Обработка строк в python
Содержание:
- Содержание:
- Строчный формат
- Сохранение строк в качестве значения для переменных
- 5 функций для отладки
- Разбиение строки
- String Concatenation
- Что такое строка в Python?
- #2 Форматирование строк “По новому” (str.format)
- String format()
- Как активировать режим разработчика на телефоне андроид
- Атрибут __doc__
- Поиск подстроки в строке
- No binary f-strings
- Комментарии vs строки документации Python
- Скорость
- Форматирование строк
- Нарезка строк
- String Formatting Operator
- python-ideas discussion
- Разновидности жучков
- Почему Вам нужно обратиться именно к нам?
- Произвольные выражения
- Конкатенация строк
- Как выбрать хороший навигатор для автомобиля?
- Создание строк и вывод их на экран
Содержание:
Помните Дзен Python, где должен быть “один очевидный способ сделать что-то в Python”? Можете почесать голову перед тем, как понять, что зачастую есть целых 4 эффективных способа выполнить в Python.
Давайте приступим к делу, работы много! Чтобы иметь в распоряжении простой пример для эксперимента, представим, что у вас есть следующие переменные (или константы, не важно) для работы:
Python
errno = 50159747054
name = ‘Bob’
|
1 |
errno=50159747054 name=’Bob’ |
Основываясь на этих переменных, вы хотите создать строку вывода, содержащую простое уведомление об ошибке:
Python
‘Hey Bob, there is a 0xbadc0ffee error!’
| 1 | ‘Hey Bob, there is a 0xbadc0ffee error!’ |
Эта ошибка может немного подпортить понедельник вашему разрабу… Но мы здесь за тем, чтобы обсудить форматирование строк. Так что приступим к делу.
Строчный формат
Как мы узнали из главы «Python Переменные», мы не можем комбинировать (складывать) строки и числа, как здесь:
Пример
age = 36txt = «My name is John, I am » + ageprint(txt)
Будет выведена ошибка!
Но мы можем комбинировать строки и числа, используя метод !
Метод принимает переданные аргументы, форматирует их и помещает в строку, где заполнители (placeholder) находятся в :
Пример
Используйте метод для вставки чисел в строки:
age = 36txt = «My name is John, and I am {}»print(txt.format(age)) # возвращает My name is John, and I am 36
Метод format() принимает неограниченное количество аргументов и помещается в соответствующие заполнители:
Пример
quantity = 3itemno = 567price = 49.95myorder = «I want {}
pieces of item {} for {} dollars.»print(myorder.format(quantity,
itemno, price)) # возвращает I want 3 pieces of item 567 for 49.95 dollars.
Вы можете использовать индексные номера чтобы убедиться, что аргументы помещены в правильные заполнители:
Пример
quantity = 3itemno = 567price = 49.95myorder = «I want to pay {2}
dollars for {0} pieces of item {1}.»print(myorder.format(quantity,
itemno, price)) # возвращает I want to pay 49.95 dollars for 3 pieces of item 567
Сохранение строк в качестве значения для переменных
В общем смысле слова, переменные являются последовательностью символов, которую вы можете использовать для хранения данных в программе. Например, их можно представить в качестве неких пустых ящиков, в которое вы помещаете различные объекты. Такими объектами может стать любой тип данных, и строки в этом смысле не исключение. Однажды создав переменную, мы сильно упрощаем себе работу со строкой на протяжении всей программы.
Для того чтобы сохранить значение строки внутри переменной, нам просто нужно присвоить строке ее имя. В следующем примере давайте объявим в качестве нашей переменной:
my_str = "Sammy likes declaring strings."
Теперь, когда у нас есть переменная , назначенная нужной нам строке, мы можем вывести ее на экран:
print(my_str)
И получим следующий вывод:
Sammy likes declaring strings.
Использование переменных вместо строк не только дает нам возможность не переписывать строки каждый раз, когда нам это нужно, но также сильно упрощает работу с ними внутри программы.
5 функций для отладки
Эти функции часто игнорируются, но будут полезны для отладки и устранения неисправностей кода.
breakpoint
Если нужно приостановить выполнение кода и перейти в командную строку Python, эта функция вам пригодится. Вызов перебросит вас в отладчик Python.
Эта встроенная функция была добавлена в Python 3.7, но если вы работаете в более старых версиях, можете получить тот же результат с помощью .
dir
Эта функция может использоваться в двух случаях:
- просмотр списка всех локальных переменных;
- просмотр списка всех атрибутов конкретного объекта.
Из примера можно увидеть локальные переменные сразу после запуска и после создания новой переменной .
Если в передать созданный список , на выходе можно увидеть все его атрибуты.
В выведенном списке атрибутов можно увидеть его типичные методы (, , и т. д.) , а также множество более сложных методов для перегрузки операторов.
vars
Эта функция является своего рода смесью двух похожих инструментов: и .
Когда вызывается без аргументов, это эквивалентно вызову , которая показывает словарь всех локальных переменных и их значений.
Когда вызов происходит с аргументом, получает доступ к атрибуту , который представляет собой словарь всех атрибутов экземпляра.
Перед использованием было бы неплохо сначала обратиться к .
type
Эта функция возвращает тип объекта, который вы ей передаете.
Тип экземпляра класса есть сам класс.
Тип класса — это его метакласс, обычно это .
Атрибут даёт тот же результат, что и функция , но рекомендуется использовать второй вариант.
Функция , кроме отладки, иногда полезна и в реальном коде (особенно в объектно-ориентированном программировании с наследованием и пользовательскими строковыми представлениями).
Обратите внимание, что при проверке типов обычно вместо используется функция. Также стоит понимать, что в Python обычно не принято проверять типы объектов (вместо этого практикуется утиная типизация)
help
Если вы находитесь в Python Shell или делаете отладку кода с использованием , и хотите знать, как работает определённый объект, метод или атрибут, функция поможет вам.
В действительности вы, скорее всего, будете обращаться за помощью к поисковой системе. Но если вы уже находитесь в Python Shell, вызов будет быстрее, чем поиск документации в Google.
Разбиение строки
Для анализа текста требуются различные метрики, такие как количество слов, количество символов, средняя длина предложения. Чтобы вычислить эти значения, нам нужно подготовить текст — очистить и разделить. К счастью для нас, в Python есть несколько встроенных функций для разделения текста:
Разбиение по пробелу (по умолчанию):
test_string.split() Out:
Разбиение на определенное количество токенов:
test_string.split(' ', 2)
Out:
Разбиение на определенное количество токенов в обратном направлении:
test_string.rsplit(' ', 2)
Out:
Разбиение по произвольному символу:
test_string.split('e')
Out:
Разбиение строки по нужному токену с токенами до и после него:
test_string.partition('fox')
Out: ('The quick brown ', 'fox', ' jumps over the lazy dog')
String Concatenation
String concatenation means add strings together.
Use the character to add a variable to another variable:
Example
x = «Python is «y = «awesome»z = x + y
print(z)
Example
Merge variable with variable
into variable :
a = «Hello»b = «World»c = a + b
print(c)
Example
To add a space between them, add a :
a = «Hello»b = «World»c = a + » » + b
print(c)
For numbers, the character works as a mathematical operator:
Example
x = 5y = 10print(x + y)
If you try to combine a string and a number, Python will give you an error:
Example
x = 5y = «John»print(x + y)
Python Variables Tutorial
Creating Variables
Variable Names
Assign Value to Multiple Variables
Output Variables
Global Variables
Что такое строка в Python?
Строка в Python — это обычная последовательность символов (букв, цифр, знаков препинания).
Компьютеры не имеют дело с символами, они имеют дело с числами (в двоичной системе). Даже если вы видите символы на вашем экране, внутри памяти компьютера он хранится и обрабатываются как последовательность нулей и единиц.
Преобразование символа в число называется кодированием, а обратный процесс — декодированием. ASCII и Unicode — наиболее популярные из кодировок, которые используются для кодирования и декодирования данных.
В Python, строка — это последовательность символов Unicode. Юникод был введен для включения каждого символа на всех языках и обеспечения единообразия в кодировании.
#2 Форматирование строк “По новому” (str.format)
Python 3 предоставил новый способ форматирования, который также был внесен в раннюю версию Python 2.7. Этот “новый стиль” форматирования строк избавляется от специального синтаксиса оператора % и делает синтаксис для форматирования строк более регулярным. Теперь форматирование обрабатывается вызовом .format() в объекте строки.
Вы можете использовать format(), чтобы выполнить простое позиционное форматирование, также, как мы делали это по старинке:
Python
print(‘Hello, {}’.format(name))
# Вывод: ‘Hello, Bob’
|
1 |
print(‘Hello, {}’.format(name)) # Вывод: ‘Hello, Bob’ |
Или, вы можете сослаться на свои подстановки переменных по имени, и использовать их в том порядке, в котором вам хочется. Это достаточно мощный способ, так как он позволяет повторно упорядочить порядок отображения без изменения переданных функции format() аргументов:
Python
print(
‘Hey {name}, there is a 0x{errno:x} error!’.format(
name=name, errno=errno
)
)
# Вывод: ‘Hey Bob, there is a 0xbadc0ffee error!’
|
1 |
print( ‘Hey {name}, there is a 0x{errno:x} error!’.format( name=name,errno=errno ) ) |
Однако, официальная документация Python 3 не делает явных рекомендаций по использованию старого форматирования:
По этому я лично пытаюсь работать str.format при продвижении нового кода. Начав с Python 3.6, есть еще один способ форматирования ваших строк. Рассмотрим его в следующем разделе!
String format()
The method allows you to format selected parts of a string.
Sometimes there are parts of a text that you do not control, maybe
they come from a database, or user input?
To control such values,
add placeholders (curly brackets ) in the text, and run the values through the
method:
Example
Add a placeholder where you want to display the price:
price = 49txt = «The price is {} dollars»print(txt.format(price))
You can add parameters inside the curly brackets to specify how to convert
the value:
Example
Format the price to be displayed as a number with two decimals:
txt = «The price is {:.2f} dollars»
Check out all formatting types in our String format() Reference.
Как активировать режим разработчика на телефоне андроид
Атрибут __doc__
Всякий раз, когда строковые литералы присутствуют сразу после определения функции, модуля, класса или метода, они становятся специальным атрибутом этого объекта. Позже мы можем использовать этот атрибут для получения этой строки документации.
Пример 2: Вывод на экран строки документации.
def square(n):
'''Принимает число n, возвращает квадрат числа n'''
return n**2
print(square.__doc__)
Результат:
Здесь мы получили доступ к документации нашей функции с помощью атрибута .
Теперь давайте посмотрим на строки документации для встроенной функции :
Пример 3: строки документации для встроенной функции print().
print(print.__doc__)
Результат:
Здесь мы можем видеть, что документация функции представлена как атрибут этой функции.
Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!"
index = welcome.find("wor")
print(index) # 6
# ищем с десятого индекса
index = welcome.find("wor",10)
print(index) # 21
# ищем с 10-го по 15-й индекс
index = welcome.find("wor",10,15)
print(index) # -1
No binary f-strings
For the same reason that we don’t support bytes.format(), you may
not combine 'f' with 'b' string literals. The primary problem
is that an object’s __format__() method may return Unicode data that
is not compatible with a bytes string.
Binary f-strings would first require a solution for
bytes.format(). This idea has been proposed in the past, most
recently in PEP 461 . The discussions of such a feature usually
suggest either
- adding a method such as __bformat__() so an object can control
how it is converted to bytes, or - having bytes.format() not be as general purpose or extensible
as str.format().
Комментарии vs строки документации Python
Комментарии Python
Комментарии — это описания, которые помогают программистам лучше понять назначение и функциональность программы. Они полностью игнорируются интерпретатором Python.
В Python мы используем символ для написания однострочного комментария. Например,
# Программа для вывода на экран строки "Hello World"
print("Hello World")
Комментарии Python с использованием строк
Если мы не присваиваем строки какой-либо переменной, они ведут себя как комментарии. Например,
"Я однострочный комментарий"
'''
Я
многострочный
комментарий!
'''
print("Hello World")
Примечание. Мы используем тройные кавычки для многострочных строк.
Строки документации Python
Как упоминалось выше, строки документации в Python — это строки, которые пишутся сразу после определения функции, метода, класса или модуля (как в примере 1). Они используются для документирования нашего кода.
Мы можем получить доступ к этим строкам документации, используя атрибут .
Скорость
Буква f в f-strings может также означать и “fast”. Наши f-строки заметно быстрее чем % и () форматирования. Как мы уже видели, f-строки являются выражениями, которые оцениваются по мере выполнения, а не постоянные значения. Вот выдержка из документации:
Во время выполнения, выражение внутри фигурных скобок оценивается в собственной области видимости Python и затем сопоставляется со строковой литеральной частью f-строки. После этого возвращается итоговая строка. В целом, это все.
Рассмотрим сравнение скорости:
Python
>>> import timeit
>>> timeit.timeit(«»»name = «Eric»
… age = 74
… ‘%s is %s.’ % (name, age)»»», number = 10000)
0.003324444866599663
|
1 |
>>>importtimeit >>>timeit.timeit(«»»name = «Eric» … age = 74 … ‘%s is %s.’ % (name, age)»»»,number=10000) |
Python
>>> timeit.timeit(«»»name = «Eric»
… age = 74
… ‘{} is {}.’.format(name, age)»»», number = 10000)
0.004242089427570761
|
1 |
>>>timeit.timeit(«»»name = «Eric» … age = 74 … ‘{} is {}.’.format(name, age)»»»,number=10000) |
Python
>>> timeit.timeit(«»»name = «Eric»
… age = 74
… f'{name} is {age}.'»»», number = 10000)
0.0024820892040722242
|
1 |
>>>timeit.timeit(«»»name = «Eric» … age = 74 … f'{name} is {age}.'»»»,number=10000) |
Как вы видите, f-строки являются самыми быстрыми.
Однако, суть не всегда в этом. После того, как они реализуются первыми, у них есть определенные проблемы со скоростью и их нужно сделать быстрее, чем str.format(). Для этого был предоставлен специальный опкод BUILD_STRING.
Форматирование строк
Форматирование строк (также известно как замещение) – это замещение значений в базовой строке. Большую часть времени вы будете вставлять строки внутри строк, однако, вам также понадобиться вставлять целые числа и числа с запятыми в строки весьма часто. Существует два способа достичь этой цели. Начнем с старого способа, после чего перейдем к новому:
Python
# -*- coding: utf-8 -*-
my_string = «Я люблю %s» % «Python»
print(my_string) # Я люблю Python
var = «яблоки»
newString = «Я ем %s» % var
print(newString) # Я ем яблоки
another_string = «Я люблю %s и %s» % («Python», var)
print(another_string) # Я люблю Python и яблоки
|
1 |
# -*- coding: utf-8 -*- my_string=»Я люблю %s»%»Python» print(my_string)# Я люблю Python var=»яблоки» newString=»Я ем %s»%var print(newString)# Я ем яблоки another_string=»Я люблю %s и %s»%(«Python»,var) print(another_string)# Я люблю Python и яблоки |
Как вы могли догадаться, % — это очень важная часть вышеописанного кода. Этот символ указывает Python, что вы скоро вставите текст на его место. Если вы будете следовать за строкой со знаком процента и другой строкой или переменной, тогда Python попытается вставить ее в строку. Вы можете вставить несколько строк, добавив несколько знаков процента в свою строку. Это видно в последнем примере
Обратите внимание на то, что когда вы добавляете больше одной строки, вам нужно закрыть эти строки в круглые скобки. Теперь взглянем на то, что случится, если мы вставим недостаточное количество строк:
Python
another_string = «Я люблю %s и %s» % «Python»
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: not enough arguments for format string
|
1 |
another_string=»Я люблю %s и %s»%»Python» Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeErrornotenough arguments forformatstring |
О-па. Мы не передали необходимое количество аргументов для форматирования строки. Если вы внимательно взгляните на пример, вы увидите, что у нас есть два экземпляра %, но для того, чтобы вставить строки, вам нужно передать столько же %, сколько у нас строк. Теперь вы готовы к тому, чтобы узнать больше о вставке целых чисел, и чисел с запятыми. Давайте взглянем.
Python
my_string = «%i + %i = %i» % (1,2,3)
print(my_string) # ‘1 + 2 = 3’
float_string = «%f» % (1.23)
print(float_string) # ‘1.230000’
float_string2 = «%.2f» % (1.23)
print(float_string2) # ‘1.23’
float_string3 = «%.2f» % (1.237)
print(float_string3) # ‘1.24’
|
1 |
my_string=»%i + %i = %i»%(1,2,3) print(my_string)# ‘1 + 2 = 3’ float_string=»%f»%(1.23) print(float_string)# ‘1.230000’ float_string2=»%.2f»%(1.23) print(float_string2)# ‘1.23’ float_string3=»%.2f»%(1.237) print(float_string3)# ‘1.24’ |
Первый пример достаточно простой. Мы создали строку, которая принимает три аргумента, и мы передаем их. В случае, если вы еще не поняли, Python не делает никаких дополнений в первом примере. Во втором примере, мы передаем число с запятой
Обратите внимание на то, что результат включает множество дополнительных нулей (1.230000). Нам это не нужно, так что мы указываем Python ограничить выдачу до двух десятичных значений в третьем примере (“%.2f”)
Последний пример показывает, что Python округлит числа для вас, если вы передадите ему дробь, что лучше, чем два десятичных значения. Давайте взглянем на то, что произойдет, если мы передадим неправильные данные:
Python
int_float_err = «%i + %f» % («1», «2.00»)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: %d format: a number is required, not str
|
1 |
int_float_err=»%i + %f»%(«1″,»2.00») Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeError%dformatanumber isrequired,notstr |
В данном примере мы передали две строки вместо целого числа и дроби. Это привело к ошибке TypeError, что говорит нам о том, что Python ждал от нас чисел. Это указывает на отсутствие передачи целого числа, так что мы исправим это, по крайней мере, попытаемся:
Python
int_float_err = «%i + %f» % (1, «2.00»)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: float argument required, not str
|
1 |
int_float_err=»%i + %f»%(1,»2.00″) Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeErrorfloatargument required,notstr |
Мы получили ту же ошибку, но под другим предлогом, в котором написано, что мы должны передать дробь. Как мы видим, Python предоставляет нам полезную информацию о том, что же пошло не так и как это исправить. Если вы исправите вложения надлежащим образом, тогда вы сможете запустить этот пример. Давайте перейдем к новому методу форматирования строк.
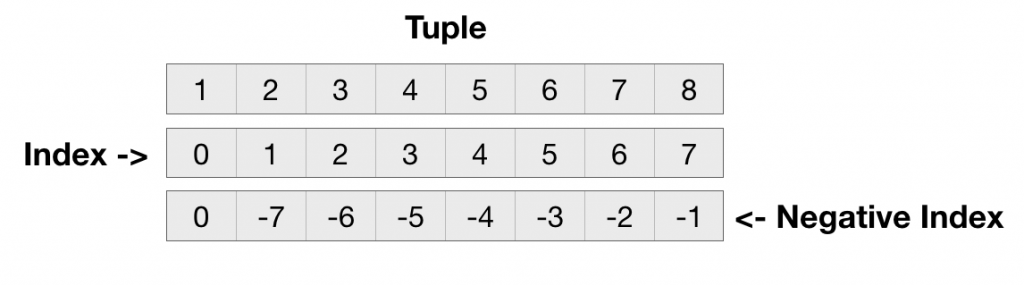
Нарезка строк
Одной из тем, которую вы часто будете делать на практике, является нарезка строк. Помню, меня удивило то, как часто мне нужно было узнать, как это делается в повседневной работе. Давайте посмотрим, как нарезка сработает в следующей строке:
Python
my_string = «I like Python!»
| 1 | my_string=»I like Python!» |
Каждый символ в строке может стать доступным при помощи слайсинга (нарезки). Например, если вам нужно взять только первый символ, вы можете сделать это следующим образом:
Python
print( my_string ) # I
| 1 | print(my_string1)# I |
Таким образом, мы берем первый символ в строке до второго символа, но, не включая его. Да, в Python отсчет ведется с нуля. Это проще понять, если мы определим позицию каждого символа в таблице:
Python
0 1 2 3 4 5 6 7 8 9 10 11 12 13 — I l i k e P y t h o n !
| 1 | 12345678910111213-IlikePython! |
Таким образом, у нас есть строка длиной в 14 символов, начиная с нуля и до тринадцати. Давайте приведем несколько примеров, чтобы понять это лучше.
Python
my_string # ‘I’
my_string # ‘I like Pytho’
my_string # ‘I like Python’
my_string # ‘I like Python!’
my_string # ‘I like Py’
my_string # ‘I like Python!’
my_string # ‘like Python!’
|
1 |
my_string1# ‘I’ my_string12# ‘I like Pytho’ my_string13# ‘I like Python’ my_string14# ‘I like Python!’ my_string-5# ‘I like Py’ my_string# ‘I like Python!’ my_string2# ‘like Python!’ |
Как видно в данных примерах, мы можем назначить срез, лишь указав его начало (другими словами, my_string), конец среза (my_string), или оба (my_string). Мы можем даже использовать отрицательные значения, которые начинаются с конца строки. Так что в примере, где мы указали my_string, начало ведется с нуля и заканчивается 5 символами, перед концом строки. Вы можете задаться вопросом «Зачем мне это и где это можно применить?». Лично я использовал это для разбора записей с фиксированной шириной в файлах, или ситуативно для парсинга сложных названий файлов, с очень специфическими наименованиями. Также я использовал это для парсинга значений в бинарных файлах. Любая работа, которая включает в себя обработку текстовых файлов, может быть намного проще, если вы понимаете, как работает нарезка и как эффективно использовать данный инструмент. Вы также можете получить доступ к отдельным символам в строке с помощью индексации. Например:
Python
print(my_string) # I
| 1 | print(my_string)# I |
Данный код выдаст первый символ в строке.
String Formatting Operator
One of Python’s coolest features is the string format operator %. This operator is unique to strings and makes up for the pack of having functions from C’s printf() family. Following is a simple example −
#!/usr/bin/python
print "My name is %s and weight is %d kg!" % ('Zara', 21)
When the above code is executed, it produces the following result −
My name is Zara and weight is 21 kg!
Here is the list of complete set of symbols which can be used along with % −
| Format Symbol | Conversion |
|---|---|
| %c | character |
| %s | string conversion via str() prior to formatting |
| %i | signed decimal integer |
| %d | signed decimal integer |
| %u | unsigned decimal integer |
| %o | octal integer |
| %x | hexadecimal integer (lowercase letters) |
| %X | hexadecimal integer (UPPERcase letters) |
| %e | exponential notation (with lowercase ‘e’) |
| %E | exponential notation (with UPPERcase ‘E’) |
| %f | floating point real number |
| %g | the shorter of %f and %e |
| %G | the shorter of %f and %E |
Other supported symbols and functionality are listed in the following table −
| Symbol | Functionality |
|---|---|
| * | argument specifies width or precision |
| — | left justification |
| + | display the sign |
| <sp> | leave a blank space before a positive number |
| # | add the octal leading zero ( ‘0’ ) or hexadecimal leading ‘0x’ or ‘0X’, depending on whether ‘x’ or ‘X’ were used. |
| pad from left with zeros (instead of spaces) | |
| % | ‘%%’ leaves you with a single literal ‘%’ |
| (var) | mapping variable (dictionary arguments) |
| m.n. | m is the minimum total width and n is the number of digits to display after the decimal point (if appl.) |
python-ideas discussion
Most of the discussions on python-ideas focused on three issues:
- How to denote f-strings,
- How to specify the location of expressions in f-strings, and
- Whether to allow full Python expressions.
Because the compiler must be involved in evaluating the expressions
contained in the interpolated strings, there must be some way to
denote to the compiler which strings should be evaluated. This PEP
chose a leading 'f' character preceding the string literal. This
is similar to how 'b' and 'r' prefixes change the meaning of
the string itself, at compile time. Other prefixes were suggested,
such as 'i'. No option seemed better than the other, so 'f'
was chosen.
Another option was to support special functions, known to the
compiler, such as Format(). This seems like too much magic for
Python: not only is there a chance for collision with existing
identifiers, the PEP author feels that it’s better to signify the
magic with a string prefix character.
This PEP supports the same syntax as str.format() for
distinguishing replacement text inside strings: expressions are
contained inside braces. There were other options suggested, such as
string.Template‘s $identifier or ${expression}.
While $identifier is no doubt more familiar to shell scripters and
users of some other languages, in Python str.format() is heavily
used. A quick search of Python’s standard library shows only a handful
of uses of string.Template, but hundreds of uses of
str.format().
Another proposed alternative was to have the substituted text between
\{ and } or between \{ and \}. While this syntax would
probably be desirable if all string literals were to support
interpolation, this PEP only supports strings that are already marked
with the leading 'f'. As such, the PEP is using unadorned braces
to denoted substituted text, in order to leverage end user familiarity
with str.format().
Разновидности жучков
Мало того, что жуки плодовиты и маскируют свои яйца, так у них еще и множество разновидностей. И пищевые предпочтения у насекомых разные, и условия обитания, и скорость размножения. Соответственно, и методы борьбы с ними тоже отличаются. Что же, истребить их совсем сложно? Разберемся по порядку, как называются и чем интересны разные виды жучков. Смотрите фото и ищите знакомцев.
Хлебный точильщик
Это рыжий жучок, который селится в булках, крупах и чае. Хороший летун, но квартиру по своей воле не покинет, так что борьба с ним обещает быть долгой.
Долгоносик
Черное насекомое с длинным хоботком, непритязательное к пище и среде обитания. Летает плохо, но перемещаться это ему не мешает. Долгоносик долгое время способен жить без еды, поэтому голодом морить его бесполезно.
Суринамский мукоед
Маленький рыжий жучок, который обитает в испорченных крупах и не прочь полакомиться сладостями. Очень плодовит, но не выносит испытания голодом и непривычными условиями.
Мучной жучок живет в овсянке, манке и муке
Наверняка знаком многим – это длинное (до 4 мм) темно-коричневое создание, портящее овсяную и манную крупы и муку. Его яйца тоже похожи на белые крупинки, а потому обнаружить их нелегко.
Почему Вам нужно обратиться именно к нам?
Произвольные выражения
Так как f-строки оцениваются по мере выражения, вы можете внести любую или все доступные выражения Python в них. Это позволит вам делать интересные вещи, например следующее:
Python
print(f»{2 * 37}»)
# Вывод: ’74’
|
1 |
print(f»{2 * 37}») # Вывод: ’74’ |
Также вы можете вызывать функции. Пример:
Python
def to_lowercase(input):
return input.lower()
name = «Eric Idle»
print(f»{to_lowercase(name)} is funny.»)
# Вывод: ‘eric idle is funny.’
|
1 |
defto_lowercase(input) returninput.lower() name=»Eric Idle» print(f»{to_lowercase(name)} is funny.») # Вывод: ‘eric idle is funny.’ |
Также вы можете вызывать метод напрямую:
Python
print(f»{name.lower()} is funny.»)
# Вывод: ‘eric idle is funny.’
|
1 |
print(f»{name.lower()} is funny.») # Вывод: ‘eric idle is funny.’ |
Вы даже можете использовать объекты, созданные из классов при помощи f-строки. Представим, что у вас есть следующий класс:
Python
class Comedian:
def __init__(self, first_name, last_name, age):
self.first_name = first_name
self.last_name = last_name
self.age = age
def __str__(self):
return f»{self.first_name} {self.last_name} is {self.age}.»
def __repr__(self):
return f»{self.first_name} {self.last_name} is {self.age}. Surprise!»
|
1 |
classComedian def__init__(self,first_name,last_name,age) self.first_name=first_name self.last_name=last_name self.age=age def__str__(self) returnf»{self.first_name} {self.last_name} is {self.age}.» def__repr__(self) returnf»{self.first_name} {self.last_name} is {self.age}. Surprise!» |
Вы могли бы сделать следующее:
Python
new_comedian = Comedian(«Eric», «Idle», «74»)
print(f»{new_comedian}»)
# Вывод: ‘Eric Idle is 74.’
|
1 |
new_comedian=Comedian(«Eric»,»Idle»,»74″) print(f»{new_comedian}») # Вывод: ‘Eric Idle is 74.’ |
Методы __str__() и __repr__() работают с тем, как объекты отображаются в качестве строк, так что вам нужно убедиться в том, что вы используете один из этих методов в вашем определении класса. Если вы хотите выбрать один, попробуйте __repr__(), так как его можно использовать вместо __str__().
Строка, которая возвращается __str__() является неформальным строковым представлением объекта и должна быть читаемой. Строка, которую вернул __str__() — это официальное выражение и должно быть однозначным. При вызове str() и repr(), предпочтительнее использовать __str__() и __repr__() напрямую.
По умолчанию, f-строки будут использовать __str__(), но вы должны убедиться в том, что они используют __repr__(), если вы включаете флаг преобразования !r:
Python
print(f»{new_comedian}»)
# Вывод: ‘Eric Idle is 74.’
print(f»{new_comedian!r}»)
# Вывод: ‘Eric Idle is 74. Surprise!’
|
1 |
print(f»{new_comedian}») # Вывод: ‘Eric Idle is 74.’ print(f»{new_comedian!r}») # Вывод: ‘Eric Idle is 74. Surprise!’ |
Если вы хотите прочитать часть обсуждения, в результате которого f-strings поддерживают полные выражения Python, вы можете сделать это здесь.
Конкатенация строк
Конкатенация строк означает соединение строк вместе от первого до последнего символа для создания новой строки. Для соединения строк используется оператор . При этом имейте в виду, что если мы работаем с числами, будет оператором , а если со строками оператором конкатенации.
Давайте соединим строки и вместе с помощью функции :
print("Sammy" + "Shark")
SammyShark
Следите за тем, чтобы никогда не использовать оператор «+» между двумя разными типами данных. Например, мы не можем объединять строки и числа вместе. И вот что произойдет, если мы вдруг попробуем это сделать:
print("Sammy" + 27)
TypeError: Can't convert 'int' object to str implicitly
Если бы мы захотели создать строку , мы могли бы это сделать поставив число в кавычки , таким образом . Преобразование числа в строку может быть полезным, когда мы, например, имеем дело с индексами или телефонными номерами. Например, когда нам нужно объединить телефонный код страны и телефонный номер, но при этом мы не хотим их складывать .
Когда мы соединяем одну или более строк вместе с помощью конкатенации, то создаем новую строку, которую сможем использовать в дальнейшем в нашей программе.
Как выбрать хороший навигатор для автомобиля?
Создание строк и вывод их на экран
Строки в Python записываются либо с помощью одинарных » либо с помощью двойных «» кавычек. Поэтому, для того, чтобы создать строку, давайте заключим последовательность символов в один из видов этих кавычек.
'Это строка заключена в одинарные кавычки'
"Это строка заключена в двойные кавычки"
Вы можете использовать либо одинарные либо двойные кавычки, но чтобы вы не выбрали, вам следует придерживаться этого на протяжении всей программы.
Мы можем выводить на экран наши строки просто используя функцию .
print("Давайте выведем на экран эту строку!")
Давайте выведем на экран эту строку!
Используя знания о форматировании строк в Python давайте теперь посмотрим, как мы можем обрабатывать и изменять строки в программах.