, а затем вторую. Все данные записываются в поток вывода только последовательно.
Символьные потоки
Недавно вы изучали, что строки — второй по популярности тип данных, и это действительно так. Очень много информации передается в виде символов и целых строк. Компьютер отлично бы передавал все в виде байт, но люди не настолько идеальны.
Java-программисты учли этот факт и написали еще два класса: и . Класс — это аналог класса , только его метод читает не байты, а символы — . Класс соответствует классу , и так же, как и класс , работает с символами (), а не байтами.
Если сравнить эти четыре класса, мы получим такую картину:
| Байты (byte) | Символы (char) | |
|---|---|---|
| Чтение данных | ||
| Запись данных |
Практическое применение
Сами классы , , и в явном виде никто не использует: они не присоединены ни к каким внешним объектам, из которых можно читать данные (или в которые можно писать данные). Однако у этих четырех классов много классов-наследников, которые умеют очень многое.
Ограничения классического подхода
Когда программист только начинает работать с многопоточными возможностями Java-платформы, то на первых порах он может даже впасть в состояние «эйфории», особенно, если у него уже был негативный опыт по созданию многопоточных приложений в других языках программирования
Действительно, система управления потоками в Java организованна крайне удачно, так как этот компонент платформы был детально проработан еще на стадии проектирования самых первых версий виртуальной Java-машины и языка программирования Java, и сейчас ему по-прежнему уделяется большое внимание. Однако со временем «розовые очки» спадают, и программист начинает замечать «раздражающие» моменты, которые усложняют организацию параллельного исполнения задач в Java
Первым, что бросается в глаза, оказывается слияние низкоуровневого кода, отвечающего за многопоточное исполнение, и высокоуровневого кода, отвечающего за основную функциональность приложения (так называемый «спагетти-код»). В листинге 1 показано, что бизнес—код и поточный код вообще находятся в одном классе, но даже в более удачном варианте из листинга 2 для выполнения задачи все равно требуется создать объект Thread и запустить его. Подобное перемешивание снижает качество архитектуры приложения и может затруднить его последующее сопровождение.
Но даже если удалось отделить поточный код от основного, то возникает проблема, связанная уже с управлением самими потоками. Потоки в Java запускаются только путем вызова метода start и останавливаются после вызова соответствующих методов или самостоятельно после завершения работы метода run. Также после того, как поток остановился, его нельзя запустить второй раз, что и приводит к следующим негативным моментам:
- поток занимает относительно много места в куче, так что после его завершения необходимо проследить, чтобы память, занимаемая им, была освобождена (например, присвоить ссылке на поток значение null);
- для выполнения новой задачи потребуется запустить новый поток, что приведет к увеличению «накладных расходов» на виртуальную машину, так как запуск потока – это одна из самых требовательных к ресурсам операций.
Если же удалось превратить поток в «многоразовый», то программист сталкивается с проблемой, как понять, что поток уже закончил выполнение задачи и ему можно выдавать следующую. Необходимо еще учитывать тот факт, что выполнение задачи может завершиться неудачно, например, возникновением исключительной ситуации, и подобная ситуация не должна повлиять на выполнение других задач.
Важно сказать, что «среднестатистический» программист будет отнюдь не первым, кто сталкивается с подобными проблемами в многозадачных приложениях. Все эти проблемы были давно проанализированы Java-сообществом и нашли решение в признанных шаблонах проектирования (например, ThreadPool (пул потоков) и WorkerThread (рабочий поток))
Но скорее всего, у рядового программиста, ограниченного временными рамками проекта, просто не будет времени или ресурсов, чтобы подготовить и самое главное протестировать полноценную реализацию данных шаблонов. А неточное или неполное внедрение этих шаблонов (да и вообще любых шаблонов проектирования) может в будущем негативно сказаться на этапе сопровождения продукта.
Что такое многопоточность в Java?
MULTITHREADING или многопоточность в Java — это процесс одновременного выполнения двух или более потоков с максимальной загрузкой ЦП. Многопоточные приложения выполняют одновременно два или более потоков. Следовательно, он также известен как параллелизм в Java. Каждый поток проходит параллельно друг другу.
Несколько потоков не выделяют отдельную область памяти, следовательно, они экономят память. Кроме того, переключение контекста между потоками занимает меньше времени.
Пример:
package demotest;
public class GuruThread1 implements Runnable
{
public static void main(String[] args) {
Thread guruThread1 = new Thread("Guru1");
Thread guruThread2 = new Thread("Guru2");
guruThread1.start();
guruThread2.start();
System.out.println("Thread names are following:");
System.out.println(guruThread1.getName());
System.out.println(guruThread2.getName());
}
@Override
public void run() {
}
}
Преимущества многопоточности:
- Пользователи не заблокированы, потому что потоки независимы, и мы можем выполнять несколько операций за раз
- Поскольку такие потоки независимы, другие потоки не будут затронуты, если один поток встретит исключение.
Методы wait и notify
Последнее обновление: 27.04.2018
Иногда при взаимодействии потоков встает вопрос о извещении одних потоков о действиях других. Например, действия одного потока зависят от результата действий другого потока,
и надо как-то известить один поток, что второй поток произвел некую работу. И для подобных ситуаций у класса Object определено ряд методов:
-
wait(): освобождает монитор и переводит вызывающий поток в состояние ожидания до тех пор, пока другой поток не вызовет метод
-
notify(): продолжает работу потока, у которого ранее был вызван метод
-
notifyAll(): возобновляет работу всех потоков, у которых ранее был вызван метод
Все эти методы вызываются только из синхронизированного контекста — синхронизированного блока или метода.
Рассмотрим, как мы можем использовать эти методы. Возьмем стандартную задачу из прошлой темы — «Производитель-Потребитель» («Producer-Consumer»):
пока производитель не произвел продукт, потребитель не может его купить. Пусть производитель должен произвести 5 товаров, соответственно потребитель
должен их все купить. Но при этом одновременно на складе может находиться не более 3 товаров.
Для решения этой задачи задействуем методы и :
public class Program {
public static void main(String[] args) {
Store store=new Store();
Producer producer = new Producer(store);
Consumer consumer = new Consumer(store);
new Thread(producer).start();
new Thread(consumer).start();
}
}
// Класс Магазин, хранящий произведенные товары
class Store{
private int product=0;
public synchronized void get() {
while (product<1) {
try {
wait();
}
catch (InterruptedException e) {
}
}
product--;
System.out.println("Покупатель купил 1 товар");
System.out.println("Товаров на складе: " + product);
notify();
}
public synchronized void put() {
while (product>=3) {
try {
wait();
}
catch (InterruptedException e) {
}
}
product++;
System.out.println("Производитель добавил 1 товар");
System.out.println("Товаров на складе: " + product);
notify();
}
}
// класс Производитель
class Producer implements Runnable{
Store store;
Producer(Store store){
this.store=store;
}
public void run(){
for (int i = 1; i < 6; i++) {
store.put();
}
}
}
// Класс Потребитель
class Consumer implements Runnable{
Store store;
Consumer(Store store){
this.store=store;
}
public void run(){
for (int i = 1; i < 6; i++) {
store.get();
}
}
}
Итак, здесь определен класс магазина, потребителя и покупателя. Производитель в методе добавляет в объект Store с помощью его метода
6 товаров. Потребитель в методе в цикле обращается к методу объекта Store для получения
этих товаров. Оба метода Store — и являются синхронизированными.
Для отслеживания наличия товаров в классе Store проверяем значение переменной . По умолчанию товара нет, поэтому переменная равна .
Метод — получение товара должен срабатывать только при наличии хотя бы одного товара. Поэтому в методе
проверяем, отсутствует ли товар:
while (product<1)
Если товар отсутсвует, вызывается метод . Этот метод освобождает монитор объекта Store и блокирует выполнение метода get, пока для этого же монитора не будет вызван
метод .
Когда в методе добавляется товар и вызывается , то метод получает монитор и выходит из
конструкции , так как товар добавлен. Затем имитируется получение покупателем товара. Для этого
выводится сообщение, и уменьшается значение product: . И в конце вызов метода дает сигнал методу продолжить работу.
В методе работает похожая логика, только теперь метод должен срабатывать, если в магазине не более трех товаров. Поэтому в цикле проверяется наличие товара, и если товар уже есть,
то освобождаем монитор с помощью и ждем вызова в методе .
И теперь программа покажет нам другие результаты:
Производитель добавил 1 товар Товаров на складе: 1 Производитель добавил 1 товар Товаров на складе: 2 Производитель добавил 1 товар Товаров на складе: 3 Покупатель купил 1 товар Товаров на складе: 2 Покупатель купил 1 товар Товаров на складе: 1 Покупатель купил 1 товар Товаров на складе: 0 Производитель добавил 1 товар Товаров на складе: 1 Производитель добавил 1 товар Товаров на складе: 2 Покупатель купил 1 товар Товаров на складе: 1 Покупатель купил 1 товар Товаров на складе: 0
Таким образом, с помощью в методе мы ожидаем, когда производитель добавит новый продукт. А после добавления
вызываем , как бы говоря, что на складе освободилось одно место, и можно еще добавлять.
А в методе с помощью мы ожидаем освобождения места на складе. После того, как место освободится, добавляем товар и
через уведомляем покупателя о том, что он может забирать товар.
НазадВперед
Классический подход к запуску задач в многопоточном режиме
Классический подход к запуску задач в многопоточном режиме в JSE предполагает использование класса java.lang.Thread или интерфейса java.lang.Runnable. В первом случае программист создает потомка класса Thread и переопределяет в нем метод run, куда помещается функциональность, которую необходимо выполнить в многопоточном режиме, как показано в листинге 1.
Листинг 1. Запуск задач с помощью класса java.lang.Thread
1 public class ThreadSample extends Thread {
2 @Override
3 public void run() {
4 System.out.println("do some multithreaded task");
5 }
6 public static void main(String[] args) {
7 ThreadSample ts1 = new ThreadSample();
8 ts1.start();
9 }
10 }
Использование интерфейса Runnable основывается на другой парадигме. Сначала программист должен реализовать интерфейс Runnable в собственном классе, а затем поместить объект этого класса в объект типа Thread. Интересующая функциональность также помещается в метод run класса, реализующего интерфейс Runnable, и впоследствии вызывается объектом-контейнером, как показано в листинге 2.
Листинг 2. Запуск задач с помощью интерфейса java.lang.Runnable
1 public class RunnableSample implements Runnable {
2 public void run() {
3 System.out.println("do some multithreaded task");
4 }
5 public static void main(String[] args) {
6 RunnableSample rs1 = new RunnableSample();
7 Thread t1 = new Thread(rs1);
8 t1.start();
9 }
10 }
Как видно в обоих примерах запуск задачи в многопоточном режиме выполняется через вызов метода start объекта типа Thread. Только в первом случае после вызова метода start класса Thread происходит вызов метода run, наследника этого класса (класса ThreadSample), в котором и находится код, относящейся к задаче. При выборе реализации на основе интерфейса Runnable сначала происходит вызов метода start класса Thread, затем обращение к методу run этого же класса, и уже из этого метода вызывается метод run реализации интерфейса Runnable (класса RunnableSample).
Looper
Поток имеет в своём составе сущности Looper, Handler, MessageQueue.
Каждый поток имеет один уникальный Looper и может иметь много Handler.
Считайте Looper вспомогательным объектом потока, который управляет им. Он обрабатывает входящие сообщения, а также даёт указание потоку завершиться в нужный момент.
Поток получает свой Looper и MessageQueue через метод Looper.prepare() после запуска. Looper.prepare() идентифицирует вызывающий потк, создаёт Looper и MessageQueue и связывает поток с ними в хранилище ThreadLocal. Метод Looper.loop() следует вызывать для запуска Looper. Завершить его работу можно через метод looper.quit().
Используйте статический метод getMainLooper() для доступа к Looper главного потока:
Создадим два потока. Один запустим в основном потоке, а второй отдельно от основного. Нам будет достаточно двух кнопок и метки.
Обратите внимание, как запускаются потоки. Первый поток запускается с помощью метода start(), а второй — run()
Затем проверяем, в каком потоке мы находимся.
Эта тема достаточно сложная и для большинства не представляет интереса и необходимости изучать.
В Android потоки в чистом виде используются всё реже и реже, у системы есть собственные способы.
Запуск задач с помощью java.util.concurrent.ExecutorService
Облегчив с помощью интерфейса Callable создание задач для параллельного выполнения, пакет java.util.concurrent также берет на себя работу по запуску и остановке потоков. Вместо объекта Thread предлагается использовать объект типа ExecutorService, с помощью которого пользователь может просто поместить задачу в очередь на выполнение и ждать получения результата. Можно сказать, что ExecutorService – это значительно усовершенствованная реализация шаблона WorkerThread.
ExecutorService – это интерфейс, поэтому для выполнения задач используются его конкретные потомки, адаптированные под требования разрабатываемого приложения. Однако программисту нет необходимости создавать собственную реализацию ExecutorService, так как в пакете java.util.concurrent уже присутствуют различные варианты реализации ExecutorService. Доступ к ним можно получить через статические методы служебного класса Executors, метод которого newFixedThreadPool возвращает объект типа ExecutorService со встроенной поддержкой шаблона ThreadPool. Также в классе Executors есть и другие методы для создания объектов ExecutorService с различными свойствами.
Наибольший интерес в ExecutorService представляет метод submit, через который задача ставится в очередь на выполнение. На вход этот метод принимает объект типа Callable или Runnable, а возвращает некий параметризованный объект типа Future. Этот объект можно использовать для доступа к результату выполнения задачи, который будет возвращен из метода call соответствующего Callable-объекта. При этом через объект Future можно проверить, закончено ли уже выполнение задачи – с помощью метода isDone и через метод get получить доступ к результату или исключительной ситуации, если в процессе выполнения задачи произошла ошибка.
Таким образом, при запуске задач с помощью классов из пакета java.util.concurrent не требуется прибегать к низкоуровневой поточной функциональности класса Thread, достаточно создать объект типа ExecutorService с нужными свойствами и передать ему на исполнение задачу типа Callable. Впоследствии можно легко просмотреть результат выполнения этой задачи с помощью объекта Future, как показано в листинге 4.
Листинг 4. Запуск задачи с помощью классов пакета java.util.concurrent
1 public class ExecutorServiceSample {
2 public static void main(String[] args) {
3 //создать ExecutorService на базе пула из пяти потоков
4 ExecutorService es1 = Executors.newFixedThreadPool(5);
5 //поместить задачу в очередь на выполнение
6 Future<String> f1 = es1.submit(new CallableSample());
7 while(!f1.isDone()) {
8 //подождать пока задача не выполнится
9 }
10 try {
11 //получить результат выполнения задачи
12 System.out.println("task has been completed : " + f1.get());
13 } catch (InterruptedException ie) {
14 ie.printStackTrace(System.err);
15 } catch (ExecutionException ee) {
16 ee.printStackTrace(System.err);
17 }
18 es1.shutdown();
19 }
20}
Стоит обратить внимание на строку 18, где происходит остановка объекта ExecutorService с помощью метода shutdown. Дело в том, что потоки в объекте ExecutorService не останавливаются сами, как обычно, поэтому их необходимо явно остановить с помощью этого метода, при этом если в ExecutorService находятся невыполненные задачи, то потоки будут остановлены только, когда завершится последняя задача
Почему поток пулов?
Работа многих серверных приложений, таких как Web-серверы, серверы базы данных, серверы файлов или почтовые серверы, связана с совершением большого количества коротких задач, поступающих от какого-либо удаленного источника. Запрос прибывает на сервер определенным образом, например, через сетевые протоколы (такие как HTTP, FTP или POP), через очередь JMS, или, возможно, путем опроса базы данных. Независимо от того, как запрос поступает, в серверных приложениях часто бывает, что обработка каждой индивидуальной задачи кратковременна, а количество запросов большое.
Одной из упрощенных моделей для построения серверных приложений является создание нового потока каждый раз, когда запрос прибывает и обслуживание запроса в этом новом потоке. Этот подход в действительности хорош для разработки прототипа, но имеет значительные недостатки, что стало бы очевидным, если бы вам понадобилось развернуть серверное приложение, работающее таким образом. Один из недостатков подхода «поток-на-запрос» состоит в том, что системные издержки создания нового потока для каждого запроса значительны; a сервер, создавший новый поток для каждого запроса, будет тратить больше времени и потреблять больше системных ресурсов, создавая и разрушая потоки, чем он бы тратил, обрабатывая фактические пользовательские запросы.
В дополнение к издержкам создания и разрушения потоков, активные потоки потребляют системные ресурсы. Создание слишком большого количества потоков в одной JVM (виртуальной Java-машине) может привести к нехватке системной памяти или пробуксовке из-за чрезмерного потребления памяти. Для предотвращения пробуксовки ресурсов, серверным приложениям нужны некоторые меры по ограничению количества запросов, обрабатываемых в заданное время.
Поток пулов предлагает решение и проблемы издержек жизненного цикла потока, и проблемы пробуксовки ресурсов. При многократном использовании потоков для решения многочисленных задач, издержки создания потока распространяются на многие задачи. В качестве бонуса, поскольку поток уже существует, когда прибывает запрос, задержка, произошедшая из-за создания потока, устраняется. Таким образом, запрос может быть обработан немедленно, что делает приложение более быстрореагирующим. Более того, правильно настроив количество потоков в пуле потоков, вы можете предотвратить пробуксовку ресурсов, заставив любые запросы, если их количество выходит за определенные пределы, ждать до тех пор, пока поток не станет доступным, чтобы его обработать.
Как выбирать производителя твердотельных накопителей
Закрытие потоков
Последнее обновление: 25.04.2018
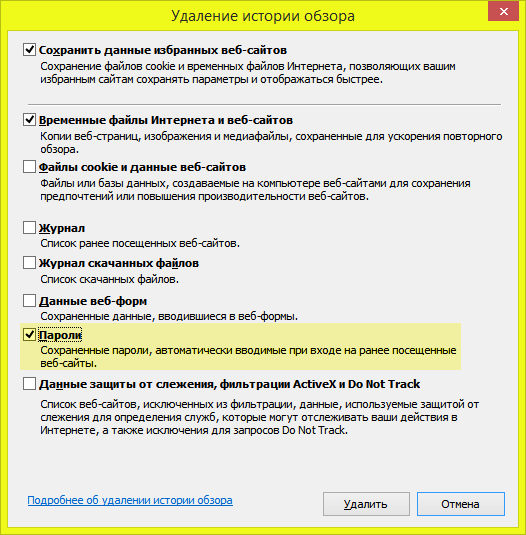
При завершении работы с потоком его надо закрыть с помощью метода close(), который определен в интерфейсе
Closeable. Метод close имеет следующее определение:
void close() throws IOException
Этот интерфейс уже реализуется в классах InputStream и OutputStream, а через них и во всех классах потоков.
При закрытии потока освобождаются все выделенные для него ресурсы, например, файл. В случае, если поток окажется не закрыт, может происходить утечка памяти.
Есть два способа закрытия файла. Первый традиционный заключается в использовании блока . Например, считаем данные из файла:
import java.io.*;
public class Program {
public static void main(String[] args) {
FileInputStream fin=null;
try
{
fin = new FileInputStream("C://SomeDir//notes.txt");
int i=-1;
while((i=fin.read())!=-1){
System.out.print((char)i);
}
}
catch(IOException ex){
System.out.println(ex.getMessage());
}
finally{
try{
if(fin!=null)
fin.close();
}
catch(IOException ex){
System.out.println(ex.getMessage());
}
}
}
}
Поскольку при открытии или считывании файла может произойти ошибка ввода-вывода, то код считывания помещается в блок try. И чтобы быть уверенным, что
поток в любом случае закроется, даже если при работе с ним возникнет ошибка, вызов метода помещается в блок .
И, так как метод также в случае ошибки может генерировать исключение IOException, то его вызов также помещается во вложенный блок
Начиная с Java 7 можно использовать еще один способ, который автоматически вызывает метод close. Этот способ заключается в использовании конструкции
try-with-resources (try-с-ресурсами). Данная конструкция работает с объектами, которые реализуют интерфейс .
Так как все классы потоков реализуют интерфейс , который в свою очередь наследуется от , то их также можно использовать в данной
конструкции
Итак, перепишем предыдущий пример с использованием конструкции try-with-resources:
import java.io.*;
public class Program {
public static void main(String[] args) {
try(FileInputStream fin=new FileInputStream("C://SomeDir//notes.txt"))
{
int i=-1;
while((i=fin.read())!=-1){
System.out.print((char)i);
}
}
catch(IOException ex){
System.out.println(ex.getMessage());
}
}
}
Синтаксис конструкции следующий: . Данная конструкция также не исключает
использования блоков .
После окончания работы в блоке try у ресурса (в данном случае у объекта ) автоматически вызывается метод close().
Если нам надо использовать несколько потоков, которые после выполнения надо закрыть, то мы можем указать объекты потоков через точку с запятой:
try(FileInputStream fin=new FileInputStream("C://SomeDir//Hello.txt");
FileOutputStream fos = new FileOutputStream("C://SomeDir//Hello2.txt"))
{
//..................
}
НазадВперед