Python: поиск подстроки, операции со строками. как выполнять поиск в строке python?
Содержание:
- String Special Operators
- Return Only Some Fields
- Разделить строки?
- Операторы членства (Membership Operators)
- Скобочные группы (?:…) и перечисления |
- Поисковые системы
- Где находится автозамена в ворде
- Форматирование строк
- Поиск Фибоначчи
- Python string rfind()
- To find the total occurrence of a substring
- Проверяет, что все элементы в последовательности True.
- Вот и всё!
- Зачем использовать Python для поиска?
- re.match(pattern, string)
- Другие методы для работы со строками в Python
- 5.4. Sets¶
- Разделение на подстроки в Python
- Компилирование
- Линейный поиск
- Заключение
String Special Operators
Assume string variable a holds ‘Hello’ and variable b holds ‘Python’, then −
| Operator | Description | Example |
|---|---|---|
| + | Concatenation — Adds values on either side of the operator | a + b will give HelloPython |
| * | Repetition — Creates new strings, concatenating multiple copies of the same string |
a*2 will give -HelloHello |
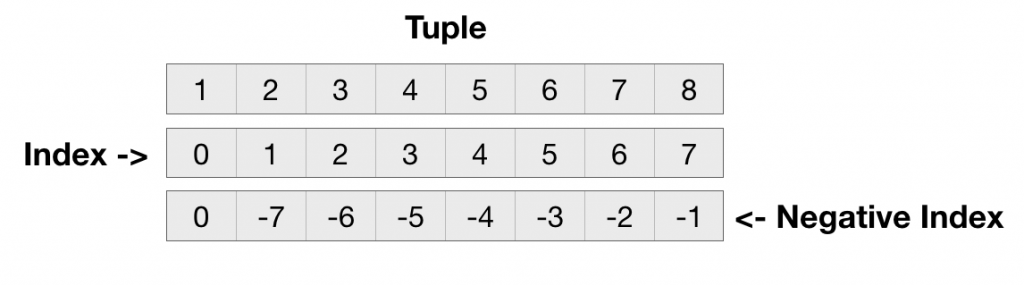
| [] | Slice — Gives the character from the given index | a will give e |
| Range Slice — Gives the characters from the given range | a will give ell | |
| in | Membership — Returns true if a character exists in the given string | H in a will give 1 |
| not in | Membership — Returns true if a character does not exist in the given string | M not in a will give 1 |
| r/R | Raw String — Suppresses actual meaning of Escape characters. The syntax for raw strings is exactly the same as for normal strings with the exception of the raw string operator, the letter «r,» which precedes the quotation marks. The «r» can be lowercase (r) or uppercase (R) and must be placed immediately preceding the first quote mark. | print r’\n’ prints \n and print R’\n’prints \n |
| % | Format — Performs String formatting | See at next section |
Return Only Some Fields
The second parameter of the method
is an object describing which fields to include in the result.
This parameter is optional, and if omitted, all fields will be included in
the result.
Example
Return only the names and addresses, not the _ids:
import pymongomyclient = pymongo.MongoClient(«mongodb://localhost:27017/»)
mydb = myclientmycol = mydbfor x in mycol.find({},{ «_id»: 0, «name»: 1, «address»: 1 }):
print(x)
You are not allowed to specify both 0 and 1 values in the same object (except
if one of the fields is the _id field). If you specify a field with the value 0, all other fields get the value 1,
and vice versa:
Example
This example will exclude «address» from the result:
import pymongomyclient = pymongo.MongoClient(«mongodb://localhost:27017/»)
mydb = myclientmycol = mydbfor x in mycol.find({},{ «address»: 0 }):
print(x)
Example
You get an error if you specify both 0 and 1 values in the same object
(except if one of the fields is the _id field):
import pymongomyclient = pymongo.MongoClient(«mongodb://localhost:27017/»)
mydb = myclientmycol = mydbfor x in mycol.find({},{ «name»: 1, «address»: 0 }):
print(x)
❮ Previous
Next ❯
Разделить строки?
Есть несколько способов получить часть строки. Первый — это , обратный метод для . В отличие от ’а, он применяется к целевой строке, а разделитель передаётся аргументом.
Второй — срезы (slices).
Срез s позволяет получить подстроку с символа x до символа y. Можно не указывать любое из значений, чтобы двигаться с начала или до конца строки. Отрицательные значения используются для отсчёта с конца (-1 — последний символ, -2 — предпоследний и т.п.).
При помощи необязательного третьего параметра s можно выбрать из подстроки каждый N-ый символ. Например, получить только чётные или только нечётные символы:
Операторы членства (Membership Operators)
Алгоритмы развиваются и оптимизируются в результате постоянной эволюции и необходимости находить наиболее эффективные решения для основных проблем в различных областях.
Одной из наиболее распространенных проблем в области компьютерных наук является поиск в коллекции и определение того, присутствует ли данный объект в коллекции или нет.
Почти каждый язык программирования имеет свою собственную реализацию базового алгоритма поиска. Обычно — в виде функции, которая возвращает логическое значение или , когда элемент найден в данной коллекции элементов.
В Python самый простой способ поиска объекта — использовать . Их название связано с тем, что они позволяют нам определить, является ли данный объект членом коллекции.
Эти операторы могут использоваться с любой итерируемой структурой данных в Python, включая строки, списки и кортежи.
- — возвращает , если данный элемент присутствует в структуре данных.
- — возвращает , если данный элемент не присутствует в структуре данных.
>>> 'apple' in True >>> 't' in 'pythonist' True >>> 'q' in 'pythonist' False >>> 'q' not in 'pythonist' True
Операторов членства достаточно, если нам нужно только определить, существует ли подстрока в данной строке, или пересекаются ли две строки, два списка или кортежа с точки зрения содержащихся в них объектов.
В большинстве случаев помимо определения, наличествует ли элемент в последовательности, нам нужна еще и позиция (индекс) элемента. Используя операторы членства, мы не можем получить ее.
Существует множество алгоритмов поиска, которые не зависят от встроенных операторов и могут использоваться для более быстрого и/или эффективного поиска значений. Кроме того, они могут дать больше информации (например, о позиции элемента в коллекции), а не просто определить, есть ли в коллекции этот элемент.
Скобочные группы (?:…) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора , который записывается с помощью символа . Так, некоторая строка подходит к регулярному выражению тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений или . Например, отдельные овощи в тексте можно искать при помощи шаблона .
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами или . Например, . Каждый отдельный символ можно задать как , и можно весь шаблон записать так:
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка . Можно писать круглые скобки и без значков , однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее. Об этом будет написано ниже. Итак, если — шаблон, то — эквивалентный ему шаблон. Разница только в том, что теперь к можно применять квантификаторы, указывая, сколько именно раз должна повториться группа. Например, шаблон для поиска MAC-адреса, можно записать так:
Скобки плюс перечисления
Также скобки позволяют локализовать часть шаблона, внутри которого происходит перечисление. Например, шаблон соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом .
Ещё примеры
| Шаблон | Применяем к тексту |
|---|---|
| Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. | |
| Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86. | |
| +7-926-123-12-12, 8-926-123-12-12 | |
| Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. | |
| Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный. |
Поисковые системы
Где находится автозамена в ворде
Форматирование строк
Часто возникает ситуация, когда необходимо создать строку, подставив в нее определенные значения, полученные во время выполнения программы. Подстановка данных в таком случае выполняется при помощи форматирования строк, сделать это можно несколькими способами.
Оператор %
Строки в Python обладают встроенной операцией, к которой можно получить доступ оператором %, что дает возможность очень просто делать форматирование. Самый простой пример – когда для подстановки нужен только один аргумент, значением будет он сам:
Если же для подстановки используется несколько аргументов, то значением будет кортеж со строками:
Как видно из предыдущего примера, зависимо от типа данных для подстановки и того, что требуется получить в итоге, пишется разный формат. Наиболее часто используются:
- ‘%d’, ‘%i’, ‘%u – десятичное число;
- ‘%c’ – символ, точнее строка из одного символа или число – код символа;
- ‘%r’ – строка (литерал Python);
- ‘%s’ – строка.
Такой способ форматирования строк называет «старым» стилем, который в Python 3 был заменен на более удобные способы.
str.format()
В Python 3 появился более новый метод форматирования строк, который вскоре перенесли и в Python 2.7. Такой способ избавляет программиста от специального синтаксиса %-оператора. Делается все путем вызова .format() для строковой переменной. С помощью специального символа – фигурных скобок – указывается место для подстановки значения, каждая пара скобок указывает отдельное место для подстановки, значения могут быть разного типа:
В Python 3 форматирование строк с использованием «нового стиля» является более предпочтительным по сравнению с использованием %-стиля, так как предоставляет более широкие возможности, не усложняя простые варианты использования.
f-строки (Python 3.6+)
В Python версии 3.6 появился новый метод форматирования строк – «f-строки», с его помощью можно использовать встроенные выражения внутри строк:
Такой способ форматирования очень мощный, так как дает возможность встраивать выражения:
Таким образом, форматирование с помощью f-строк напоминает использование метода format(), но более гибкое, быстрое и читабельное.
Стандартная библиотека Template Strings
Еще один способ форматирования строк, который появился еще с выходом Python версии 2.4, но так и не стал популярным – использование библиотеки Template Strings. Есть поддержка передачи значения по имени, используется $-синтаксис как в языке PHP:
Поиск Фибоначчи
Поиск Фибоначчи — это еще один алгоритм «разделяй и властвуй», который имеет сходство как с бинарным поиском, так и с jump search. Он получил свое название потому, что использует числа Фибоначчи для вычисления размера блока или диапазона поиска на каждом шаге.
Числа Фибоначчи — это последовательность чисел 0, 1, 1, 2, 3, 5, 8, 13, 21 …, где каждый элемент является суммой двух предыдущих чисел.
Алгоритм работает с тремя числами Фибоначчи одновременно. Давайте назовем эти три числа , и . Где и — это два числа, предшествующих в последовательности:
Мы инициализируем значения 0, 1, 1 или первые три числа в последовательности Фибоначчи. Это поможет нам избежать в случае, когда наш массив содержит очень маленькое количество элементов.
Затем мы выбираем наименьшее число последовательности Фибоначчи, которое больше или равно числу элементов в нашем массиве , в качестве значения . А два числа Фибоначчи непосредственно перед ним — в качестве значений и . Пока в массиве есть элементы и значение больше единицы, мы:
- Сравниваем со значением блока в диапазоне до и возвращаем индекс элемента, если он совпадает.
- Если значение больше, чем элемент, который мы в данный момент просматриваем, мы перемещаем значения , и на два шага вниз в последовательности Фибоначчи и меняем индекс на индекс элемента.
- Если значение меньше, чем элемент, который мы в данный момент просматриваем, мы перемещаем значения и на один шаг вниз в последовательности Фибоначчи.
Давайте посмотрим на реализацию этого алгоритма на Python:
def FibonacciSearch(lys, val):
fibM_minus_2 = 0
fibM_minus_1 = 1
fibM = fibM_minus_1 + fibM_minus_2
while (fibM < len(lys)):
fibM_minus_2 = fibM_minus_1
fibM_minus_1 = fibM
fibM = fibM_minus_1 + fibM_minus_2
index = -1;
while (fibM > 1):
i = min(index + fibM_minus_2, (len(lys)-1))
if (lys < val):
fibM = fibM_minus_1
fibM_minus_1 = fibM_minus_2
fibM_minus_2 = fibM - fibM_minus_1
index = i
elif (lys > val):
fibM = fibM_minus_2
fibM_minus_1 = fibM_minus_1 - fibM_minus_2
fibM_minus_2 = fibM - fibM_minus_1
else :
return i
if(fibM_minus_1 and index < (len(lys)-1) and lys == val):
return index+1;
return -1
Используем функцию FibonacciSearch для вычисления:
>>> print(FibonacciSearch(, 6))
Давайте посмотрим на пошаговый процесс поиска:
- Присваиваем переменной наименьшее число Фибоначчи, которое больше или равно длине списка. В данном случае наименьшее число Фибоначчи, отвечающее нашим требованиям, равно 13.
- Значения присваиваются следующим образом:
fibM = 13
fibM_minus_1 = 8
fibM_minus_2 = 5
index = -1
Далее мы проверяем элемент lys, где 4 — это минимум из двух значений — index + fibM_minus_2 (-1+5) и длина массива минус 1 (11-1). Поскольку значение lys равно 5, что меньше искомого значения, мы перемещаем числа Фибоначчи на один шаг вниз в последовательности, получая следующие значения:
fibM = 8
fibM_minus_1 = 5
fibM_minus_2 = 3
index = 4
Далее мы проверяем элемент lys, где 7 — это минимум из двух значений: index + fibM_minus_2 (4 + 3) и длина массива минус 1 (11-1). Поскольку значение lys равно 8, что больше искомого значения, мы перемещаем числа Фибоначчи на два шага вниз в последовательности, получая следующие значения:
fibM = 3
fibM_minus_1 = 2
fibM_minus_2 = 1
index = 4
Затем мы проверяем элемент lys, где 5 — это минимум из двух значений: index + fibM_minus_2 (4+1) и длина массива минус 1 (11-1) . Значение lys равно 6, и это наше искомое значение!
Получаем ожидаемый результат:
5
Временная сложность поиска Фибоначчи равна O(log n). Она такая же, как и у бинарного поиска. Это означает, что алгоритм в большинстве случаев работает быстрее, чем линейный поиск и jump search.
Поиск Фибоначчи можно использовать, когда у нас очень большое количество искомых элементов и мы хотим уменьшить неэффективность, связанную с использованием алгоритма, основанного на операторе деления.
Дополнительным преимуществом использования поиска Фибоначчи является то, что он может вместить входные массивы, которые слишком велики для хранения в кэше процессора или ОЗУ, потому что он ищет элементы с увеличивающимся шагом, а не с фиксированным.
Python string rfind()
The Python function rfind() is similar to find() function with the only difference is that rfind() gives the highest index for the substring given and find() gives the lowest i.e the very first index. Both rfind() and find() will return -1 if the substring is not present.
In the example below, we have a string «Meet Guru99 Tutorials Site. Best site for Python Tutorials!» and will try to find the position of substring Tutorials using find() and rfind(). The occurrence of Tutorials in the string is twice.
Here is an example where both find() and rfind() are used.
mystring = "Meet Guru99 Tutorials Site.Best site for Python Tutorials!"
print("The position of Tutorials using find() : ", mystring.find("Tutorials"))
print("The position of Tutorials using rfind() : ", mystring.rfind("Tutorials"))
Output:
The position of Tutorials using find() : 12 The position of Tutorials using rfind() : 48
The output shows that find() gives the index of the very first Tutorials substring that it gets, and rfind() gives the last index of substring Tutorials.
To find the total occurrence of a substring
To find the total number of times the substring has occurred in the given string we will make use of find() function. Will loop through the string using for-loop from 0 till the end of the string. Will make use of startIndex parameter for find().
Variables startIndex and count will be initialized to 0. Inside for –loop will check if the substring is present inside the string given using find() and startIndex as 0.
The value returned from find() if not -1, will update the startIndex to the index where the string is found and also increment the count value.
Here is the working example:
my_string = "test string test, test string testing, test string test string"
startIndex = 0
count = 0
for i in range(len(my_string)):
k = my_string.find('test', startIndex)
if(k != -1):
startIndex = k+1
count += 1
k = 0
print("The total count of substring test is: ", count )
Output:
The total count of substring test is: 6
Summary
- The Python string find() method helps to find the index of the first occurrence of the substring in the given string. It will return -1 if the substring is not present.
- The parameters passed to find() method are substring i.e the string you want to search for, start, and end. The start value is 0 by default, and the end value is the length of the string.
- You can search the substring in the given string and specify the start position, from where the search will begin. The start parameter can be used for the same.
- Using the start and end parameter, we will try to limit the search, instead of searching the entire string.
- The Python function rfind() is similar to find() function with the only difference is that rfind() gives the highest index for the substring given and find() gives the lowest i.e the very first index. Both rfind() and find() will return -1 if the substring is not present.
- The Python string index() is yet another function that will give you the position of the substring given just like find(). The only difference between the two is, index() will throw an exception if the substring is not present in the string and find() will return -1.
- We can make use of find() to find the count of the total occurrence of a substring in a given string.
Проверяет, что все элементы в последовательности True.
Описание:
Функция возвращает значение , если все элементы в итерируемом объекте — истинны, в противном случае она возвращает значение .
Если передаваемая последовательность пуста, то функция также возвращает .
Функция применяется для проверки на ВСЕХ значений в последовательности и эквивалентна следующему коду:
def all(iterable):
for element in iterable
if not element
return False
return True
Так же смотрите встроенную функцию
В основном функция применяется в сочетании с оператором ветвления программы . Работу функции можно сравнить с оператором в Python, только работает с последовательностями:
>>> True and True and True # True >>> True and False and True # False >>> all() # True >>> all() # False
Но между и в Python есть два основных различия:
- Синтаксис.
- Возвращаемое значение.
Функция всегда возвращает или (значение )
>>> all() # True >>> all(]) # False
Если в выражении все значения , то оператор возвращает ПЕРВОЕ истинное значение, а если все значения , то последнее ложное значение. А если в выражении присутствует значение , то ПЕРВОЕ ложное значение. Что бы добиться поведения как у функции , необходимо выражение с оператором обернуть в функцию .
>>> 3 and 1 and 2 and 6 # 6 >>> 3 and and 3 and [] # 0 >>> bool(3 and 1 and 2 and 6) # True >>> bool(3 and and 3 and []) # False
Из всего сказанного можно сделать вывод, что для успешного использования функции необходимо в нее передавать последовательность, полученную в результате каких то вычислений/сравнений, элементы которого будут оцениваться как или . Это можно достичь применяя функцию или выражения-генераторы списков, используя в них встроенные функции или методы, возвращающие значения, операции сравнения, оператор вхождения и оператор идентичности .
num = 1, 2.0, 3.1, 4, 5, 6, 7.9 # использование встроенных функций или # методов на примере 'isdigit()' >>> str(x).isdigit() for x in num # # использование операции сравнения >>> x > 4 for x in num # # использование оператора вхождения `in` >>> '.' in str(x) for x in num # # использование оператора идентичности `is` >>> type(x) is int for x in num # # использование функции map() >>> list(map(lambda x x > 1, num)) False, True, True, True, True, True, True
Примеры проводимых проверок функцией .
Допустим, у нас есть список чисел и для дальнейших операций с этой последовательностью необходимо знать, что все числа например положительные.
>>> num1 = range(1, 9) >>> num2 = range(-1, 7) >>> all() # True >>> all() # False
Или проверить, что последовательность чисел содержит только ЦЕЛЫЕ числа.
>>> num1 = 1, 2, 3, 4, 5, 6, 7 >>> num2 = 1, 2.0, 3.1, 4, 5, 6, 7.9 >>> all() # True >>> all() # False
Или есть строка с числами, записанными через запятую и нам необходимо убедится, что в строке действительно записаны только цифры. Для этого, сначала надо разбить строку на список строк по разделителю и проверить каждый элемент полученного списка на десятичное число методом . Что бы учесть правила записи десятичных чисел будем убирать точку перед проверкой строки на десятичное число.
>>> line1 = "1, 2, 3, 9.9, 15.1, 7" >>> line2 = "1, 2, 3, 9.9, 15.1, 7, девять" >>> all() # True >>> all() # False
Еще пример со строкой. Допустим нам необходимо узнать, есть ли в строке наличие открытой И закрытой скобки?
Вот и всё!
Мы изучили теорию и разобрались в двух популярных алгоритмах поиска — DFS и BFS. Помимо этого, теперь вы знаете, как реализовывать их в Python. Настало время применить все эти знания на практике. Не стоит откладывать, ведь это занятие будет уже куда интереснее чтения. Код BFS и DFS доступен на GitHub.
- Почему мы создали платформу для инженерии машинного обучения, а не науки о данных
- 5 секретов наилучшего использования кортежей в Python
- Утиная типизация в Python - 3 примера
Читайте нас в Telegram, VK и
Перевод статьи XuanKhanh Nguyen: Depth-First Search vs. Breadth-First Search in PythonDepth-First Search vs. Breadth-First Search in Python
Зачем использовать Python для поиска?
Python очень удобочитаемый и эффективный по сравнению с такими языками программирования, как Java, Fortran, C, C++ и т. д. Одним из ключевых преимуществ использования Python для реализации алгоритмов поиска является то, что вам не нужно беспокоиться о приведении или явной типизации.
В Python большинство алгоритмов поиска, которые мы обсуждали, будут работать так же хорошо, если мы ищем строку. Имейте в виду, что понадобится внести изменения в код для алгоритмов, которые используют искомый элемент для числовых вычислений, например алгоритм интерполяционного поиска.
Python также подходит, если вы хотите сравнить производительность различных алгоритмов поиска для вашего dataset’а. Создание прототипа на Python проще и быстрее, потому что вы можете сделать больше с меньшим количеством строк кода.
Чтобы сравнить производительность наших реализованных алгоритмов, в Python мы можем использовать библиотеку time:
import time start = time.time() # вызовите здесь функцию end = time.time() print(start-end)
re.match(pattern, string)
Метод осуществляет поиск в начале строки по заданному шаблону. Вызвав match() на строке «AV Analytics AV» с шаблоном «AV», мы получим успешный результат поиска. Но если будем искать «Analytics», результат будет отрицательным. Давайте посмотрим, как метод работает:
import re result = re.match(r'AV', 'AV Analytics Vidhya AV') print result
Итог:
<_sre.SRE_Match object at 0x0000000009BE4370>
Итак, искомая подстрока найдена. Если мы хотим вывести её содержимое, пригодится метод group()
Обратите внимание, что мы применяем «r» перед строкой шаблона, дабы показать, что это «сырая» строка
result = re.match(r'AV', 'AV Analytics Vidhya AV') print result.group()
Итог:
AV
А теперь поищем в данной строке «Analytics». Но, как уже было сказано выше, т. к. строка начинается на «AV», результат будет отрицательный:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV') print result
Итог:
None
Кроме того, существуют методы start() и end(), позволяющие узнать начальную и конечную позиции найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV') print result.start() print result.end()
Итог:
2
Данные методы бывают весьма полезны при работе со строками.
Другие методы для работы со строками в Python
В языке Пайтон имеется большое кол-во различных методов для работы со строками. Если рассматривать их все в этой статье, то она может увеличить раза в три, а то и больше. Подробное описание работы всех методов можно найти в официальной документации к языку на сайте https://python.org/
5.4. Sets¶
Python also includes a data type for sets. A set is an unordered collection
with no duplicate elements. Basic uses include membership testing and
eliminating duplicate entries. Set objects also support mathematical operations
like union, intersection, difference, and symmetric difference.
Curly braces or the function can be used to create sets. Note: to
create an empty set you have to use , not ; the latter creates an
empty dictionary, a data structure that we discuss in the next section.
Here is a brief demonstration:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}
Similarly to , set comprehensions
are also supported:
Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.
Компилирование
Модуль re позволяет вам «компилировать» выражение, которое вы ищите чаще всего. Это также позволит вам превратить выражение в объект SRE_Pattern. Вы можете использовать этот объект в вашей функции поиска в будущем. Давайте используем код из предыдущего примера и изменим его, чтобы использовать компилирование:
Python
import re
text = «The ants go marching one by one»
strings =
for string in strings:
regex = re.compile(string)
match = re.search(regex, text)
if match:
print(‘Found «{}» in «{}»‘.format(string, text))
text_pos = match.span()
print(text)
else:
print(‘Did not find «{}»‘.format(string))
|
1 |
importre text=»The ants go marching one by one» strings=’the’,’one’ forstringinstrings regex=re.compile(string) match=re.search(regex,text) ifmatch print(‘Found «{}» in «{}»‘.format(string,text)) text_pos=match.span() print(textmatch.start()match.end()) else print(‘Did not find «{}»‘.format(string)) |
Обратите внимание на то, что здесь мы создаем объект паттерна, вызывая compile в каждой строке нашего списка, и назначаем результат переменной – регулярному выражению. Далее мы передаем это выражение нашей поисковой функции
Остальная часть кода остается неизменной. Основная причина, по которой используют компилирование это сохранить выражение для повторного использования в вашем коде в будущем. В любом случае, компилирование также принимает флаги, которые могут быть использованы для активации различных специальных функций. Мы рассмотрим это далее.
Обратите внимание: когда вы компилируете паттерны, они автоматически кэшируются, так что если вы не особо используете регулярные выражения в своем коде, тогда вам не обязательно сохранять компилированный объект как переменную.
Линейный поиск
Линейный поиск — это один из самых простых и понятных алгоритмов поиска. Мы можем думать о нем как о расширенной версии нашей собственной реализации оператора в Python.
Суть алгоритма заключается в том, чтобы перебрать массив и вернуть индекс первого вхождения элемента, когда он найден:
def LinearSearch(lys, element):
for i in range (len(lys)):
if lys == element:
return i
return -1
Итак, если мы используем функцию для вычисления:
>>> print(LinearSearch(, 2))
То получим следующий результат:
1
Это индекс первого вхождения искомого элемента, учитывая, что нумерация элементов в Python начинается с нуля.
Временная сложность линейного поиска равна O(n). Это означает, что время, необходимое для выполнения, увеличивается с увеличением количества элементов в нашем входном списке .
Линейный поиск не часто используется на практике, потому что такая же эффективность может быть достигнута с помощью встроенных методов или существующих операторов. К тому же, он не такой быстрый и эффективный, как другие алгоритмы поиска.
Линейный поиск хорошо подходит для тех случаев, когда нам нужно найти первое вхождение элемента в несортированной коллекции. Это связано с тем, что он не требует сортировки коллекции перед поиском (в отличие от большинства других алгоритмов поиска).
Заключение
Существует множество возможных способов поиска элемента в коллекции. В этой статье мы обсудили несколько алгоритмов поиска и их реализации на Python.
Выбор используемого алгоритма зависит от данных, с которыми вы будете работать. Это ваш входной массив, который мы называли во всех наших реализациях.
- Если вы хотите выполнить поиск в несортированном массиве или найти первое вхождение искомой переменной, то лучшим вариантом будет линейный поиск.
- Если вы хотите выполнить поиск в отсортированном массиве, есть много вариантов, из которых самый простой и быстрый — это бинарный поиск.
- Если у вас есть отсортированный массив, в котором вы хотите выполнить поиск без использования оператора деления, вы можете использовать либо jump search, либо поиск Фибоначчи.
- Если вы знаете, что искомый элемент, скорее всего, находится ближе к началу массива, вы можете использовать экспоненциальный поиск.
- Если ваш отсортированный массив равномерно распределен, то самым быстрым и эффективным будет интерполяционный поиск.
Если вы не уверены, какой алгоритм использовать для отсортированного массива, просто протестируйте каждый из них при помощи библиотеки time и выберите тот, который лучше всего работает с вашим dataset’ом.