Как парсить сайт: 20+ инструментов на все случаи жизни
Содержание:
- Как парсить сайты
- Loading URLs
- Version 2.1.0 (2016-04-19)
- 10. Мэрилин Монро
- PHP включают примеры
- Извлечение информации из заголовков при использовании cURL
- Сервис яндекс картинки. Инструкция по поиску и скачиванию картинок
- Парсеры сайтов в зависимости от используемой технологии
- Private Tunnel
- API Reference
- cURL и аутентификация в веб-формах (передача данных методом GET и POST)
- Реализация парсера на PHP
- Contributors/Thanks to
- How to find HTML elements?
- Options
- Проблемы совместимости карты памяти и читающего устройства
- Version 3.0.0-beta1 (2016-09-16)
- Google Фото – лучшее бесплатное хранилище для фото и видео
- Motorola Moto G8 Plus
- Неправильная кодировка при использовании cURL
- Генри Форд — Моя жизнь, мои достижения
- Делаем запросы
- Version 4.4.0 (2020-04-10)
- Version 4.1.0 (2018-10-10)
- Learn more
- Системный реестр
Как парсить сайты
Я долго не хотел писать эту статью, поскольку конкретного смысла в ней нет. Чтобы сделать парсер на PHP, нужно знать этот язык. А те, кто его знает, такой вопрос просто не зададут. Но в этой статье я расскажу, как вообще создаются парсеры, а также, что конкретно нужно изучать.
Итак, вот список пунктов, которые необходимо пройти, чтобы создать парсер контента на PHP:
- Получить содержимое страницы и записать его в строковую переменную. Наиболее простой вариант — это функция file_get_contents(). Если контент доступен только авторизованным пользователям, то тут всё несколько сложнее. Здесь уже надо посмотреть, каков механизм авторизации. Далее, используя cURL, отправить правильный запрос на форму авторизации, получить ответ и затем отправить правильные заголовки (например, полученный идентификатор сессии), а также в этом же запросе обратиться к той странице, которая нужна. Тогда уже в этом ответе Вы получите конечную страницу.
- Изучить структуру страницы. Вам нужно найти контент, который Вам необходим и посмотреть, в каком блоке он находится. Если блок, в котором он находится не уникален, то найти другие общие признаки, по которым Вы однозначно сможете сказать, что если строка удовлетворяет им, то это то, что Вам и нужно.
- Используя строковые функции, достать из исходной строки нужный Вам контент по признакам, найденным во 2-ом пункте.
Отмечу так же, что всё это поймёт и сможет применить на практике только тот, кто знает PHP. Поэтому те, кто его только начинает изучать, Вам потребуются следующие знания:
- Строковые функции.
- Библиотека cURL, либо её аналог.
- Отличное знание HTML.
Те же, кто ещё вообще не знает PHP, то до парсеров в этом случае ещё далеко, и нужно изучать всю базу. В этом Вам поможет мой курс, либо какие-нибудь книги по PHP.
Безусловно, Америки я в этой статье не открыл, но слишком много вопросов по теме парсеров, поэтому этой статьёй я постарался лишь дать развёрнутый ответ.
Loading URLs
Loading a URL is very similar to the way you would load the HTML from a file.
// Assuming you installed from Composer:
require "vendor/autoload.php";
use PHPHtmlParser\Dom;
$dom = new Dom;
$dom->loadFromUrl('http://google.com');
$html = $dom->outerHtml;
// or
$dom->loadFromUrl('http://google.com');
$html = $dom->outerHtml; // same result as the first example
loadFromUrl will, by default, use an implementation of the to do the HTTP request and a default implementation of to create the body of the request. You can easily implement your own version of either the client or request to use a custom HTTP connection when using loadFromUrl.
// Assuming you installed from Composer:
require "vendor/autoload.php";
use PHPHtmlParser\Dom;
use App\Services\MyClient;
$dom = new Dom;
$dom->loadFromUrl('http://google.com', null, new MyClient());
$html = $dom->outerHtml;
As long as the client object implements the interface properly, it will use that object to get the content of the url.
Version 2.1.0 (2016-04-19)
Fixed
- Properly support strings (with uppercase ) in a number of places.
- Fixed reformatting of indented parts in a certain non-standard comment style.
Added
- Added option to node dumper, to enable dumping of comments associated with nodes.
- Added node, that is used to collect comments located at the end of a block or at the
end of a file (without a following node with which they could otherwise be associated). - Added attribute to to distinguish between and .
- Added attribute to to distinguish between decimal, binary, octal and
hexadecimal numbers. - Added attribute to to distinguish between and .
- Added attribute to and to distinguish between
single-quoted, double-quoted, heredoc and nowdoc string. - Added attribute to and , if it is a heredoc or
nowdoc string. - Added start file offset information to nodes.
- Added method to function and method builders.
- Added and options to script.
Changed
- Invalid octal literals now throw a parse error in PHP 7 mode.
- The pretty printer takes all the new attributes mentioned in the previous section into account.
- The protected method no longer returns a trailing newline.
- The bundled autoloader supports library files being stored in a different directory than
for easier downstream distribution.
Removed
The internal (but public) method Scalar\LNumber::parse() has been removed. A non-internal
LNumber::fromString() method has been added instead.
10. Мэрилин Монро
PHP включают примеры
Пример 1
Предположим, что у нас есть стандартный файл нижнего колонтитула под названием «Footer. php», который выглядит следующим:
<?phpecho «<p>Copyright © 1999-» . date(«Y») . » html5css.com</p>»;?>
To include the footer file in a page, use the statement:
Пример
<html>
<body>
<h1>Welcome to my home page!</h1>
<p>Some text.</p><p>Some more text.</p><?php include ‘footer.php’;?>
</body>
</html>
Пример 2
Предположим, что у нас есть стандартный файл меню под названием «Menu. php»:
<?phpecho ‘<a href=»/default.php»>Home</a> -<a href=»/html/default.php»>HTML Tutorial</a> -<a href=»/css/default.php»>CSS Tutorial</a> -<a href=»/js/default.php»>JavaScript Tutorial</a> -<a href=»default.php»>PHP Tutorial</a>’;?>
Все страницы веб-узла должны использовать этот файл меню. Вот как это может быть сделано (мы используем элемент < div >, так что меню легко может быть стилизовано с CSS позже):
Пример
<html>
<body>
<div class=»menu»><?php include ‘menu.php’;?></div>
<h1>Welcome to my home page!</h1><p>Some text.</p><p>Some more text.</p>
</body>
</html>
Пример 3
Предположим, что у нас есть файл под названием «Files. php», с определенными переменными:
<?php
$color=’red’;
$car=’BMW’;
?>
Затем, если мы включаем файл «Files. php», переменные могут быть использованы в вызывающем файле:
Пример
<html>
<body>
<h1>Welcome to my home page!</h1>
<?php include ‘vars.php’;
echo «I have a $color $car.»;?>
</body>
</html>
Извлечение информации из заголовков при использовании cURL
Иногда необходимо извлечь информацию из заголовка, либо просто узнать, куда делается перенаправление.
Заголовки – это некоторая техническая информация, которой обмениваются клиент (веб-браузер или программа curl) с веб-приложением (веб-сервером). Обычно нам не видна эта информация, она включает в себя такие данные как кукиз, перенаправления (редиректы), данные о User Agent, кодировка, наличие сжатия, информация о рукопожатии при использовании HTTPS, версия HTTP и т.д.
Пример команды:
curl -s -I -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' https://www.acrylicwifi.com/AcrylicWifi/UpdateCheckerFree.php?download | grep -i '^location'
Получаемый результат:
location: https://tarlogiccdn.s3.amazonaws.com/AcrylicWiFi/Home/Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe
В этой команде имеются уже знакомые нам опции -s (подавление вывода) и -A (для указания своего пользовательского агента).
Новой опцией является -I, которая означает показывать только заголовки. Т.е. не будет показываться HTML код, поскольку он нам не нужен.
На этом скриншоте видно, в какой именно момент отправляется информация о новой ссылке для перехода:

curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' 2>&1 | grep -i 'Location:'
Обратите внимание, что в этой команде не использовалась опция -I, поскольку она вызывает ошибку:
Warning: You can only select one HTTP request method! You asked for both POST Warning: (-d, --data) and HEAD (-I, --head).
Суть ошибки в том, что можно выбрать только один метод запроса HTTP, а используются сразу два: POST и HEAD.
Кстати, опция -d (её псевдоним упоминался выше (—data), когда мы говорили про HTML аутентификацию через формы на веб-сайтах), передаёт данные методом POST, т.е. будто бы нажали на кнопку «Отправить» на веб-странице.
В последней команде используется новая для нас опция -v, которая увеличивает вербальность, т.е. количество показываемой информации. Но особенностью опции -v является то, что она дополнительные сведения (заголовки и прочее) выводит не в стандартный вывод (stdout), а в стандартный вывод ошибок (stderr). Хотя в консоли всё это выглядит одинаково, но команда grep перестаёт анализировать заголовки (как это происходит в случае с -I, которая выводит заголовки в стандартный вывод). В этом можно убедиться используя предыдущую команду без 2>&1:
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' | grep -i 'Location:'
Строка с Location никогда не будет найдена, хотя на экране она явно присутствует.
Конструкция 2>&1 перенаправляет стандартный вывод ошибок в стандартный вывод, в результате внешне ничего не меняется, но теперь grep может обрабатывать эти строки.
Более сложная команда для предыдущего обработчика форм (попробуйте в ней разобраться самостоятельно):
timeout 10 curl -s -L -v http://www.paterva.com/web7/downloadPaths.php -d 'fileType=exe&client=ce&os=Windows' -e 'www.paterva.com/web7/downloads.php' 2>&1 >/dev/null | grep -E 'Location:'
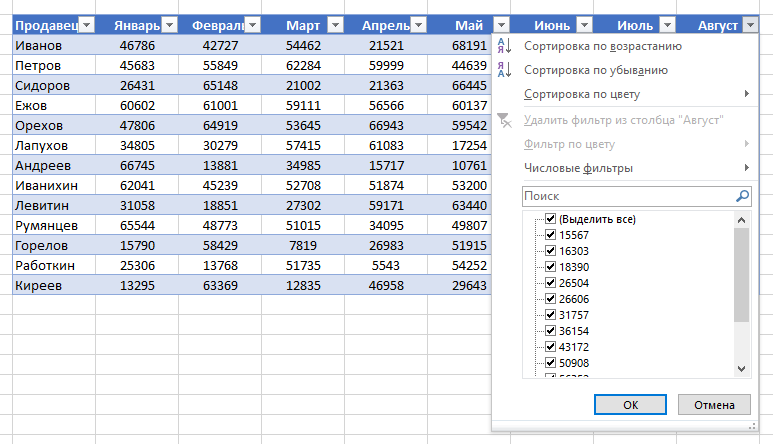
Сервис яндекс картинки. Инструкция по поиску и скачиванию картинок
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Private Tunnel
API Reference
Helper functions
| Name | Description |
|---|---|
| object str_get_html ( string $content ) | Creates a DOM object from a string. |
| object file_get_html ( string $filename ) | Creates a DOM object from a file or a URL. |
DOM methods & properties
| Name | Description |
|---|---|
|
void __construct ( ) |
Constructor, set the filename parameter will automatically load the contents, either text or file/url. |
|
string plaintext |
Returns the contents extracted from HTML. |
|
void clear () |
Clean up memory. |
|
void load ( string $content ) |
Load contents from a string. |
|
string save ( ) |
Dumps the internal DOM tree back into a string. If the $filename is set, result string will save to file. |
|
void load_file ( string $filename ) |
Load contents from a from a file or a URL. |
|
void set_callback ( string $function_name ) |
Set a callback function. |
|
mixed find ( string $selector ) |
Find elements by the CSS selector. Returns the Nth element object if index is set, otherwise return an array of object. |
Element methods & properties
| Name | Description |
|---|---|
| string | Read or write element’s attribure value. |
|
string tag |
Read or write the tag name of element. |
|
string outertext |
Read or write the outer HTML text of element. |
|
string innertext |
Read or write the inner HTML text of element. |
|
string plaintext |
Read or write the plain text of element. |
|
mixed find ( string $selector ) |
Find children by the CSS selector. Returns the Nth element object if index is set, otherwise, return an array of object. |
DOM traversing
| Name | Description |
|---|---|
|
mixed $e->children ( ) |
Returns the Nth child object if index is set, otherwise return an array of children. |
|
element $e->parent () |
Returns the parent of element. |
|
element $e->first_child () |
Returns the first child of element, or null if not found. |
|
element $e->last_child () |
Returns the last child of element, or null if not found. |
|
element $e->next_sibling () |
Returns the next sibling of element, or null if not found. |
|
element $e->prev_sibling () |
Returns the previous sibling of element, or null if not found. |
cURL и аутентификация в веб-формах (передача данных методом GET и POST)
Аутентификация в веб-формах – это тот случай, когда мы вводим логин и пароль в форму на сайте. Именно такая аутентификация используется при входе в почту, на форумы и т. д.
Использование curl для получения страницы после HTTP аутентификации очень сильно различается в зависимости от конкретного сайта и его движка. Обычно, схема действий следующая:
1) С помощью Burp Suite или Wireshark узнать, как именно происходит передача данных. Необходимо знать: адрес страницы, на которую происходит передача данных, метод передачи (GET или POST), передаваемая строка.
2) Когда информация собрана, то curl запускается дважды – в первый раз для аутентификации и получения кукиз, второй раз – с использованием полученных кукиз происходит обращение к странице, на которой содержаться нужные сведения.
Используя веб-браузер, для нас получение и использование кукиз происходит незаметно. При переходе на другую страницу или даже закрытии браузера, кукиз не стираются – они хранятся на компьютере и используются при заходе на сайт, для которого предназначены. Но curl по умолчанию кукиз не хранит. И поэтому после успешной аутентификации на сайте с помощью curl, если мы не позаботившись о кукиз вновь запустим curl, мы не сможем получить данные.
Для сохранения кукиз используется опция —cookie-jar, после которой нужно указать имя файла. Для передачи данных методом POST используется опция —data. Пример (пароль заменён на неверный):
curl --cookie-jar cookies.txt http://forum.ru-board.com/misc.cgi --data 'action=dologin&inmembername=f123gh4t6&inpassword=111222333&ref=http%3A%2F%2Fforum.ru-board.com%2Fmisc.cgi%3Faction%3Dlogout'
Далее для получения информации со страницы, доступ на которую имеют только зарегестрированные пользователи, нужно использовать опцию -b, после которой нужно указать путь до файла с ранее сохранёнными кукиз:
curl -b cookies.txt 'http://forum.ru-board.com/topic.cgi?forum=35&topic=80699&start=3040' | iconv -f windows-1251 -t UTF-8
Эта схема может не работать в некоторых случаях, поскольку веб-приложение может требовать указание кукиз при использовании первой команды (встречалось такое поведение на некоторых роутерах), также может понадобиться указать верного реферера, либо другие данные, чтобы аутентификация прошла успешно.
Реализация парсера на PHP
Пожалуй, самый ответственный момент в нашем случае — это поиск донора, то есть сайта, на котором будет появляться интересующая нас информация. Сайт должен работать бесперебойно, выполнять свои обязанности по обновлению информации исправно и текст должен быть открытый (то есть, открыв исходный код страницы в браузере — мы должны видеть там интересующую нас информацию).
Когда сайт-донор и нужная нам страница для парсинга найдена, запоминаем ее урл и переходим к следующему этапу. Создаем в блокноте текстовый файл, например parser.php и помещаем в него следующий код:
<?php
//откуда будем парсить информацию
$content = file_get_contents('полный урл страницы с http:// с которого будем вырезать информацию');
// Определяем позицию строки, до которой нужно все отрезать
$pos = strpos($content, 'здесь кусок кода/текста который размещен перед нужным текстом');
//Отрезаем все, что идет до нужной нам позиции
$content = substr($content, $pos);
// Точно таким же образом находим позицию конечной строки
$pos = strpos($content, 'здесь кусок кода/текста который стоит в конце нужного нам текста');
// Отрезаем нужное количество символов от нулевого
$content = substr($content, 0, $pos);
//если в тексте встречается текст, который нам не нужен, вырезаем его
$content = str_replace('текст который нужно вырезать','', $content);
// выводим спарсенный текст.
echo $content;
echo "вставляем сюда завершающий код";
?>
Итак, какие-то 8 строчек кода и сторонний контент автоматически публикуется на нашем блоге. Красным цветом в коде обозначены места, которые вы обязательно должны отредактировать, зеленым цветом — при необходимости. Если необходимости нет, то можно просто удалить эти строчки или запретить им обрабатываться (я про строчки в которых зеленый текст) — ставим перед строчкой два слеша — //
Нужны пояснения к кускам кода/текста, которые обрамляют нужный нам текст? Тут все просто, мы должны указать начальную и конечную позицию в тексте, который нужно парсить. Открываем исходную страницу на сайте-доноре и ищем нужный нам текст. Как правило, он будет начинаться с какой нибудь html-разметки, что-то типа этого — <td><p><strong><em> и заканчиваться такой же абракадаброй — например, </td><td> </td><td> </td></tr>. Копируем эти символы в начальную и конечную позиции (2 и 3 красная строчки). Помним, наш скрипт спарсит текст, который находится между этими позициями на сайте.
parser.php готов. Копируем его в корень своего сайта и запускаем в браузере http://мой сайт/parser.php. Если вы все сделали правильно, вы увидите вырезанный/спарсенный кусок текста. Разумеется, он индексируется и не содержит никаких следов того, что вы его забрали с другого сайта.
Contributors/Thanks to
- raxbg for contributions to parse , grid lines, and various bugfixes.
- westonruter for bugfixes and improvements.
- FMCorz for many patches and suggestions, for being able to parse comments and IE hacks (in lenient mode).
- Lullabot for a patch that allows to know the line number for each parsed token.
- ju1ius for the specificity parsing code and the ability to expand/compact shorthand properties.
- ossinkine for a 150 time performance boost.
- docteurklein for output formatting and inspiration.
- nicolopignatelli for PSR-0 compatibility.
- diegoembarcadero for keyframe at-rule parsing.
- goetas for @namespace at-rule support.
- View full list
How to find HTML elements?
$ret = $html->find(‘a’);
$ret = $html->find(‘a’, );
$ret = $html->find(‘a’, -1);
$ret = $html->find(‘div’);
$ret = $html->find(‘div’);
$ret = $html->find(‘#foo’);
$ret = $html->find(‘.foo’);
$ret = $html->find(‘*’);
$ret = $html->find(‘a, img’);
$ret = $html->find(‘a, img’);
Supports these operators in attribute selectors:
| Filter | Description |
|---|---|
| Matches elements that have the specified attribute. | |
| Matches elements that don’t have the specified attribute. | |
| Matches elements that have the specified attribute with a certain value. | |
| Matches elements that don’t have the specified attribute with a certain value. | |
| Matches elements that have the specified attribute and it starts with a certain value. | |
| Matches elements that have the specified attribute and it ends with a certain value. | |
| Matches elements that have the specified attribute and it contains a certain value. |
$es = $html->find(‘ul li’);
$es = $html->find(‘div div div’);
$es = $html->find(‘table.hello td’);
$es = $html->find(»table td’);
foreach($html->find(‘ul’) as $ul)
{
foreach($ul->find(‘li’) as $li)
{
}
}
$e = $html->find(‘ul’, )->find(‘li’, );
Options
It is possible to set additional options by passing an array as the second parameter when creating the object.
Disabling detection of bots
In some cases you may want to disable the detection of bots. This allows the bot the deliberately fool WhichBrowser, so you can pick up the identity of useragent what the bot tries to mimic. This is especially handy when you want to use WhichBrowser to switch between different variants of your website and want to make sure crawlers see the right variant of the website. For example, a bot that mimics a mobile device will see the mobile variant of you site.
$result = new WhichBrowser\Parser(getallheaders(), );
Проблемы совместимости карты памяти и читающего устройства
Version 3.0.0-beta1 (2016-09-16)
Added
- Function/method and parameter builders now support PHP 7.1 type hints (void, iterable and
nullable types). - Nodes and Comments now implement . The node kind is stored in a
property. - The node now has an attribute, that specifies whether the
preceding closing tag contained a newline. The pretty printer honors this attribute. - Partial parsing of (with missing property name) is now supported in error recovery mode.
- The error recovery mode is now exposed in the script through the
or flags.
The following changes are also part of PHP-Parser 2.1.1:
- The PHP 7 parser will now generate a parse error for assignments.
- Comments on free-standing code blocks will now be retained as comments on the first statement in
the code block.
Google Фото – лучшее бесплатное хранилище для фото и видео
Motorola Moto G8 Plus
-
Дисплей: 6,3 дюйма, FHD+, IPS
-
Процессор: Snapdragon 665
-
Память: 4/64 Гб
-
ЦАП: отсутствует
-
Батарея: 4000 мАч
Цена: от 16 000 руб.
Бюджетные смартфоны довольно редко оснащаются стереодинамиками, но модель от Motorola в этом плане стала приятным исключением. Аппарат имеет действительно качественное звучание. Смотреть на нем фильмы или слушать музыку без наушников вполне комфортно. На этом фишки модели не закончились – есть защита от брызг P2i, NFC, разъем 3,5 и тройная камера 48+5+16 Мп. Фронтальная камера – 25 Мп.
Достоинства:
-
Быстрая зарядка.
-
Качественная фотокамера и интересные режимы для съемки.
-
Есть NFC.
-
Приятное звучание.
-
Защита от брызг.
-
Неплохая производительность.
Недостатки:
-
Смартфоны Motorola всегда внешне отличались от конкурентов, G8 Plus – это типичный девайс с Андроид без ярко-выраженных особенностей.
-
Комбинированный слот.
-
Маркий корпус.
Неправильная кодировка при использовании cURL
В настоящее время на большинстве сайтов используется кодировка UTF-8, с которой cURL прекрасно работает.
Но, например, при открытии некоторых сайтов:
curl http://z-oleg.com/
Вместо кириллицы мы увидим крякозяблы:
Кодировку можно преобразовать «на лету» с помощью команды iconv. Но нужно знать, какая кодировка используется на сайте. Для этого обычно достаточно заглянуть в исходный код веб-страницы и найти там строку, содержащую слово charset, например:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Эта строка означает, что используется кодировка windows-1251.
Для преобразования из кодировки windows-1251 в кодировку UTF-8 с помощью iconv команда выглядит так:
iconv -f windows-1251 -t UTF-8
Совместим её с командой curl:
curl http://z-oleg.com/ | iconv -f windows-1251 -t UTF-8
После этого вместо крякозяблов вы увидите русские буквы.
Генри Форд — Моя жизнь, мои достижения

Автобиография великого изобретателя и создателя известнейшей компании в мире. В ней он поделится своим мнением о бизнесе и принципами, которыми он руководствовался при его создании.
Он расскажет о своей непростой жизни, взлетах и падениях, судебных разбирательствах, в которых ему приходилось участвовать, о полном разорении и получении огромного состояния. В книге приведены примеры многих сложных производственных процессов, которые разработал и запустил в собственный бизнес сам автор.
Генри Форд был не только гениальным изобретателем, но и талантливым менеджером. Его секреты управления используются во многих компаниях и по сей день. Эта книга послужит настоящим учебником для начинающих бизнесменов.
Купить электронную книгу в ЛитРес

Купить аудиокнигу в ЛитРес
Купить бумажную книгу в Лабиринте
Делаем запросы
Интерфейс класса достаточно простой и прямолинейный. Имена методов соответствуют HTTP-методам, которые он выполняет: GET-метод соответствует методу get(), GET-post(), PUT-put() и т.д. И каждый из этих методов возвращает Promise (если вы знакомы с JavaScript, или ранее работали с ReactPHP, то это не должно вызвать у вас вопросов). Если вы не знаете, что это, то на даном этапе объяснения не имеют большого смысла, дальше будет пример, после которого всё станет понятно.
Для текущей задачи нам будет достаточно одного метода :
В коде выше будет описана анонимная функция, которая после успешного запроса выведет HTML-разметку на экран. Эта функция принимает ответ экземпляра . В этой функции мы можем описать обработчик ответа, который вернёт из этого промиса (Promise) распарсенную информацию, без лишнего HTML-кода.
Как вы можете заметить, алгоритм парсинга достаточно прост:
- Делаем запрос и получаем промис.
- Пишем обработчик этого промиса.
- Парсим нужную информацию внутри этого обработчика.
- Если нужно, повторяем первый шаг.
Version 4.4.0 (2020-04-10)
Added
- Added support for passing union types in builders.
- Added end line, token position and file position information for comments.
- Added method to nodes.
Fixed
- Fixed generation of invalid code when using the formatting preserving pretty printer, and
inserting code next to certain nop statements. The formatting is still ugly though. -
no longer requires that the very last comment before a node be a doc comment.
There may not be non-doc comments between the doc comment and the declaration. - Allowed arbitrary expressions in and , rather than just variables.
In particular, this allows , which is legal PHP code.
Version 4.1.0 (2018-10-10)
Added
- Added support for PHP 7.3 flexible heredoc/nowdoc strings, completing support for PHP 7.3. There
are two caveats for this feature:- In some rare, pathological cases flexible heredoc/nowdoc strings change the interpretation of
existing doc strings. PHP-Parser will now use the new interpretation. - Flexible heredoc/nowdoc strings require special support from the lexer. Because this is not
available on PHP versions before 7.3, support has to be emulated. This emulation is not perfect
and some cases which we do not expect to occur in practice (such as flexible doc strings being
nested within each other through abuse of variable-variable interpolation syntax) may not be
recognized correctly.
- In some rare, pathological cases flexible heredoc/nowdoc strings change the interpretation of
- Added to to skip both traversal of child
nodes, and prevent subsequent visitors from visiting the current node.
Learn more
— learn about the design goals of the project (features, performance metrics, and more).
— learn how to reference the parser from your project, and how to perform
operations on the AST to answer questions about your code.
— get a more tangible feel for the AST. Get creative — see if you can break it!
— how much of the grammar is supported? Performance? Memory? API stability?
How it works — learn about the architecture, design decisions, and tradeoffs.
Contribute! — learn how to get involved, check out some pointers to educational commits that’ll
help you ramp up on the codebase (even if you’ve never worked on a parser before),
and recommended workflows that make it easier to iterate.
Системный реестр
Чуть сложнее и дольше сменить адрес адаптера вариантом 2 — в системном реестре. Как и диспетчер устройств, открыть его можно несколькими способами. Например, введя команду «regedit» в окне, вызываемом по Win+R.
Откроется редактор реестра, в котором прописаны все параметры уставленной ОС. Работать надо внимательно и аккуратно. Сделать твик (так называют изменение реестра) нужно в ветке HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Class\{4D36E972-E325-11CE-BFC1-08002bE10318}.
Тут прописаны все устройства, которые нашла ОС при установке. Их реальные имена, адреса, драйвера и прочая информация. Комбинация цифр в конце отвечает за сетевые устройства в системе.
Надо последовательно проверить папки 0000, 0001… 0003. Параметр «DriverDesc» укажет реальное название сетевой карты.
Найдя раздел нужной, переходим к параметру NetworkAddress.
Значение, указанное в нём, подменяет собой аппаратный адрес устройства. Иногда параметр отсутствует, но его можно создать. На запрос реестра о типе указать «строковый». Указывая его значение, изменяем МАС-адрес компьютера.
После этого нужно перезагрузить сетевой адаптер.