2 способа корреляционного анализа в microsoft excel
Содержание:
- Литература
- 9.1.6. Корреляция, регрессия и причинность
- Коэффициенты ранговой корреляции
- Критерии и методы
- КРИТЕРИЙ СПИРМЕНА
- Выполняем корреляционный анализ
- Расчет коэффициента корреляции
- Hard Reset средствами самой системы Android
- Основная тенденция развития и методы ее выявления
- Пример применения метода корреляционного анализа
- Распространенные заблуждения
- Коэффициент корреляции частный, его значения
- 9.1.2. Проверка статистических гипотез о связи переменных
Литература
- Гмурман В. Е.<span title=»Статья «Гмурман, Владимир Ефимович» в русском разделе отсутствует»>ru</span>uk. Теория вероятностей и математическая статистика: Учебное пособие для вузов. — 10-е издание, стереотипное. — Москва: Высшая школа, 2004. — 479 с. — ISBN 5-06-004214-6.
- Елисеева И. И., Юзбашев М. М. Общая теория статистики: Учебник / Под ред. И. И. Елисеевой. — 4-е издание, переработанное и дополненное. — Москва: Финансы и Статистика, 2002. — 480 с. — ISBN 5-279-01956-9.
- Общая теория статистики: Учебник / Под ред. Р. А. Шмойловой. — 3-е издание, переработанное. — Москва: Финансы и Статистика, 2002. — 560 с. — ISBN 5-279-01951-8.
- Суслов В. И., Ибрагимов Н. М., Талышева Л. П., Цыплаков А. А. Эконометрия. — Новосибирск: СО РАН, 2005. — 744 с. — ISBN 5-7692-0755-8.
9.1.6. Корреляция, регрессия и причинность
Корреляция и регрессия — инструменты исследования связи, или согласованности двух переменных. Их возможности ограниченны. Сами по себе они никогда не смогут ничего сказать о направлении связи между переменными. Влияет ли уровень оптимизма на продолжительность жизни или, напротив, прогноз состояния организма, каким-то образом воспринимаемый его владельцем, влияет на уровень оптимизма — вопрос, на который нельзя ответить исходя только из корреляционных и регрессионных коэффициентов. Если ответ и возможен, то только с опорой на тонкие аспекты экспериментального дизайна.
>> следующий параграф>>
Здесь также можно различать двухсторонние и односторонние гипотезы, как в случае Т-критерия (см. подпараграф 7.1.5).
Для коэффициента корреляции так же, как и для других статистик, возможен расчет доверительных интервалов, показывающих, какие возможные значения истинной корреляции согласуются с выборочным. Смысл доверительного интервала тот же, что и в разобранных выше случаях, но техника расчета сложнее, поэтому мы не будем ее здесь давать.
В подпараграфе 9.3.1 практикума мы разберем эти операции на конкретном примере. Мы рекомендуем читателю сначала выполнить практическое задание, а затем вернуться к данному пункту.
В главе 7 \( S_{total} \) обозначала у нас сумму квадратов, включая сумму константы, здесь же \( S_{total} \) ее не включает. Это не наш недосмотр, так обозначаются суммы в соответствующих таблицах SPSS, на которые мы здесь ориентируемся. Чтобы уменьшить риск путаницы, мы в первом случае используем заглавную букву ’T’.
Не будем забывать, что наши данные содержат вклад случайных обстоятельств, поэтому при повторении исследования мы можем получить иные коэффициенты.
Коэффициенты ранговой корреляции
Коэффициенты ранговой корреляции , такие как коэффициент ранговой корреляции Спирмена и коэффициент ранговой корреляции Кендалла (τ), измеряют степень, в которой по мере увеличения одной переменной наблюдается тенденция к увеличению другой переменной, не требуя, чтобы это увеличение было представлено линейной зависимостью. Если по мере увеличения одной переменной другая уменьшается , коэффициенты ранговой корреляции будут отрицательными. Обычно эти коэффициенты ранговой корреляции рассматриваются как альтернативы коэффициенту Пирсона, используемому либо для уменьшения объема вычислений, либо для того, чтобы сделать коэффициент менее чувствительным к ненормальности в распределениях. Однако у этого взгляда мало математического обоснования, поскольку коэффициенты ранговой корреляции измеряют другой тип взаимосвязи, чем коэффициент корреляции продукта-момента Пирсона , и лучше всего рассматриваются как меры другого типа ассоциации, а не как альтернативный показатель совокупности. коэффициент корреляции.
Чтобы проиллюстрировать природу ранговой корреляции и ее отличие от линейной корреляции, рассмотрим следующие четыре пары чисел :
(Икс,у){\ Displaystyle (х, у)}
- (0, 1), (10, 100), (101, 500), (102, 2000).
По мере того, как мы переходим от каждой пары к следующей, увеличивается, и то же самое . Это соотношение является совершенным, в том смысле , что увеличение будет всегда сопровождается увеличением . Это означает, что у нас есть идеальная ранговая корреляция, и коэффициенты корреляции Спирмена и Кендалла равны 1, тогда как в этом примере коэффициент корреляции произведение-момент Пирсона равен 0,7544, что указывает на то, что точки далеко не лежат на прямой линии. Таким же образом, если всегда уменьшается при увеличении , коэффициенты ранговой корреляции будут равны -1, в то время как коэффициент корреляции момента произведения Пирсона может быть или не может быть близок к -1, в зависимости от того, насколько близки точки к прямой линии. Хотя в крайних случаях идеальной ранговой корреляции оба коэффициента равны (оба +1 или оба -1), обычно это не так, и поэтому значения двух коэффициентов не могут быть осмысленно сравнены. Например, для трех пар (1, 1) (2, 3) (3, 2) коэффициент Спирмена равен 1/2, а коэффициент Кендалла равен 1/3.
Икс{\ displaystyle x}у{\ displaystyle y}Икс{\ displaystyle x}у{\ displaystyle y}у{\ displaystyle y}Икс{\ displaystyle x}
Критерии и методы
КРИТЕРИЙ СПИРМЕНА
Коэффициент ранговой корреляции Спирмена – это непараметрический метод, который используется с целью статистического изучения связи между явлениями. В этом случае определяется фактическая степень параллелизма между двумя количественными рядами изучаемых признаков и дается оценка тесноты установленной связи с помощью количественно выраженного коэффициента.
Чарльз Эдвард Спирмен
1. История разработки коэффициента ранговой корреляции
Данный критерий был разработан и предложен для проведения корреляционного анализа в 1904 году Чарльзом Эдвардом Спирменом, английским психологом, профессором Лондонского и Честерфилдского университетов.
2. Для чего используется коэффициент Спирмена?
Коэффициент ранговой корреляции Спирмена используется для выявления и оценки тесноты связи между двумя рядами сопоставляемых количественных показателей. В том случае, если ранги показателей, упорядоченных по степени возрастания или убывания, в большинстве случаев совпадают (большему значению одного показателя соответствует большее значение другого показателя — например, при сопоставлении роста пациента и его массы тела), делается вывод о наличии прямой корреляционной связи. Если ранги показателей имеют противоположную направленность (большему значению одного показателя соответствует меньшее значение другого — например, при сопоставлении возраста и частоты сердечных сокращений), то говорят об обратной связи между показателями.
- Коэффициент корреляции Спирмена обладает следующими свойствами:
- Коэффициент корреляции может принимать значения от минус единицы до единицы, причем при rs=1 имеет место строго прямая связь, а при rs= -1 – строго обратная связь.
- Если коэффициент корреляции отрицательный, то имеет место обратная связь, если положительный, то – прямая связь.
- Если коэффициент корреляции равен нулю, то связь между величинами практически отсутствует.
- Чем ближе модуль коэффициента корреляции к единице, тем более сильной является связь между измеряемыми величинами.
3. В каких случаях можно использовать коэффициент Спирмена?
В связи с тем, что коэффициент является методом непараметрического анализа, проверка на нормальность распределения не требуется.
Сопоставляемые показатели могут быть измерены как в непрерывной шкале (например, число эритроцитов в 1 мкл крови), так и в порядковой (например, баллы экспертной оценки от 1 до 5).
Эффективность и качество оценки методом Спирмена снижается, если разница между различными значениями какой-либо из измеряемых величин достаточно велика. Не рекомендуется использовать коэффициент Спирмена, если имеет место неравномерное распределение значений измеряемой величины.
4. Как рассчитать коэффициент Спирмена?
Расчет коэффициента ранговой корреляции Спирмена включает следующие этапы:
- Сопоставить каждому из признаков их порядковый номер (ранг) по возрастанию или убыванию.
- Определить разности рангов каждой пары сопоставляемых значений (d).
- Возвести в квадрат каждую разность и суммировать полученные результаты.
- Вычислить коэффициент корреляции рангов по формуле:
Определить статистическую значимость коэффициента при помощи t-критерия, рассчитанного по следующей формуле:
5. Как интерпретировать значение коэффициента Спирмена?
При использовании коэффициента ранговой корреляции условно оценивают тесноту связи между признаками, считая значения коэффициента меньше 0,3 — признаком слабой тесноты связи; значения более 0,3, но менее 0,7 — признаком умеренной тесноты связи, а значения 0,7 и более — признаком высокой тесноты связи.
Также для оценки тесноты связи может использоваться шкала Чеддока:
xy
Теснота (сила) корреляционной связи
менее 0.3
слабая
от 0.3 до 0.5
умеренная
от 0.5 до 0.7
заметная
от 0.7 до 0.9
высокая
более 0.9
весьма высокая
Статистическая значимость полученного коэффициента оценивается при помощи t-критерия Стьюдента. Если расчитанное значение t-критерия меньше табличного при заданном числе степеней свободы, статистическая значимость наблюдаемой взаимосвязи — отсутствует. Если больше, то корреляционная связь считается статистически значимой.
Выполняем корреляционный анализ
Для изучения и лучшего понимания корреляционного анализа, давайте попробуем его выполнить для таблицы ниже.
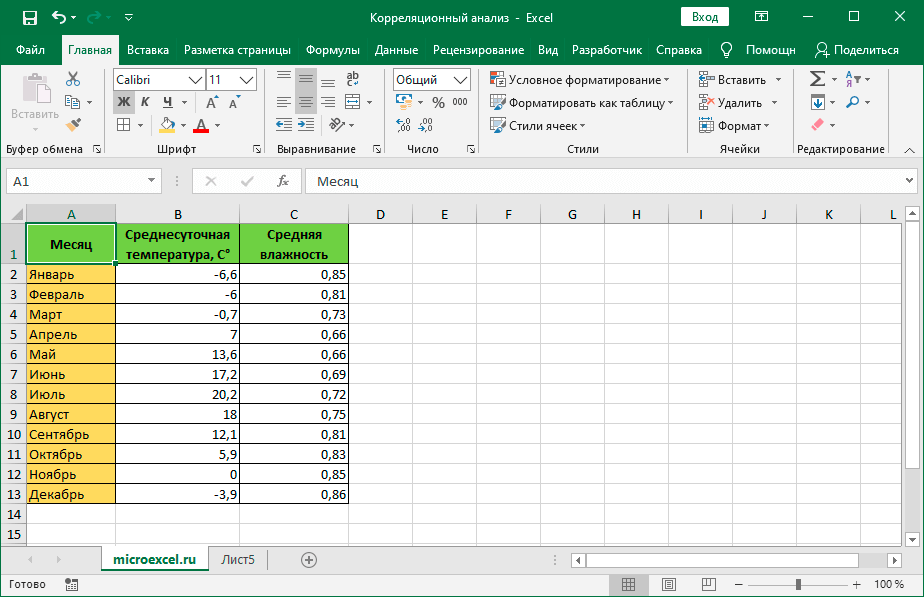
Здесь указаны данные по среднесуточной температуре и средней влажности по месяцам года. Наша задача – выяснить, существует ли связь между этими параметрами и, если да, то насколько сильная.
Метод 1: применяем функцию КОРРЕЛ
В Excel предусмотрена специальная функция, позволяющая сделать корреляционный анализ – КОРРЕЛ. Ее синтаксис выглядит следующим образом:
Порядок действий при работе с данным инструментом следующий:
- Встаем в свободную ячейку таблицы, в которой планируем рассчитать коэффициент корреляции. Затем щелкаем по значку “fx (Вставить функцию)” слева от строки формул.
- В открывшемся окне вставки функции выбираем категорию “Статистические” (или “Полный алфавитный перечень”), среди предложенных вариантов отмечаем “КОРРЕЛ” и щелкаем OK.
- На экране отобразится окно аргументов функции с установленным курсором в первом поле напротив “Массив 1”. Здесь мы указываем координаты ячеек первого столбца (без шапки таблицы), данные которого требуется проанализировать (в нашем случае – B2:B13). Сделать это можно вручную, напечатав нужные символы с помощью клавиатуры. Также выделить требуемый диапазон можно непосредственно в самой таблице с помощью зажатой левой кнопки мыши. Затем переходим ко второму аргументу “Массив 2”, просто щелкнув внутри соответствующего поля либо нажав клавишу Tab. Здесь указываем координаты диапазона ячеек второго анализируемого столбца (в нашей таблице – это C2:C13). По готовности щелкаем OK.
- Получаем коэффициент корреляции в ячейке с функцией. Значение “-0,63” свидетельствует об умеренно-сильной обратной зависимости между анализируемыми данными.
Метод 2: используем “Пакет анализа”
Альтернативным способом выполнения корреляционного анализа является использование “Пакета анализа”, который предварительно нужно включить. Для этого:
- Заходим в меню “Файл”.
- В перечне слева выбираем пункт “Параметры”.
- В появившемся окне кликаем по подразделу “Надстройки”. Затем в правой части окна в самом низу для параметра “Управление” выбираем “Надстройки Excel” и щелкаем “Перейти”.
- В открывшемся окошке отмечаем “Пакет анализа” и подтверждаем действие нажатием кнопки OK.
Все готово, “Пакет анализа” активирован. Теперь можно перейти к выполнению нашей основной задачи:
- Нажимаем кнопку “Анализ данных”, которая находится во вкладке “Данные”.
- Появится окно, в котором представлен перечень доступных вариантов анализа. Отмечаем “Корреляцию” и щелкаем OK.
- На экране отобразится окно, в котором необходимо указать следующие параметры:
- “Входной интервал”. Выделяем весь диапазон анализируемых ячеек (т.е. сразу оба столбца, а не по одному, как это было в описанном выше методе).
- “Группирование”. На выбор предложено два варианта: по столбцам и строкам. В нашем случае подходит первый вариант, т.к. именно подобным образом расположены анализируемые данные в таблице. Если в выделенный диапазон включены заголовки, следует поставить галочку напротив пункта “Метки в первой строке”.
- “Параметры вывода”. Можно выбрать вариант “Выходной интервал”, в этом случае результаты анализа будут вставлены на текущем листе (потребуется указать адрес ячейки, начиная с которой будут выведены итоги). Также предлагается вывод результатов на новом листе или в новой книге (данные будут вставлены в самом начале, т.е. начиная с ячейки A1). В качестве примера оставляем “Новый рабочий лист” (выбран по умолчанию).
- Когда все готово, щелкаем OK.
- Получаем тот же самый коэффициент корреляции, что и в первом методе. Это говорит о том, что в обоих случаях мы все сделали верно.
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
В открывшемся окне перемещаемся в раздел «Параметры».
Далее переходим в пункт «Надстройки».
В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Hard Reset средствами самой системы Android
Основная тенденция развития и методы ее выявления
Каждый ряд динамики
имеет свою тенденцию развития, т.е. общее
направление к росту, снижению или
стабилизации уровня явления с течением
времени. Степень выраженности этой
тенденции зависит от влияния постоянных,
периодических (сезонных) и случайных
факторов на уровни ряда динамики. Поэтому
следует говорить не просто о тенденции
развития, а об основной тенденции.
Основной
тенденцией развития (трендом)
называется плавное и устойчивое изменение
уровня явления во времени, свободное
от периодических и случайных колебаний.
Для выявления
тренда ряды динамики подвергаются
обработке методами укрупнения интервалов,
скользящей средней, аналитического
выравнивания.
Метод укрупнения
интервалов основан
на укрупнении периодов времени, к которым
относятся уровни ряда динамики. Для
этого исходные данные объединяются,
т.е. суммируются или усредняются за
более продолжительные интервалы времени,
пока общая тенденция развития не станет
достаточно отчетливой. Например, дневные
данные о производстве продукции
объединяются в декадные, месячные в
квартальные, годовые в многолетние.
Достоинство метода в его простоте.
Недостаток в том, что сглаженный ряд
существенно короче исходного.
Метод скользящей
средней
состоит в том, что на основе исходных
данных рассчитываются подвижные средние
из определенного числа сначала первых
по счету уровней ряда, затем из такого
же числа уровней, начиная со второго,
с третьего и т.д. Средняя величина как
бы скользит по динамическому ряду,
передвигаясь на один интервал. В
скользящих средних сглаживаются
случайные колебания.
Схема расчета
3-х уровневой скользящей средней величины
|
Интервал (номер |
Фактические уi |
Скользящие уск |
|
1 |
у1 |
— |
|
2 |
у2 |
|
|
3 |
у3 |
|
|
4 |
у4 |
уск3 |
|
5 |
у5 |
уск4 |
|
6 |
у6 |
— |


Сглаженный ряд
динамики короче исходного на величину
(l – 1),
если укрупнение производится по нечетному
числу уровней, где l
– длина периода укрупнения. Например,
если l = 3,
то выровненный ряд на 2 уровня короче.
Таким образом сглаженный ряд не на много
короче исходного.
Метод
аналитического выравнивания
заключается в замене фактических уровней
ряда динамики их теоретическими
значениями, вычисленными на основе
уравнения тренда:
Расчет параметров
уравнения производится методом
наименьших квадратов:

гдеу
– фактические уровни;уti
– соответствующие им во времени
выровненные (расчетные) уровни.
Если развитие
осуществляется в арифметической
прогрессии (с равными цепными абсолютными
приростами), то для выравнивания
используют линейную
функцию:

Если наблюдается
динамика в геометрической прогрессии,
(с равными цепными темпами роста), то
необходимо использовать показательную
функцию:
уt
= аа1t.
Если развитие
происходит с равными темпами прироста,
используется степенная
функция,
например второго порядка (парабола):
уt
= а
+ а1t
+ а2t2.
Критерием
правильности выбора уравнения тренда
служит ошибка
аппроксимации.
Она представляет собой среднее
квадратическое отклонение фактических
уровней ряда динамики от теоретических:

Оптимальным
считается уравнение с наименьшей ошибкой
аппроксимации.
Рассмотрим «технику»
выравнивания ряда динамики по линейной
функции:

где
а,
а1
– параметры уравнения прямой; t
– показатели времени (как правило,
порядковый номер периода или момента
времени).
Параметры прямойа
и а1,
удовлетворяющие методу наименьших
квадратов, находят решением следующей
системы нормальных уравнений:

где
n
– число уровней ряда динамики; параметр
а1
соответствует среднему абсолютному
приросту.
Для упрощения
расчета показателям времени
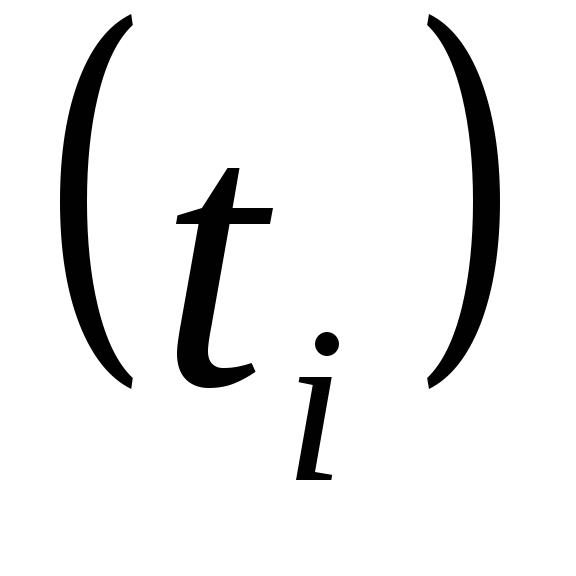
можно придать такие
значения, при которых
 ,
,
тогда
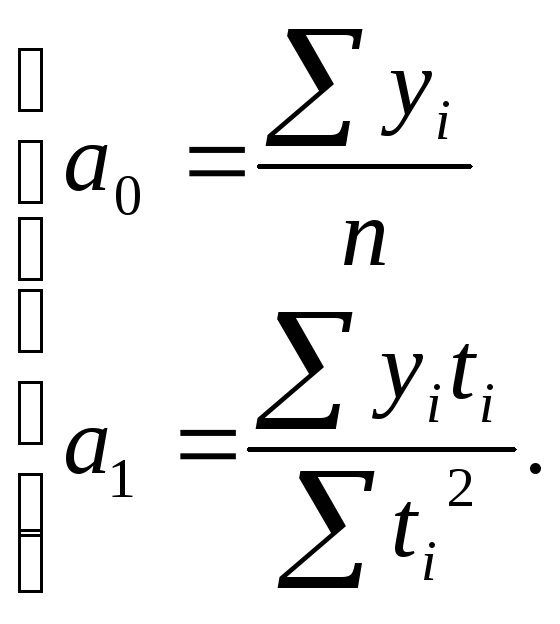
Для этого в рядах
с нечетным числом
уровней за начало отсчета времени
принимают центральный интервал, гдеtприравнивают
к нулю. По обе
стороны от нуля располагают соответственно
ряды отрицательных и положительных
натуральных чисел, например:
|
Интервал (номер |
ti |
|
1 |
-3 |
|
2 |
-2 |
|
3 |
-1 |
|
4 |
|
|
5 |
1 |
|
6 |
2 |
|
7 |
3 |
|
Итого |
При четном числе
уровней отсчет ведется от двух центральных
интервалов, в которых t
приравнено к (-1) и (+1) соответственно, а
по обе стороны располагаются ряды
отрицательных и положительных нечетных
чисел, например:
|
Интервал (номер |
ti |
|
1 |
-5 |
|
2 |
-3 |
|
3 |
-1 |
|
4 |
1 |
|
5 |
3 |
|
6 |
5 |
|
Итого |
Схема расчета
параметров линейного уравнения
|
Интервалы |
Уровни уi |
ti |
it2 |
уiti |
уti |
|
Итого |
На основе исчисленного
уравнения тренда можно производить
экстраполяцию
– нахождение вероятностных (прогнозируемых)
уровней за пределами исходного ряда
динамики.
Пример применения метода корреляционного анализа
В Великобритании было предпринято любопытное исследование. Оно посвящено связи курения с раком легких, и проводилось путем корреляционного анализа. Это наблюдение представлено ниже.
|
Профессиональная группа |
курение |
смертность |
|
Фермеры, лесники и рыбаки |
77 |
84 |
|
Шахтеры и работники карьеров |
137 |
116 |
|
Производители газа, кокса и химических веществ |
117 |
123 |
|
Изготовители стекла и керамики |
94 |
128 |
|
Работники печей, кузнечных, литейных и прокатных станов |
116 |
155 |
|
Работники электротехники и электроники |
102 |
101 |
|
Инженерные и смежные профессии |
111 |
118 |
|
Деревообрабатывающие производства |
93 |
113 |
|
Кожевенники |
88 |
104 |
|
Текстильные рабочие |
102 |
88 |
|
Изготовители рабочей одежды |
91 |
104 |
|
Работники пищевой, питьевой и табачной промышленности |
104 |
129 |
|
Производители бумаги и печати |
107 |
86 |
|
Производители других продуктов |
112 |
96 |
|
Строители |
113 |
144 |
|
Художники и декораторы |
110 |
139 |
|
Водители стационарных двигателей, кранов и т. д. |
125 |
113 |
|
Рабочие, не включенные в другие места |
133 |
146 |
|
Работники транспорта и связи |
115 |
128 |
|
Складские рабочие, кладовщики, упаковщики и работники разливочных машин |
105 |
115 |
|
Канцелярские работники |
87 |
79 |
|
Продавцы |
91 |
85 |
|
Работники службы спорта и отдыха |
100 |
120 |
|
Администраторы и менеджеры |
76 |
60 |
|
Профессионалы, технические работники и художники |
66 |
51 |
Начинаем корреляционный анализ. Решение лучше начинать для наглядности с графического метода, для чего построим диаграмму рассеивания (разброса).
Она демонстрирует прямую связь. Однако на основании только графического метода сделать однозначный вывод сложно. Поэтому продолжим выполнять корреляционный анализ. Пример расчета коэффициента корреляции представлен ниже.
С помощью программных средств (на примере MS Excel будет описано далее) определяем коэффициент корреляции, который составляет 0,716, что означает сильную связь между исследуемыми параметрами. Определим статистическую достоверность полученного значения по соответствующей таблице, для чего нам нужно вычесть из 25 пар значений 2, в результате чего получим 23 и по этой строке в таблице найдем r критическое для p=0,01 (поскольку это медицинские данные, здесь используется более строгая зависимость, в остальных случаях достаточно p=0,05), которое составляет 0,51 для данного корреляционного анализа. Пример продемонстрировал, что r расчетное больше r критического, значение коэффициента корреляции считается статистически достоверным.
Распространенные заблуждения
Корреляция и причинность
Традиционное изречение, что « корреляция не подразумевает причинно-следственную связь », означает, что корреляция не может использоваться сама по себе для вывода причинной связи между переменными. Это изречение не следует понимать как то, что корреляции не могут указывать на возможное существование причинно-следственных связей. Однако причины, лежащие в основе корреляции, если таковые имеются, могут быть косвенными и неизвестными, а высокие корреляции также пересекаются с отношениями идентичности ( тавтологиями ), где не существует причинного процесса. Следовательно, корреляция между двумя переменными не является достаточным условием для установления причинной связи (в любом направлении).
Корреляция между возрастом и ростом у детей довольно прозрачна с точки зрения причинно-следственной связи, но корреляция между настроением и здоровьем людей менее очевидна. Приводит ли улучшение настроения к улучшению здоровья, или хорошее здоровье приводит к хорошему настроению, или и то, и другое? Или в основе обоих лежит какой-то другой фактор? Другими словами, корреляция может рассматриваться как свидетельство возможной причинной связи, но не может указывать на то, какой может быть причинная связь, если таковая имеется.
Простые линейные корреляции
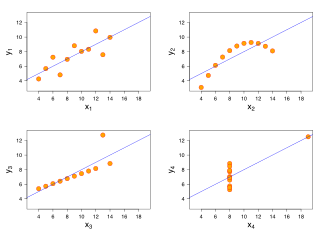
Четыре набора данных с одинаковой корреляцией 0,816
Коэффициент корреляции Пирсона указывает на силу линейной связи между двумя переменными, но его значение, как правило, не полностью характеризует их взаимосвязь. В частности, если условное среднее из дано , обозначается , не является линейным в , коэффициент корреляции будет не в полной мере определить форму .
Y{\ displaystyle Y}Икс{\ displaystyle X}E(Y∣Икс){\ displaystyle \ operatorname {E} (Y \ mid X)}Икс{\ displaystyle X}E(Y∣Икс){\ displaystyle \ operatorname {E} (Y \ mid X)}
Прилегающие изображение показывает разброс участков из квартет энскомбы , набор из четырех различных пар переменных , созданный Фрэнсис Анскомбами . Четыре переменные имеют одинаковое среднее значение (7,5), дисперсию (4,12), корреляцию (0,816) и линию регрессии ( y = 3 + 0,5 x ). Однако, как видно на графиках, распределение переменных сильно отличается. Первый (вверху слева), кажется, распределен нормально и соответствует тому, что можно было бы ожидать, рассматривая две коррелированные переменные и следуя предположению о нормальности. Второй (вверху справа) не распространяется нормально; Хотя можно наблюдать очевидную связь между двумя переменными, она не является линейной. В этом случае коэффициент корреляции Пирсона не указывает на то, что существует точная функциональная связь: только степень, в которой эта связь может быть аппроксимирована линейной зависимостью. В третьем случае (внизу слева) линейная зависимость идеальна, за исключением одного выброса, который оказывает достаточное влияние, чтобы снизить коэффициент корреляции с 1 до 0,816. Наконец, четвертый пример (внизу справа) показывает другой пример, когда одного выброса достаточно для получения высокого коэффициента корреляции, даже если связь между двумя переменными не является линейной.
у{\ displaystyle y}
Эти примеры показывают, что коэффициент корреляции, как сводная статистика, не может заменить визуальный анализ данных. Иногда говорят, что примеры демонстрируют, что корреляция Пирсона предполагает, что данные следуют нормальному распределению , но это неверно.
Коэффициент корреляции частный, его значения
Частные коэффициенты корреляции используются для отслеживания взаимосвязи изменения величины от множества факторов. Можно сказать, то частный коэффициент показывает степень тесноты связи в случае, когда все остальные признаки исключены из рассматриваемого множества.
Частые коэффициенты могут применяться при отборе факторов воздействия, определении степени их значимости при воздействии на изучаемый объект. Для этих целей строится уравнение репрессии, которое отслеживает факторы по размеру их коэффициента. На каждом шаге исключается частный корреляционный коэффициент с наименьшим значением.
Перед применением частных коэффициентов множество данных тестируется на установление линейных связей. Если связи отсутствуют, то далее осуществляет анализ связи исследуемого объекта и факторов. Частные коэффициенты взаимосвязей позволяют сопоставить взаимное влияние величин и факторов друг на друга для общих отношений и частных соприкосновений.
Значения частного коэффициента корреляции означают следующее:
- Если R = 0, то взаимосвязь нейтральная, влияния нет.
- Значение коэффициента в промежутке от 0,09 до 0,19 говорит о незначительной слабой связи.
- Слабая связь устанавливается в диапазоне от 0,19 до 0,49
- Средняя взаимосвязь от 0,49 до 0,69
- Сильная связь от 0,69 до 0, 99.
Замечание 2
Частный коэффициент корреляции применяется в эконометрике для того, чтобы отслеживать изменение экономического процесса или явления под воздействием внутренних и внешних факторов.
9.1.2. Проверка статистических гипотез о связи переменных
Выборочный коэффициент корреляции оценивает подразумеваемую исследователем реальную связь между переменными. Как и в случае оценки среднего значения, нас интересуют два вопроса: (1) Насколько сильна связь между переменными; (2) Насколько надежна наша оценка. Сила связи между переменными по всей генеральной совокупности существует объективно. Если ее измерять корреляцией, то она будет выражаться числом от −1 до 1. Выборочная корреляция этих переменных будет колебаться вокруг истинного показателя силы связи. Трудность состоит в том, что, получив выборочную корреляцию, мы не можем знать, ни насколько она отклоняется от истинного значения, ни даже в какую сторону. В случае корреляции оценка обычно выражается в терминах значимости.
Проделаем небольшое упражнение.
Упражнение 9.1.2(1). Возьмите две симметричные монеты достоинством в один рубль и один евро. Проведите серию четырех подбрасываний пары монет и запишите результаты в виде \( (x_1, y_1),\dots,(x_4, y_4) \) , полагая
\( x_i=0 \), если рубль выпал цифрой;
\( x_i=1 \), если рубль выпал гербом;
\( y_i=0 \), если евро выпал цифрой;
\( y_i=1 \), если евро выпал гербом.
Подсчитайте коэффициент корреляции Пирсона. Истинная корреляция между результатами двух монет равна, разумеется, нулю. Повторите процедуру несколько раз и убедитесь, что нулевое значение выборочного коэффициента корреляции выпадает примерно один раз из трех. При многократном повторении опыта можно убедиться, что его результат имеет некоторое распределение, симметричное относительно нуля. Это распределение зависит от объема выборки n: чем больше n, тем меньше дисперсия распределения, тем ближе к нулю ее вероятные значения.
В таблице 9.1.2(2) приведены двухсторонние квантили распределения выборочного коэффициента корреляции по Пирсону для \( n=10 \). Они рассчитаны для выборок, полученных испытаниями двух нормально распределенных случайных величин, теоретическая корреляция между которыми равна нулю. Дихотомический результат подбрасывания монеты не распределен нормально, однако некоторое представление о возможных результатах наших испытаний табличный квантиль все же дает.
Таблица 9.1.2(2) Двусторонние квантили распределения коэффициента Пирсона для n = 10
| \( \alpha \) | 0.05 | 0.025 | 0.01 | 0.005 |
| \( r_\alpha(10) \) | 0.497 | 0.576 | 0.658 | 0.709 |
Обычно при исследовании связи переменных статистической гипотезой \( H_0 \) будет гипотеза об отсутствии связи, т.е. о независимости переменных. Альтернативная гипотеза \( H_1 \) (т.е. гипотеза, к которой мы склоняемся, получив большие по модулю значения выборочной корреляции) будет утверждать только наличие связи . Можно оценить значимость относительно данного результата (полученной парной выборки) гипотез о других значениях теоретической корреляции, но это требует некоторых дополнительных усилий (см. подпараграф ). Если истинна гипотеза \( H_0 \), то выборочный коэффициент корреляции будет принимать значения, более или менее близкие к нулю. Если выборочная корреляция принимает достаточно большое по модулю значение, которому соответствует значимость, измеряемая маленьким числом, то мы склоняемся к гипотезе \( H_1 \) о наличии связи, но без указания точного значения теоретической корреляции.
Можно заметить, что если верна гипотеза об отсутствии зависимости между случайными величинами, то выборочный коэффициент при \( n=10 \) может принимать тем не менее довольно большие значения, так что уровень значимости 0.05 для принятия гипотезы о зависимости случайных величин требует, чтобы выборочный коэффициент корреляции достигал почти 0.5 (см. ). В связи с этим надо иметь в виду, что даже выборочная корреляция, например 0.6, вполне может согласовываться с истинной корреляцией, равной 0.2 .