§ 5. база данных — основа информационной системы
Содержание:
- Бизнес и финансы
- Примеры реляционных СУБД
- MVCC — MultiVersion Concurrency Control
- Разные базы — разные правила
- Проектирование реляционной базы данных. Преобразование модели в реляционную
- Для чего нужны
- Конструктивные особенности сращивания стропил
- Реляционная модель данных
- Как хранится информация в БД
- Преимущества и недостатки
- Сверхбольшие базы данных
- Виды баз данных
- В чём преимущества
- Принципы создания
- Особенности реляционных БД
Бизнес и финансы
БанкиБогатство и благосостояниеКоррупция(Преступность)МаркетингМенеджментИнвестицииЦенные бумагиУправлениеОткрытые акционерные обществаПроектыДокументыЦенные бумаги — контрольЦенные бумаги — оценкиОблигацииДолгиВалютаНедвижимость(Аренда)ПрофессииРаботаТорговляУслугиФинансыСтрахованиеБюджетФинансовые услугиКредитыКомпанииГосударственные предприятияЭкономикаМакроэкономикаМикроэкономикаНалогиАудитМеталлургияНефтьСельское хозяйствоЭнергетикаАрхитектураИнтерьерПолы и перекрытияПроцесс строительстваСтроительные материалыТеплоизоляцияЭкстерьерОрганизация и управление производством
Примеры реляционных СУБД
SQLite — это популярная БД SQL с открытым исходным кодом. ПО может хранить всю БД в одном файле. Самым значительным преимуществом, которое она обеспечивает, является то, что все данные могут храниться локально без подключения к серверу. SQLite стала популярной для БД в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных гаджетах.
MySQL — еще одна популярная реляционная модель СУБД SQL с открытым исходным кодом. Обычно она применяется в веб-приложениях и часто доступна с помощью PHP. Главные преимущества ее — простота использования, ценовая доступность, надежность. Некоторые из недостатков проявляются в том, что при масштабировании она страдает от низкой производительности, разработка с применением открытого исходного кода отстает с тех пор, как Oracle установил контроль над MySQL и не включает в себя некоторые расширенные функции.
PostgreSQL — это реляционная модель данных СУБД SQL с использованием открытого исходного кода, которая не контролируется какой-либо корпорацией. Обычно ее используют для разработки веб-приложений. PostgreSQL — простая, надежная и бюджетная программа с большим сообществом разработчиков. Имеет дополнительные функции в виде поддержки внешнего ключа, не требуя сложной настройки. Главный ее недостаток — она работает медленнее, чем иные БД, такие как MySQL. Она также менее популярна, чем MySQL, что затрудняет доступ хостов или поставщиков услуг, которые предлагают управляемые экземпляры PostgreSQL.
MVCC — MultiVersion Concurrency Control
zr1(y)yyy
Как это работает?
- Когда мы пошли исполнять транзакцию t1, имеется чтение x, т.е. самой изначальной версии.
- Дальше в t2 мы начинаем записывать y другой версии, потому что он был изменен.
- В транзакции t1, которая началась раньше, чем мы начали записывать y, до сих пор видно предыдущую версию y, поскольку t2 еще не завершилась, и мы и спокойно начать с ней работать.
- Поскольку транзакция t1 заканчивается раньше, чем w2(y2), то произойдет перечитываниеy,и после этого в транзакции t 2 выполнится нормальная работа, а другая транзакция просто нормально завершится.
yw2yt1xy
- В MySQL он внутри InnoDB,
- В PostgreSQL это отдельная директория, которая наконец в версии 10 стала называться WAL вместо PGX-Log;
- В Oracle это называется Redo Log;
- В DB2 — WAL.
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
— построение набора предварительных таблиц;
— указание РК;
— выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:

Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:

Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
— 1-й нормальной формы (1НФ);
— 2НФ;
— 3НФ;
— НФБК (нормальной формы Бойса-Кодда);
— 4НФ;
— 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии
Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
Конструктивные особенности сращивания стропил
Увеличение длины стропильных ног производится за счет соединения коротких элементов из доски или бруса. Узел стыковки (практически при любом методе наращивания) представляет собой пластичный шарнир. Но стропилина должна иметь необходимую жесткость по всей длине, поэтому стык должен располагаться в том месте, где практически отсутствует изгибающий момент. С этой целью стык (пластичный шарнир) должен располагаться на определенном расстоянии от опоры, которое составляет 15% от длины пролета, перекрываемого стропилом.
 Следует учитывать, что расстояние от мауэрлата до промежуточной стропильной опоры отличается от расстояния между этой же опорой и коньком. Это требует использования равнопрочной схемы – необходимо обеспечить одинаковую прочность по всей длине, создание равного прогиба не требуется.
Следует учитывать, что расстояние от мауэрлата до промежуточной стропильной опоры отличается от расстояния между этой же опорой и коньком. Это требует использования равнопрочной схемы – необходимо обеспечить одинаковую прочность по всей длине, создание равного прогиба не требуется.
Особые требования к прочности предъявляются к накосным (диагональным) стропилам вальмовых и полувальмовых крыш. Они превышают по длине стропила боковых скатов и служат опорой для нарожников – укороченных стропильных ног.
Сращивание стропил, при необходимости увеличить их длину, выполняется по следующим технологиям:
- соединение досок встык;
- метод «косой прируб»;
- соединение внахлест.
Использования такого инструмента, как стусло, дает возможность отрезать концы досок строго под заданным углом, обеспечивая необходимую плотность стыков.
Соединение встык
 Метод соединения встык дает возможность нарастить стропильную ногу, используя специальную накладку. Чтобы правильно выполнить соединение, требуется стыкуемые концы досок или бруса отрезать строго под углом 90°. Это позволит предотвратить образования прогиба под нагрузкой в месте стыка торцов стыкуемых стропил.
Метод соединения встык дает возможность нарастить стропильную ногу, используя специальную накладку. Чтобы правильно выполнить соединение, требуется стыкуемые концы досок или бруса отрезать строго под углом 90°. Это позволит предотвратить образования прогиба под нагрузкой в месте стыка торцов стыкуемых стропил.
Срезанные торцы соединяются и закрепляются посредством металлического крепежа либо используются накладки из обрезков доски, устанавливаемые с обеих сторон соединения. Каждая накладка должна быть прибита гвоздями, расположенными в шахматном порядке.
Метод «косого прируба»
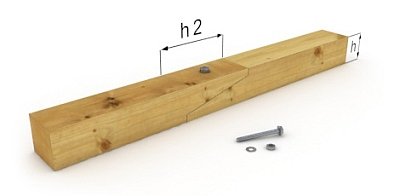 Если соединение встык более всего подходит для сращивания стропильных досок, метод косого прируба идеально подходит для увеличения стропильной ноги из бруса большого сечения. Данная технология получила свое название из-за принципа подрезки элементов. Соприкасающиеся концы досок необходимо подрезать под определенным углом.
Если соединение встык более всего подходит для сращивания стропильных досок, метод косого прируба идеально подходит для увеличения стропильной ноги из бруса большого сечения. Данная технология получила свое название из-за принципа подрезки элементов. Соприкасающиеся концы досок необходимо подрезать под определенным углом.
Элементы, выполненные из бруса, плотно стыкуются полученными плоскостями. В месте соединения требуется выполнить сквозное вертикальное отверстие под шпильку или болт
Важно, чтобы диаметр отверстия точно соответствовал диаметру крепежного элемента (12 или 14 мм) или был меньше на 1 мм. В этом случае крепление плотно сидит в древесине и отсутствует люфт, который может создать нагрузку на изгиб
При установке шпилек или ботов необходимо использовать широкие металлические шайбы, чтобы крепеж со временем не повредил древесину.
Соединение внахлест
 Срастить стропильные доски можно внахлест – это дает возможность создать жесткое соединение. Данный способ удлинения достаточно прост: две доски укладываются друг на друга с нахлестом, длина которого должна составлять не менее одного метра. Соединение досок выполняется при помощи гвоздей – крепежные элементы устанавливаются в шахматном порядке.
Срастить стропильные доски можно внахлест – это дает возможность создать жесткое соединение. Данный способ удлинения достаточно прост: две доски укладываются друг на друга с нахлестом, длина которого должна составлять не менее одного метра. Соединение досок выполняется при помощи гвоздей – крепежные элементы устанавливаются в шахматном порядке.
Крепление элементов внахлест – наиболее простой способ стыковки наращивания стропильных ног. В этом случае не требуется соблюдать точность подрезки элементов. Вместо гвоздей в качестве крепежа могут применяться шпильки с шайбами и гайками.
Спаренные и составные стропила из досок
В качестве удлиненных стропильных ног используются конструкции, выполненные из досок – спаренные и составные.
Спаренные выполняются из двух или более досок, соединенных широкими сторонами, которые сшиваются друг с другом с помощью гвоздей, расположенных в шахматном порядке. Чтобы увеличить длину стропильной ноги, соединенные попарно доски стыкуются внахлест и встык с другой спаренной системой. Это дает возможность создать равнопрочную конструкцию, способную выдержать высокие нагрузки. Удлиненные стропильные ноги из спаренных досок практически не уступают стропилам из цельного бруса и могут применяться для создания накосных стропил для вальмовых и полувальмовых крыш.
При удлинении стропильной ноги важно, чтобы сплачиваемые доски располагались со сдвигом не менее, чем на метр. Соединения должны располагаться в шахматном порядке, чтобы каждый стык был закрыт цельной доской
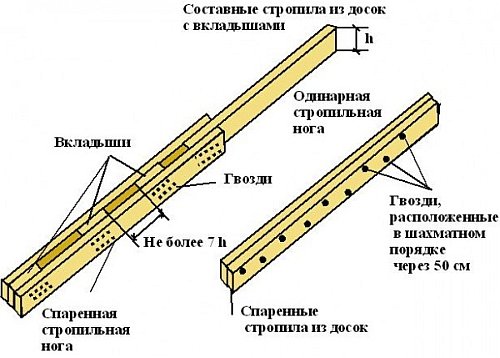 Составное стропило изготавливается из трех досок. Основой конструкции являются две доски, имеющие одинаковую длину. Между ними укладывается третья доска, по ширине соответствующая основным. Ее длина должна обеспечить необходимую длину стропильной доски. Свободный промежуток между двумя основными досками заполняется обрезками доски, ширина которых соответствует доске-вкладышу. Вся конструкция прошивается гвоздями. Дополнительная доска должна заходить между основными не менее чем на метр по длине. Она закрепляется гвоздями, расположенными в шахматном порядке.
Составное стропило изготавливается из трех досок. Основой конструкции являются две доски, имеющие одинаковую длину. Между ними укладывается третья доска, по ширине соответствующая основным. Ее длина должна обеспечить необходимую длину стропильной доски. Свободный промежуток между двумя основными досками заполняется обрезками доски, ширина которых соответствует доске-вкладышу. Вся конструкция прошивается гвоздями. Дополнительная доска должна заходить между основными не менее чем на метр по длине. Она закрепляется гвоздями, расположенными в шахматном порядке.
Надежность составных стропил существенно уступает спаренным конструкциям. Составные системы могут с успехом использоваться для возведения скатных кровель, но их нельзя применять в качестве накосных стропил вальмовых крыш.
Чтобы правильно выполнить монтаж удлиненных балок, необходимо учитывать место расположения стыков нарощенной конструкции. Они должны располагаться недалеко от опоры, что в минимальной степени подвергаться нагрузкам на изгиб. Наращивание стропил – экономически выгодный шаг, так как позволяет применять унифицированные материалы для создания конструкций необходимой длины.
Реляционная модель данных
Основной информационной единицей реляционной БД является таблица. База данных может состоять из одной таблицы (однотабличная БД) или из множества взаимосвязанных таблиц (многотабличная БД).
Структурными составляющими таблицы являются записи и поля.
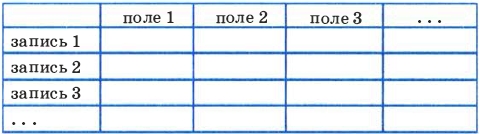
В одной таблице не должно быть повторяющихся записей.
Для каждой таблицы реляционной БД определяется главный ключ — поле или совокупность полей, однозначно определяющих запись. Иначе говоря, значение главного ключа не должно повторяться в разных записях. Например, в библиотечной базе данных в качестве такого ключа может быть выбран инвентарный номер книги, который не может совпадать у разных книг.
Для строчного представления структуры таблицы применяется следующая форма:
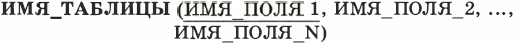
Подчеркиваются поля, составляющие главный ключ.
В теории реляционных баз данных таблица называется отношением. Отношение по-английски — relation. Отсюда происходит название «реляционные базы данных». ИМЯ_ТАБЛИЦЫ в нашем примере — это имя отношения. Примеры отношений:

Каждое поле таблицы имеет определенный тип. С типом связаны два свойства поля:
-
множество значений, которые оно может принимать;
- множество операций, которые над ним можно выполнять.
Поле имеет также формат (длину).
Существуют четыре основных типа для полей БД: символьный, числовой, логический и дата. Для полей таблиц БИБЛИОТЕКА и БОЛЬНИЦА могут быть установлены следующие типы:

В нашем случае поле ПЕРВИЧНЬШ показывает, поступил больной в больницу с данным диагнозом впервые или повторно. Те записи, где значение этого поля равно TRUE (ИСТИНА), относятся к первичным больным, значение FALSE (ЛОЖЬ) отмечает повторных больных. Таким образом, поле логического типа может принимать только два значения.
В таблице БОЛЬНИЦА используется составной ключ — состоящий из двух полей: ПАЛАТА и НОМЕР_МЕСТА. Только их сочетание не повторяется в разных записях (ведь фамилии пациентов могут совпадать).
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Преимущества и недостатки
Надлежащие системы управления базами данных помогают получить лучший доступ к данным, а также оптимизировать управление ими. В свою очередь, точечный доступ помогает конечным пользователям быстро и эффективно обмениваться данными в рамках выполнения задач организации.
|
Модель базы данных |
Год создания |
Преимущества |
Недостатки |
|
Иерархическая |
1960-й |
Очень быстрый доступ для чтения, четкая структура, технически простой. |
Исправлена структура в дереве, которая не допускает связи между деревьями. |
|
Сетевая |
Начало 1970-х |
Поддерживает несколько способов доступа к записи, без строгой иерархии. |
Плохой обзор с большими базами данных. |
|
Реляционная |
1970-й |
Простое, гибкое создание и редактирование, легко расширяемое, быстрый ввод в эксплуатацию, простое расширение, быстрый запуск, очень динамичный контекст. |
Неуправляемый с большими объемами данных, плохой сегментацией, атрибутами искусственного ключа, внешним интерфейсом программирования, плохо отражает свойства и поведение объектов. |
|
Ориентирована на объекты |
Конец 1980-х |
Лучшая поддержка объектноориентированных языков программирования, хранение мультимедийного контента. Поддерживает объектноориентированные языки программирования, позволяет хранить мультимедийный контент. |
Более низкая производительность с большими объемами данных, мало совместимых интерфейсов. |
|
Ориентирована на документы |
1980-е |
Соответствующие данные хранятся централизованно в независимых документах, свободной структуре, концепции мультимедиа, относится к классификации сущностей БД. |
Организационная работа относительно высока, часто требует навыков программирования. |
Сверхбольшие базы данных
Сверхбольшая база данных (англ. Very Large Database, VLDB) — это база данных, которая занимает чрезвычайно большой объём на устройстве физического хранения. Термин подразумевает максимально возможные объёмы БД, которые определяются последними достижениями в технологиях физического хранения данных и в технологиях программного оперирования данными.
Количественное определение понятия «чрезвычайно большой объём» меняется во времени. Так, в 1997 году самой большой в мире была текстовая база данных Knight Ridder’s DIALOG объёмом 7 терабайт. В 2001 году самой большой считалась база данных объёмом 10,5 терабайт, в 2003 году — объёмом 25 терабайт. В 2005 году самыми крупными в мире считались базы данных с объёмом хранилища порядка сотни терабайт. В 2006 году поисковая машина Google использовала базу данных объёмом 850 терабайт.
К 2010 году считалось, что объём сверхбольшой базы данных должен измеряться по меньшей мере петабайтами.
В 2011 году компания хранила данные в кластере из 2 тысяч узлов суммарной ёмкостью 21 петабайт; к концу 2012 года объём данных Facebook достиг 100 петабайт, а в 2014 году — 300 петабайт.
К 2014 году по косвенным оценкам компания хранила на своих серверах до 10—15 эксабайт данных в совокупности.
По некоторым оценкам, к 2025 году генетики будут располагать данными о геномах от 100 миллионов до 2 миллиардов человек, и для хранения подобного объёма данных потребуется от 2 до 40 эксабайт.
В целом, по оценкам компании IDC, суммарный объём данных «цифровой вселенной» удваивается каждые два года и изменится от 4,4 зеттабайта в 2013 году до 44 зеттабайт в 2020 году.
Исследования в области хранения и обработки сверхбольших баз данных VLDB всегда находятся на острие теории и практики баз данных. В частности, с 1975 года проходит ежегодная конференция International Conference on Very Large Data Bases («Международная конференция по сверхбольшим базам данных»). Большинство исследований проводится под эгидой некоммерческой организации VLDB Endowment (Фонд целевого капитала «VLDB»), которая обеспечивает продвижение научных работ и обмен информацией в области сверхбольших БД и смежных областях.
Виды баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных», по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных
Примеры:
- Иерархическая
- Объектная и объектно-ориентированная
- Объектно-реляционная
- Реляционная
- Сетевая
- Функциональная.
Классификация по среде постоянного хранения
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.В оперативную память СУБД помещает лишь кэш и данные для текущей обработки.
- В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Примеры:
- Географическая
- Историческая
- Научная
- Мультимедийная
- Клиентская.
Классификация по степени распределённости
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
-
Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Принципы создания
Каждая таблица, которую еще называют отношением в реляционной базе СУБД, содержит один или ряд категорий данных в столбцах атрибутах. Каждая строка называется записью, или кортежем, содержит уникальный экземпляр данных или ключ для категорий, установленных столбцами. Таблица имеет уникальный первичный ключ, идентифицирующий информацию в ней. Табличная связь устанавливается с помощью внешних ключей, ссылающихся на первичные ключи иной таблицы.
Например, типичная реляционная база СУБД бизнес-заказов имеет таблицу, в которой описывается клиент, со столбцами для имени, адреса, номера телефона и другой информации. Следующая имеет заказ: продукт, клиент, дата, цена продажи и так далее. Пользователь РБД получает представление о базе данных в соответствии со своими потребностями. Например, менеджеру филиала может понравиться просмотр или отчет обо всех клиентах, которые купили товары после определенной даты. Специалист по финансовым услугам в той же компании из тех же таблиц получает отчет о счетах, которые необходимо оплатить.
Особенности реляционных БД
Определение 1
Реляционные базы данных (РБД) представляют собой совокупности связанных посредством ключевых полей таблиц, данные в которых хранятся в виде разбитых на поля записей-строк. Набор полей в каждой строке таблицы одинаков. Данные из таблиц извлекаются с помощью запросов на языке SQL, в который заложены возможности фильтрации, сортировки и группировки данных.
Наиболее популярные современные реализации РБД:
- Oracle Database;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- DB2.
Достоинства РБД:
- зрелость кодовой базы;
- наличие обширной документации;
- принятие сообществом разработчиков стандартов SQL как давней и неоспоримой традиции;
- большое количество специалистов по РБД на рынке труда;
- все они соответствуют принципу ACID (Atomicity — Атомарность, Consistency — Согласованность, Isolation — Изолированность, — Долговечность).
Недостатки РБД:
- не приспособлены для работы с нерегулярными (отличающимися от табличных) структурами;
- плохая совместимость между различными реализациями РДБ (например, данные, хранящиеся в формате MySQL невозможно обрабатывать средствами PostgreSQL без дополнительной конвертации);
- высокие затраты на проектирование баз данных (создание таблиц и установление взаимосвязей между ними), что особенно ощущается в простых проектах;
- необходимость разворачивать и настраивать ПО (сервер БД), требующее предварительной настройки и определенной производительности компьютера (подчас довольно высокой).