Заспамленность и вода в тексте: что это такое
Содержание:
- Алгоритмы проверки уникальности текстов
- Объем текста
- Плотность ключевых слов в тексте
- Эмиссия денег — плюсы и минусы
- Как узнать, заспамлен ли текст
- Настройка программ по проверке уникальности
- Самоцитирование в дипломе
- Влияние заспамленности текста на место в выдаче
- Как удалить воду в тексте?
- Программы проверки уникальности
- Что значит заспамленность текста
- Программы проверки уникальности
- Reference comments
- Влияние «воды» в тексте на оптимизацию
- Что такое заспамленность текста?
- Что значит уникальность текста в антиплагиате
- Алгоритмы проверки уникальности текстов
- Тошнотность
- «Отключение» опции автоотключения
Алгоритмы проверки уникальности текстов
Они бывают шингловыми или корреляционными. Программа для выявления плагиата может быть основана на одном из этих алгоритмов или сразу обоих.
Шингловые алгоритмы
Здесь за основу берется выявление совпадений текстовых фрагментов. Принцип работы следующий:
- Сначала из текста удаляются все стоп-слова: знаки препинания, союзы, предлоги, местоимения, причастия, междометия, частицы, вводные слова и другие элементы, которые не несут смысловой нагрузки.
- Очищенный от стоп-слов текст разбивается на фрагменты заданной в настройках длины, называемые шинглами.
- Составляются фразы для поисковых систем, указанных в настройках. В результате отработанных запросов алгоритм получает множество страниц, с которыми в итоге и будет сравниваться исследуемый текст. О том, как именно это делается, разработчики умалчивают.
- На этих страницах алгоритм ищет вхождения шинглов. Детального описания, как они это делают, вы тоже нигде не найдете.
В результате мы получаем общее значение уникальности текста, а также неуникальные фразы и ссылки на страницы с ними. Видя, какие именно фрагменты нужно уникализировать, копирайтер может улучшить этот показатель.
Корреляционные (нешингловые) алгоритмы
В этом случае тексты проверяются на схожесть по смыслу. Подробной информации о корреляционных алгоритмах я не смог найти. Известно лишь, что они строже и лучше обнаруживают рерайты, поскольку сравнивают статьи целиком, а не по фрагментам.
Объем текста
Чем важен: сам по себе — ничем, т.к. это может быть «вода», однако, как показывают результаты некоторых исследований, большие тексты ранжируются лучше. Кроме того, обычно по ТЗ требуется определенный объем или «вилка» (что на мой взгляд, предпочтительный вариант). Да и платят многие за «килознаки». Поэтому надо мерять.
Чем проверить: определяется любым сервисом, например, уже рассмотренным выше Istio.com.
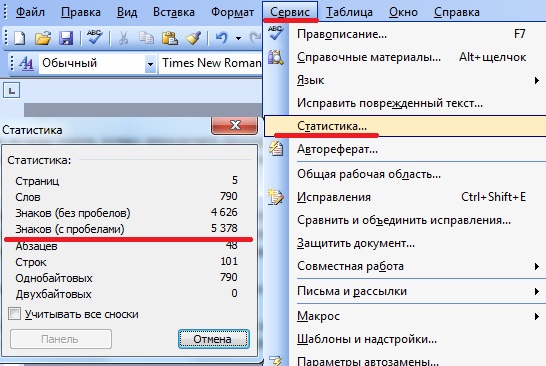
Определение объема текста через сервис Istio.com.
Либо в том же Word:
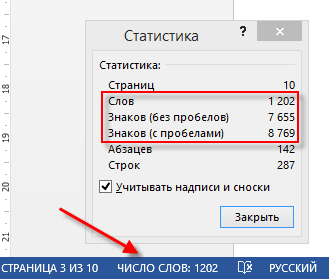
Определение объема текста через MS Word.
Либо в text.ru или любом другом сервисе проверки уникальности текста:
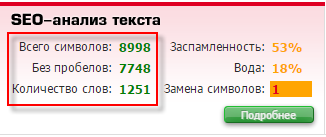
Измерение объема текста через MS Word.
Время на проверку: пару секунд.
Плотность ключевых слов в тексте
Сколько же ключей можно использовать в рамках одного текста на 3-4 тыс. символов? По частотности все ключи условно делятся на низкочастотные (менее 100 раз в месяц по вордстату), среднечастотные (от 100 до 1000) и высокочастотные (свыше 1000). Чем более высокочастотный ключ – тем больше траффика из поисковых систем можно собрать. Но и конкуренция, разумеется, выше. Поэтому в рамках одного текста нужно использовать как ВЧ-ключи, так и СЧ, и НЧ.
Четких указаний, сколько ключей можно использовать в одном тексте, не существует, но чем больше ключей вы хотите использовать, тем более длинный текст придется писать. Я обычно в тексте на 3-4 тыс. знаков использую около 10 ключей (1-2 ВЧ, 3-4 СЧ и 5-6 НЧ – т.е. в пропорции 1:4:6).
Некоторые seo-специалисты считают оптимальную плотность ключей 3-4% от общего количества слов в тексте, другие – 5-7%. Исходя из этих двух полярных мнений, максимальная плотность ключевиков в тексте не должна превышать 7% и быть меньше 3% (при плотности 1-2% ключ работает хуже). 3-7% – вот та плотность, на которую вам нужно ориентироваться. Я же в своих текстах не превышаю среднюю арифметическую плотность в 5%.
Эмиссия денег — плюсы и минусы
Как узнать, заспамлен ли текст
Определить показатель заспамленности можно в онлайн-сервисах. Наиболее популярные среди бесплатных — Text.ru и Advego. Первый указывает количество спама, воды, подсвечивает орфографические ошибки и определяет уникальность.

В Advego наличие спама в тексте определяется показателями тошнотности: академической и классической. Считается, что максимальное значение классической тошноты — 7, академической — 9%. В данном случае классическая тошнота определяется как квадратный корень количества используемых ключевых запросов. Приведу пример: если вы используете слово в тексте 16 раз, этот показатель равен 4.
Академическая тошнота рассчитывается по формуле:
кол-во ключевых слов × 100 / общее кол-во символов без пробелов
Например, если вы упоминаете слово в тексте 8 раз, а общее количество символов составляет 7000, показатель академической тошноты составит 11%.

Дополнительно сервис подсчитывает количество символов, орфографических ошибок, стоп-слов и выдаёт список предполагаемых ключевых фраз.

По этому списку легко определить, какие слова используются в тексте чаще всего. В онлайн-версии Advego есть как SEO-анализ текста на заспамленность, так и проверка на плагиат.
Ещё один сервис для семантического анализа текста — Miratext. Он рассчитывает показатели по закону Ципфа и определяет количество символов, показатели тошноты, водянистости и показывает общее значение качества текста.

Считается, что показатель тошноты не должен быть выше 7.
Настройка программ по проверке уникальности
Кроме размера шингла и поисковой фразы, существует еще ряд параметров, доступных в программах Advego Plagiatus и «eTXT Антиплагиат». Разберем самые важные из них:
- Поисковые системы — помимо стандартного набора («Яндекс» и Google) программа может также поддерживать Yahoo, Bing и другие сервисы. Подключать их имеет смысл для текстов на иностранных языках, в противном случае вы только потеряете время.
- Прокси — используя прокси-сервер, вы можете минимизировать риск бана вашего IP при проверке текстов. Чтобы активировать эту функцию, введите в соответствующих полях адрес сервера, порт, логин и пароль.
- Таймаут — время, в течение которого программа будет ждать ответа от запрашиваемого сайта. Увеличивать это значение следует при частом превышении интервала ожидания, уменьшать особого смысла нет — проверка будет проходить быстрее, но некоторые сайты могут не успеть ответить. По умолчанию таймаут в Advego Plagiatus составляет 15 с, в AntiPlagiarism.NET — 30 с.
Самоцитирование в дипломе
При написании дипломной работы использование самоцитирования также уместно. Если студент за время обучения в вузе успел опубликовать научные статьи, то их фрагменты могут стать частью текста диплома.
Подготовка и защита дипломной работы не предполагает обязательного наличия у автора статей в научной периодике, поэтому в этом случае ссылки на уже опубликованные работы студента будут оцениваться положительно.
Текст авторской статьи необходимо переработать, а источник включить в список использованной литературы. В тексте дипломной работы уместным будет перефразирование собственной статьи студента: это позволит сохранить высокий процент уникальности текста и сообщить читателям о наличии публикаций у автора.
Влияние заспамленности текста на место в выдаче
Обилие бесполезного материала отражается на репутации сайта, число его посетителей падает. Такое поведение учитывается системой, и позиции ресурса в выдаче снижаются.
Системы индексируют сайты, проверяя их на использование искусственных способов оптимизации. Поисковая машина не оповещает о наложении фильтра, однако об этом свидетельствуют изменения, касающиеся ресурса:
- выпадение страниц из индекса;
- отсутствие позиционного роста;
- снижение трафика;
- недоступность в выдаче при использовании ключевых фраз.
Основные санкции, применяемые к нарушителям:
- Выборочное исключение. Из выдач устраняются некоторые страницы сайта.
- Пессимизация. Занижаются позиции веб-ресурса.
- Бан. Сайт полностью исключается из индекса и выдачи.
Тип санкций зависит от причин, повлекших за собой ограничительные меры.
Фильтры «Яндекса»
В таблице представлены различные виды фильтров.
| Наименование | Назначение |
|---|---|
| «АГС» (17 и 30) | Используется для борьбы с сателлитами и многостраничными ресурсами, созданными для продажи ссылок |
| «Непот» | Применяется против распространения ссылочного спама и активной продажи ссылок |
| «Редирект-фильтр» | Используется для исключения из индекса сайтов-дорвеев |
| «Ты последний» | Накладывается на ресурсы с дублированным контентом, после чего они не появляются в выдаче по ключевым фразам |
| «Ты спамный» | Применяется для удаления из индекса страниц с повышенной плотностью ключевых слов |
| «Фильтр аффилиатов» | Накладывается на многочисленные сайты, продвигаемые по одному ключевому запросу. В поисковой выдаче остается один, наиболее релевантный, ресурс |
По механизму использования фильтры системы «Яндекс» делятся на автоматические и ручные.
Поисковик Google
В таблице перечислены основные фильтры системы с описанием условий их применения.
| Название | Причины использования |
|---|---|
| «Панда» | Низкая оптимизация ресурса:
|
| «Пингвин» | Преднамеренное увеличение ссылочной массы:
|
| «Песочница» | Малый срок существования сайта, низкий уровень доверия к нему |
| «Колибри» | Оптимизация страниц под ключевой запрос при игнорировании смысловой нагрузки |
Кроме указанных фильтров Google существует ряд других, более специализированных и менее жестких. Среди них — Bowling, Bombing, «Дополнительные результаты» и пр.
Как удалить воду в тексте?
Чтобы уменьшить воду в тексте, нужно избавиться от стоп-слов. Будь уверен: если ты сотрёшь хотя бы свои бесчисленные «стоит заметить», «хочется сказать», «нельзя не отметить» (то есть вводные слова), станет лучше. Он точно не потеряет ни капли смысловой нагрузки.
Попробуем убрать воду из текста на примере отрывка из плохенькой статейки, посвящённой паркам Москвы (источник – moskvapark.naidich.ru).

Сервис Text.ru показывает двукратное превышение нормы воды в тексте – 20%.
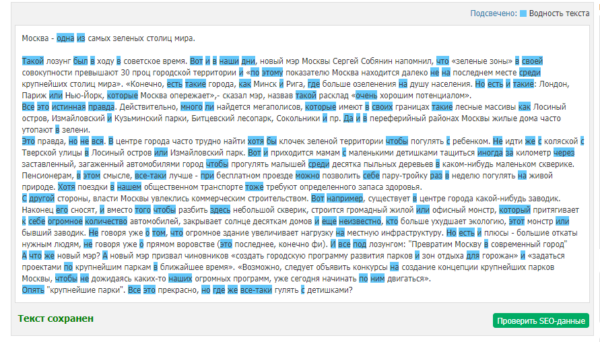
Приступаем к редактуре. Визуально определяем самые массивные «водные» блоки и работаем с ними в первую очередь:
- «Вот и в наши дни» во втором предложении – целых 5 «водных» слов кряду! Меняем на слово «Сейчас».
- В предложении «Но есть и такие: Лондон, Париж или Нью-Йорк, которые Москва опережает» полностью удаляем «водное» начало. Переформулируем так: «Зато Лондон, Париж и Нью-Йорк Москва опережает». Предложение не утратит информативности и органично впишется по смыслу.
- Предложение «Все это истинная правда» – вода на 100%. Я бы его удалил полностью, но если вы считаете, что оно все же нужно, можно сократить до «Это правда».
- Есть ещё оборот «офисный монстр, который притягивает к себе огромное количество автомобилей». Замените на «офисный монстр, притягивающий множество автомобилей». Использовать причастия – не всегда хорошо для читабельности, но при высокой водности так можно избавиться от стоп-слова «который».
Выполнив эти 4 действия, мы проверяем снова и видим: содержание воды сократилось до 17%.
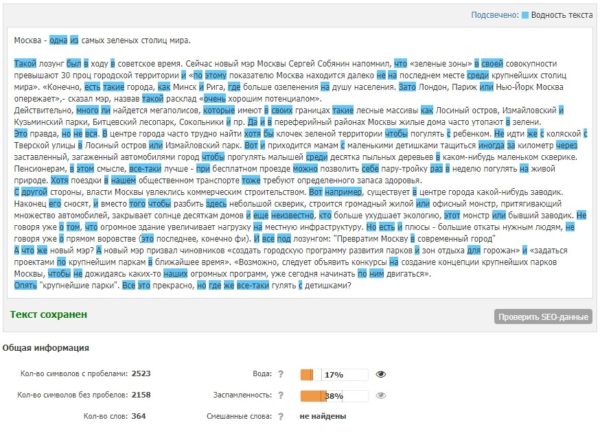
Этого, конечно, недостаточно, но, думаю, принцип работы с текстом понятен.
Программы проверки уникальности
Их довольно много, поэтому рассмотрим только самые известные системы.
Advego Plagiatus
Одна из самых распространенных бесплатных антиплагиат-программ, основанная на двух алгоритмах: шингловом и лексических совпадений. Также в ней реализована технология псевдоуникализации, позволяющая обнаружить подмену русских букв на английские и другие нечестные способы повышения уникальности. Сервис имеет все основные функции и настройки, которых в большинстве случаев достаточно для проверки текстов.
Особенности Advego Plagiatus:
- Два способа проверки — быстрая и полная.
- Поддержка двух декапчеров — Antigate и собственного «Адвего Антикапча».
- Возможность выбора поисковых систем — «Яндекс», Google, «Рамблер», Yahoo, Bing, Baidu и т. д.
- Отображение в результатах уникальности по фразам и словам — результаты работы обоих алгоритмов.
- Функция «Игнорировать URL при проверке» — удобно, если нужно доработать текст на проиндексированной странице.
- размер шингла и фразы — 4;
- таймаут — 3 с;
- максимальный размер документа — 1000 килобайт;
- прерывание проверки — 0 %;
- учет совпадений — от 0.5 %;
- поисковые системы — «Яндекс» и Google.
Текущая версия программы на 15.04.2019 совместима с операционными системами Windows XP и выше, Linux и macOS.
AntiPlagiarism.NET («eTXT Антиплагиат»)
Эта программа отличается впечатляющим набором возможностей, в том числе не имеющих никакого отношения к уникальности. Основана AntiPlagiarism.NET на двух алгоритмах: «Метод обнаружения копий» (шингловый) и «Метод обнаружения рерайта» (корреляционный).
Ключевые особенности:
- Четыре основных режима проверки: стандартная, экспресс, глубокая, на рерайт.
- Поддержка антикапчеров — в настройках можно ввести адрес любого сервиса и ключ.
- Проверка текстов в пакетном режиме — для этого достаточно указать папку, где находятся файлы.
- Проверка сайта — в этом случае программа самостоятельно скачивает текст по указанному адресу.
- Онлайн-проверка — возможность анализа текстов без установки каких-либо программ и без риска блокировки IP поисковыми системами (бесплатно можно проверять только несколько текстов в день).
- Сравнение текстов — удобная функция, позволяющая сравнить две статьи между собой. Удобно для проверки нескольких рерайтов одного и того же исходника.
- Проверка уникальности изображения — новая функция, позволяющая сравнить два графических файла.
- SEO-сервис — определение более 10 параметров сайта (тИЦ, PR, дата регистрации домена и т. д.). Адреса ресурсов можно вводить списком.
Удобно, что в настройках имеется несколько предустановленных профилей и кнопка «По умолчанию», позволяющая вернуть все установки в исходные значения.
Программа AntiPlagiarism.NET («eTXT Антиплагиат») существует в нескольких вариантах: для Windows, Linux и MacOS.
TEXT.RU
Онлайновый сервис, основанный на корреляционном алгоритме. Мнения интернет-общественности об этой системе отличаются — одни хвалят ее за способность выявлять рерайтинг, другие жалуются на то, что ей крайне сложно угодить.
От лица нашей группы могу сказать, что нешингловый алгоритм text.ru часто мешает писать хорошие тексты. Выбирая эту систему как основное мерило уникальности, будьте готовы попрощаться с красивыми устойчивыми выражениями. В погоне за непохожестью вы можете получить безликие конструкции и странные сочетания слов.
Особенности сервиса:
- отсутствие каких-либо настроек и режимов проверки;
- проверка выполняется в режиме онлайн, то есть прямо в браузере;
- возможность добавить проверку текста в очередь, не ожидая ее окончания;
- размер текста для незарегистрированных пользователей — 2000, после регистрации — 15 000 знаков;
- формирование ссылок на результаты проверок, доступ к ним;
- возможность установить на своем сайте счетчик уникальности — своего рода защита против воров контента.
Content Watch
Как и text.ru, этот сервис основан на корреляционном алгоритме. По результатам он нам показался очень похожим на вышеупомянутый инструмент. Особенности:
- Без регистрации можно проверить до 5 текстов в день размером не более 3000 знаков. Зарегистрированным пользователям доступно 20 проверок по 20 000 знаков.
- Платные тарифы, с которыми можно выполнять от 100 до 500 проверок в день и активировать функцию регулярной проверки страниц вашего сайта на уникальность.
- Возможность проверять сайты, в том числе в пакетном режиме.
Что значит заспамленность текста
Ключевые фразы строятся по поисковым запросам. Разные люди формулируют одно и то же по-разному. Во время поиска они делают ошибки, сокращают слова, смешивают кириллицу и латиницу. Излив смесителя превращается в носик или гусак, Россия теряет одну букву “с”. И специалисты по продвижению пишут такие названия и описания видеороликов:
Из описания сразу можно выделить ключи:
- где найти прокладки для гусака;
- где найти прокладки для излива в ванной;
- прокладки для излива заменить;
- какой размер прокладки;
- как подобрать прокладку.
На все эти вопросы, которые повторяют друг друга, отвечает видеоролик. Его описание — пример переспама ключами. Да, он попадет в выдачу по нескольким запросам. Но текст выглядит неграмотным и бессмысленным.
В названии заспамленности нет, потому что поисковики не различают синонимы.
Заспамленные тексты низкого качества. Они пишутся для роботов, а не для людей. Повторение одного и того же ключа нарушает целостность текста. Написать полезный текст, вписывая в каждую фразу «купить недорого», «автошины цена» или «заказ такси СПб» проблематично.
Программы проверки уникальности
Их довольно много, поэтому рассмотрим только самые известные системы.
Advego Plagiatus
Одна из самых распространенных бесплатных антиплагиат-программ, основанная на двух алгоритмах: шингловом и лексических совпадений. Также в ней реализована технология псевдоуникализации, позволяющая обнаружить подмену русских букв на английские и другие нечестные способы повышения уникальности. Сервис имеет все основные функции и настройки, которых в большинстве случаев достаточно для проверки текстов.
Особенности Advego Plagiatus:
- Два способа проверки — быстрая и полная.
- Поддержка двух декапчеров — Antigate и собственного «Адвего Антикапча».
- Возможность выбора поисковых систем — «Яндекс», Google, «Рамблер», Yahoo, Bing, Baidu и т. д.
- Отображение в результатах уникальности по фразам и словам — результаты работы обоих алгоритмов.
- Функция «Игнорировать URL при проверке» — удобно, если нужно доработать текст на проиндексированной странице.
Рекомендуемые разработчиком настройки Advego Plagiatus:
- размер шингла и фразы — 4;
- таймаут — 3 с;
- максимальный размер документа — 1000 килобайт;
- прерывание проверки — 0 %;
- учет совпадений — от 0.5 %;
- поисковые системы — «Яндекс» и Google.
AntiPlagiarism.NET («eTXT Антиплагиат»)
Эта программа отличается впечатляющим набором возможностей, в том числе не имеющих никакого отношения к уникальности. Основана AntiPlagiarism.NET на двух алгоритмах: «Метод обнаружения копий» (шингловый) и «Метод обнаружения рерайта» (корреляционный).
Ключевые особенности:
- Четыре основных режима проверки: стандартная, экспресс, глубокая, на рерайт.
- Поддержка антикапчеров — в настройках можно ввести адрес любого сервиса и ключ.
- Проверка текстов в пакетном режиме — для этого достаточно указать папку, где находятся файлы.
- Проверка сайта — в этом случае программа самостоятельно скачивает текст по указанному адресу.
- Онлайн-проверка — возможность анализа текстов без установки каких-либо программ и без риска блокировки IP поисковыми системами (бесплатно можно проверять только несколько текстов в день).
- Сравнение текстов — удобная функция, позволяющая сравнить две статьи между собой. Удобно для проверки нескольких рерайтов одного и того же исходника.
- Проверка уникальности изображения — новая функция, позволяющая сравнить два графических файла.
- SEO-сервис — определение более 10 параметров сайта (тИЦ, PR, дата регистрации домена и т. д.). Адреса ресурсов можно вводить списком.
Удобно, что в настройках имеется несколько предустановленных профилей и кнопка «По умолчанию», позволяющая вернуть все установки в исходные значения.
Программа AntiPlagiarism.NET («eTXT Антиплагиат») существует в нескольких вариантах: для Windows, Linux и MacOS.
TEXT.RU
Онлайновый сервис, основанный на корреляционном алгоритме. Мнения интернет-общественности об этой системе отличаются — одни хвалят ее за способность выявлять рерайтинг, другие жалуются на то, что ей крайне сложно угодить.
От лица нашей группы могу сказать, что нешингловый алгоритм text.ru часто мешает писать хорошие тексты. Выбирая эту систему как основное мерило уникальности, будьте готовы попрощаться с красивыми устойчивыми выражениями. В погоне за непохожестью вы можете получить безликие конструкции и странные сочетания слов.
Особенности сервиса:
- отсутствие каких-либо настроек и режимов проверки;
- проверка выполняется в режиме онлайн, то есть прямо в браузере;
- возможность добавить проверку текста в очередь, не ожидая ее окончания;
- формирование ссылок на результаты проверок, доступ к ним;
- возможность установить на своем сайте счетчик уникальности — своего рода защита против воров контента.
Content Watch
Как и text.ru, этот сервис основан на корреляционном алгоритме. По результатам он нам показался очень похожим на вышеупомянутый инструмент. Особенности:
- Бесплатная версия позволяет проверять до трёх текстов в день размером не более 10 тысяч знаков каждый.
- С платными тарифами расширены лимиты на количество и размер текстов, есть история проверок за месяц, нет рекламы.
- Возможность проверять сайты, в том числе в пакетном режиме.
На 30.04.2020 сервис предлагает следующие месячные тарифы на ручную проверку текстов:
- 150 проверок в день — 140 рублей;
- 1000 проверок в день — 590 рублей;
- 3000 проверок в день — 1490 рублей.
Reference comments
Влияние «воды» в тексте на оптимизацию
Продвижение материала в топ выдачи — непростая задача. Главным акцентом для поисковых роботов служит информация и польза для людей.
Проверять текст на водность нужно по двум причинам:
1. Статья, перенасыщенная «водой» и текстовым мусором, непонятна читателям. Пользователи быстро утрачивают интерес к материалу и не находят для себя полезной информации. Такое ухудшение поведенческого фактора автоматически снижает частоту запросов.
2. Слишком высокий процент воды в тексте — причина понижения ресурса в выдаче.
Ориентир проверки водности — стоп-слова. Чем их больше, тем менее полезной считается страница.
Часто используемые стоп-слова:
- прилагательные, не раскрывающие существенную информацию (самый лучший инструмент, истинная история, невероятный эпизод);
- частицы, союзы, предлоги (ведь, только, или, даже, пусть, зато, словно);
- междометия (Караул!, Алло!, Айда!, Марш!);
- местоименные наречия, местоимения (всячески, отовсюду, поэтому, когда-либо);
- вводные слова (следовательно, безусловно, достоверно известно, как принято).
Процент водности значительно улучшится, если свести к минимуму использование таких и аналогичных стоп-слов. Из текста нужно убрать все формулировки, без которых смысл и ценность написанного не изменяется.
Что такое заспамленность текста?
Заспамленность текста – это отношение количества употреблений одного слова к общему числу слов в тексте.
Рассмотрим на примере: в статье про автомобили встречается слово «ремонт» 20 раз, всего она из 600 слов. Производим банальное арифметическое действие:
Выходит, статья более чем на 3% состоит всего из одного слова. Это, разумеется, нехорошо. Смекалистые поисковые роботы «Яндекс» и Google сообразят, что статья написана вовсе не для «живых» читателей, а в угоду искусственному интеллекту. И она быстренько попадёт под фильтр.
В марте 2017 года появился знаменитый фильтр «Яндекса» «Баден-Баден», безжалостно отсекавший (и до сих пор отсекающий) весь заспамленный контент.

Понятие заспамленности очень тесно связано с другим понятием – тошнотностью. Но бороться с заспамленностью (или переспамом, как ещё называют) с точки зрения копирайтера куда проще, чем понижать тошноту.
Важное замечание. Поисковик может посчитать статью заспамленной, даже если число употреблений ключевых вхождений невелико – но при этом они стоят рядом или даже «слипаются»
Поэтому в ТЗ копирайтерам часто можно встретить требование: размещать ключи равномерно. Если между вхождениями минимум 400 символов – идеально!
Что значит уникальность текста в антиплагиате
Давайте немного проясним ситуацию. Антиплагиат.ру — это система проверки, к которой насильно подключили ВУЗы России. С ней можно работать на двух уровнях.
- “Интернет” (проверка только по открытым источникам). Этот уровень доступен студентам.
- “Интернет+закрытые базы” (база сданных работ, база “кольца ВУЗов”, база РГБ и другие). Этот уровень доступен только преподавателям.
Уникальность — показатель, который отображает совпадение текста в вашей работе и всех базах. При этом поиск ведется по точным совпадениям.
Если проверять текст на антиплагиат по двум описанным выше уровням, процент уникальности будет отличаться. Это обусловлено дополнительными закрытыми базами, которые влияют на результат. Например, даже если в открытых источниках работы нет, велика вероятность, что дубликат найдется в базе “кольца ВУЗов”. Особенно для тех работ, которые “кочуют” по общежитиям и передаются от старшего поколения студентов к младшему.
Алгоритмы проверки уникальности текстов
Они бывают шингловыми или корреляционными. Программа для выявления плагиата может быть основана на одном из этих алгоритмов или сразу обоих.
Шингловые алгоритмы
Здесь за основу берется выявление совпадений текстовых фрагментов. Принцип работы следующий:
- Сначала из текста удаляются все стоп-слова: знаки препинания, союзы, предлоги, местоимения, причастия, междометия, частицы, вводные слова и другие элементы, которые не несут смысловой нагрузки.
- Очищенный от стоп-слов текст разбивается на фрагменты заданной в настройках длины, называемые шинглами.
- Составляются фразы для поисковых систем, указанных в настройках. В результате отработанных запросов алгоритм получает множество страниц, с которыми в итоге и будет сравниваться исследуемый текст. О том, как именно это делается, разработчики умалчивают.
- На этих страницах алгоритм ищет вхождения шинглов. Детального описания, как они это делают, вы тоже нигде не найдете.
В результате мы получаем общее значение уникальности текста, а также неуникальные фразы и ссылки на страницы с ними. Видя, какие именно фрагменты нужно уникализировать, копирайтер может улучшить этот показатель.
Корреляционные (нешингловые) алгоритмы
В этом случае тексты проверяются на схожесть по смыслу. Подробной информации о корреляционных алгоритмах я не смог найти. Известно лишь, что они строже и лучше обнаруживают рерайты, поскольку сравнивают статьи целиком, а не по фрагментам.
Тошнотность
Скажу вам честно: меня еще ни разу не стошнило от текста. Даже от самого плохого. Даже от самого спамного и дурацкого. Поэтому этот параметр для меня всегда равен нулю и лично я его в работе не использую.
Академическая тошнота — это отношение количества повторов самого часто употребляемого в документе слова к количеству слов во всем тексте. Если большая (более 5-7%), то это переспам.
Конечно, у разных сервисов могут быть различные способы подсчета тошноты, но проверка на переспам, которая будет рассмотрена ниже, на мой взгляд, позволяет оценить наличие проблем с процентом вхождений фраз.
«Отключение» опции автоотключения
Если ошибка подключения вашего сетевого диска не исчезает, можно ее исправить и через командную строку. Для этого в Пуске введите cmd, нажмите Enter, введите «net config server /autodisconnect:35»
где 35 – это любое произвольное число, исчисляемое в минутах, по окончании которого подключение к сетевому диску будет автоматически прервано.
Нажмите Ок.
Чтобы заставить соединение с диском сбрасываться, впишите в поле значения цифру «0». Это приведет к тому, что сетевые диски будут отключаться через несколько секунд. Для отключения опции автоотключения надо зайти в терминал через ввод cmd в Пуске, прописать «net config server /autodisconnect:-1» и нажать Ввод. Строка прописывается без скобок, только буквы, цифры и слеш.