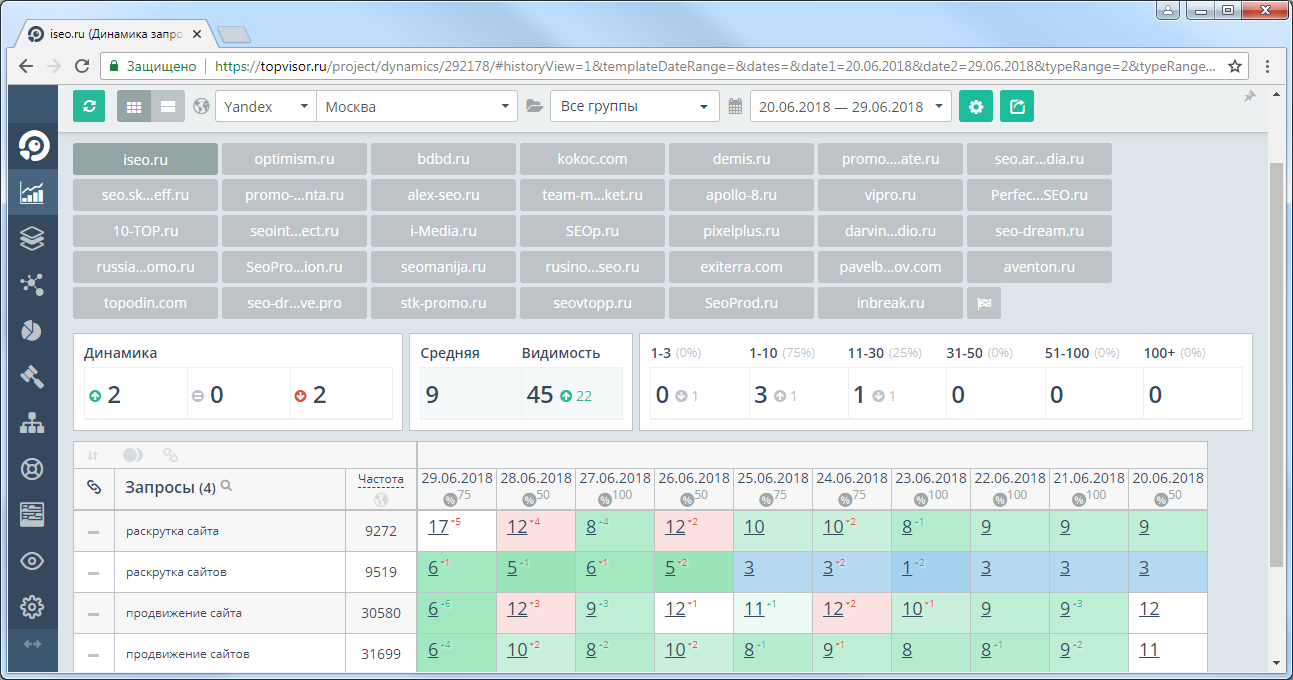
Cемантическое ядро сайта
Содержание:
- Особенности сбора семантики по видам проектов
- Как собирать ключи для СЯ
- Автоматический сбор семантического ядра онлайн
- Делаем анализ
- Шаг 3: анализируем поисковые подсказки магазинов приложений
- Шаг 4: анализируем запросы конкурентов
- Биржи фриланса
- Wordstat Яндекса и расширения для браузера
- Кластеризация семантического ядра
- Семантическое ядро для Landing Page
- Последний шаг
- Маркерные запросы
- Особенности ядра для Интернет-магазина
- Программы для сбора семантического ядра
- Этап 1. Сбор вариаций написания продукта и маркеров
- Шаг 1: добавляем запросы из головы
- 3 часто допускаемые ошибки в сборе семантического ядра
Особенности сбора семантики по видам проектов
В зависимости от размера сайта, количества оказываемых услуг или продаваемых товаров мы собираем семантику различного размера и затрачиваем на это разное количество времени.
Средний сайт с категориями/подкатегориями, но без товаров
Если категорий на сайте много, то для начала узнаем список наиболее интересных клиенту. Если предпочтений нет, выбираем на своё усмотрение. По ним собираем слова из Яндекс Вордстата и чаще всего сразу поисковые подсказки. Если запросов набирается мало, то расширяем список с помощью дополнительных сервисов.
Работаем с получившимся списком, оптимизируем страницы под подобранные для продвижения ключевые слова.
Затем поэтапно собираем запросы для следующих категорий и т.д.
Если в процессе сбора коммерческой семантики находятся информационные запросы и позволяет время, оставляем их в отдельном списке. Такие ключевые слова часто используются в будущем при написании статей для блогов на сайтах.
Процесс отличается от предыдущего вида проекта тем, что на основе собранной семантики мы смотрим, каких срезов не хватает на сайте, но их спрашивают люди.
Срез — это страница с товарами категории или подкатегории каталога отфильтрованными по определенному параметру. Например по цвету, бренду, размеру и т.д.
Вспомним пример, который был выше, про категорию красные платья. Найденные в списке запросов для этой категории «короткие красные платья» и подскажут нам, что следует создать соответствующий срез.
Нельзя забывать, что популярными могут быть не только категории продукции, но и конкретные модели товаров. Находя такие запросы в собранном списке, мы обязательно проверяем их наличие в каталоге сайте.
Примечание. При формировании итогового списка запросов обязательно учитываем геозависимость, коммерциализацию и максимальную достижимую позицию. Почитать об этих факторах можно в нашей статье.
Как собирать ключи для СЯ
Как пользоваться Яндекс Вордстат: операторы, расширения и секреты
Кратко о важном: какими операторами пользоваться в Вордстате, чтобы смотреть нужные запросы, и как облегчить себе работу в сервисе.
Вордстат не дает абсолютно точной информации, в нем нет всех запросов, в данные могут быть искажены, потому что Яндексом пользуются не все потребители.Тем не менее, из этих данных можно сделать выводы о популярности темы или товара, приблизительно спрогнозировать спрос, собрать ключи и найти идеи для нового контента.
Можно искать данные, просто вбивая запрос в поиск по сервису, но для конкретизации запросов есть операторы — добавочные символы с уточнениями. Они работают на вкладках поиска по словам и по регионам, на вкладке с историей запросов можно использовать только оператор «+запрос».
В статье:
- Зачем нужен Вордстат
- Работа с операторами Вордстата
- Как читать данные Wordstat
- Расширения для Яндекс Вордстата
Продвижение сайта по низкочастотным запросам
Компании и веб-мастера стараются продвинуться под популярные запросы, чтобы получить больше трафика. И многие новички совершают ошибку, когда пишут исключительно под ВЧ, попадая при этом в условия огромной конкуренции за 10 мест в поисковой выдаче с тысячами и десятками тысяч сайтов. Исследование на сайте Chitika.com показывает, что сайты за пределами топ-10 не приносят особого трафика.
В статье:
- LT-запросы
- Суть продвижения по низкочастотным запросам
- Преимущества продвижения по низкочастотным запросам
- Как найти и собрать НЧ-запросы
- Способ первый: изучение семантики
- Способ второй: сервисы для анализа ключевых слов
- Как оптимизировать сайт и отдельную страницу под низкочастотные запросы
Подборка инструментов для SEO и LSI-копирайтинга: как собрать и проверить ключи
Делимся подборкой инструментов для сбора LSI-фраз и ключей. Для тех, кто еще не разобрался, рассказываем, в чем все-таки различие между SEO и LSI-копирайтингом, что должно быть в оптимизированных текстах в 2018 году.
В копирайтинге обычно выделяют два вида оптимизированных текстов: по SEO и LSI. Многие не соглашаются с таким делением, потому что эти два способа очень похожи.
SEO больше сосредоточено на работе с поисковыми ботами, а LSI на выдаче пользователям самой полной и полезной информации, повышении качества контента, к чему и стремятся поисковики. Подбирать такие фразы вручную довольно долго. Мы попробовали несколько сервисов, которые предлагают подобрать SEO и LSI-ключевики, чтобы дело шло быстрее.
В статье:
- Что такое LSI-ключи
- SEO и LSI — в чем разница
- Как искать LSI-фразы
- Инструменты и сервисы для LSI-копирайтинга
4 тактики подбора ключевых слов, которыми не все пользуются
Перевели и адаптировали статью «Advanced Keyword Research: Four Tactics You’re (Probably) Not Using» с нестандартными способами сбора ключей, основанными на практическом опыте.
Около года назад автору статьи пришли несколько идей, как еще можно собирать ключевые слова для продвижения. Он протестировал способы с бесплатными инструментами и получил интересные результаты. Тогда он расширил масштабы тестирования и по итогу вывел четыре способа, которые помогут собрать дополнительные ключи и продвинуть свои статьи в топ.
В статье:
- Подбор ключевиков по молодым сайтам из топа
- Сбор ключей с помощью пользовательского поиска Google (Google Custom Search Engine)
- Тактика моделирования запросов, по которым другие сайты попали в топ за несколько недель
- Реверс-инжиниринг «слабых» сайтов не из топа
Анализируем топ выдачи, чтобы пробиться в лидеры
Стремимся в лидеры выдачи: как анализ статей из топа поможет в работе над контентом, по каким критериям проводить анализ и как сделать это быстрее и эффективнее.
Сложно отслеживать результаты ведения блога и публикации других текстов на сайте без детальной аналитики. Как понять, почему статьи конкурентов в топе, а ваши нет, хотя вы пишете лучше и талантливее?
В статье:
- Что обычно советуют
- Как проводить анализ
- Минусы подхода
- Преимущества анализа контента
- Инструменты
Автоматический сбор семантического ядра онлайн
А теперь поговорим о самых востребованных сервисах по сбору семантического ядра.
Wordstat
Эту программу https://wordstat.yandex.ru/ можно считать первоисточником, поскольку другие инструменты так или иначе взаимодействуют с данными поисковой системы. В первую очередь выберите несколько запросов, максимально точно отражающих суть вашего бизнеса. Допустим, вы продаете цифровые фотоаппараты. Представьте, что лично ищете любой аналогичный магазин в Интернете. В качестве примера приведем запрос «купить фотоаппарат».
Слева в колонке – фразы, которые аудитория искала вместе с фразой «купить фотоаппарат». Не забывайте, что из перечня полученных фраз надо отсеять все лишние запросы. Вы ведь не продаете фотоаппараты на Avito?
Если вы не уверены, к какой категории относится запрос (коммерческий он или нет), просто впишите его в строку поиска и проанализируйте результаты выдачи. Если в ней больше блогов и журналов, то запрос, по всей вероятности, информационный. Например, в ключи может попасть фраза «какой фотоаппарат купить в 2019 году».
По запросу «какой цифровой фотоаппарат купить в 2019 году» поисковая система выдает только инфосайты.
Давайте подробнее поговорим о Wordstat как о программе для сбора семантического ядра. В колонке справа указаны фразы, схожие с начальным запросом. Но лишнего здесь, конечно, больше. Ваша задача – пользоваться только теми фразами, которые реально отражают специфику бизнеса, и, безусловно, исключать инфозапросы типа «качественный фотоаппарат». Правой колонкой можете пользоваться, чтобы искать синонимы. К примеру, мало кто может с первого раза правильно написать название японской марки fujifilm. Встречаются запросы «фиджифильм», «фудзифилм» и т. п. Все эти вариации также нужно включить в состав семантического ядра.
Анализируя запросы, вы обязательно увидите, что пользователи ищут фототехнику по ряду определенных критериев:
- стоимость (купить недорого);
- марка (купить фотоаппарат самсунг, кэнон, сони);
- модель (купить фотоаппарат canon powershot);
- характеристики (купить цифровой фотоаппарат, купить зеркальный фотоаппарат);
- регион (купить фотоаппарат в казани, купить фотоаппарат в краснодаре).
Эти данные позволяют вам сформировать так называемые маски запросов, в частности:
- фотоаппарат + действие (купить, заказать, с доставкой по РФ);
- фотоаппарат + стоимость (недорого, дешево, по акции, до 10 тыс., до 50 тыс.);
- фотоаппарат + марка;
- фотоаппарат + марка + модель;
- фотоаппарат + характеристика (64 гб, с nfc, 12 дюймов, с двумя симками);
- фотоаппарат + еще какой-то запрос (легкий, в качестве подарка).
Определив маски запросов, вы:
- Грамотно распределите посадочные страницы на сайте по категориям и характеристикам товаров.
- Разработаете страницы под популярные поисковые запросы (например, недорогой фотоаппарат).
- Растиражируете выбранные маски запросов на все остальные группы товаров.
- Сделаете шаблон для сбора семантического ядра.
На этой ступени мы не советуем сильно акцентировать внимание на частотности запроса. В список можете включать любые непустые фразы (с частотой от 1), связанные с вашим бизнес-проектом
При помощи каких фраз вы продвигаете и рекламируете свой товар, дело второе. На данном этапе главная задача – сбор полноценного семантического ядра.
RushAnalytics
Программа Rush Analytics помогает сделать сбор запросов из левой колонки Wordstat более автоматизированным с последующей загрузкой данных в таблицу Excel.
В нашем примере нужно лишь запустить сбор ключей по запросам «фотоаппарат». Но есть одна важная деталь. Wordstat по умолчанию отдает всего 41 страницу с результатами. Как вы понимаете, все запросы по такой схеме получить не удастся. Для обхода ограничения необходимо воспользоваться методом сбора частотности для запросов заданной длины (до 7 слов).
Для этого следует добавить запросы в Wordstat таким образом (обязательно нужны кавычки):
- «фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат, фотоаппарат»;
- и так далее – до 7 слов.
Этот метод поможет в сборе максимального количества запросов по вашей теме.
Spywords.ru
Программа spywords.ru дает возможность несколько облегчить себе задачу и собрать семантическое ядро не с нуля, а с помощью сайтов-конкурентов.
Принцип работы предельно прост: нужно выбрать 3–4 лидера в вашей отрасли и собрать все фразы, по которым их ранжируют поисковики в пределах Топ-100.
Конечно, так вы, скорее всего, не соберете полноценную семантику. Но с большой долей вероятности охватите процентов 60, и для начала этого достаточно.
Делаем анализ
Иногда приходится работать уже с существующим семантическим ядром. Проводить его анализ и оценивать качество. Если ядро составлялось Вами, то особой сложности нету. Его нужно лишь актуализировать. Но если работа была проведена сторонними специалистами, то необходимо провести полноценный анализ, что бы быть уверенными в качестве и полноте.
Мы расскажем, как и по каким критериям оценить уже существующее семантическое ядро.
Даже если изначально ядро было добросовестно составлено, то оно может устареть. В чем это проявляется?
- Часть ключевых слов может устареть и не иметь показов вообще. К примеру, если в запросе есть год, дата или прошедшее событие;
- В ядре может не оказаться огромного количества новых, недавно появившихся запросов;
- Частота показов ключевых слов зависит не только от сезона, но и от длительного промежутка времени. Что-то входит в моду, что то выходит. Меняются приоритеты, добавляются и удаляются подсказки поиска, происходят другие события, которые влияют на частотность. Старые ключевики могут сильно потерять в спросе.
- Помимо запросов меняется и бизнес. Некоторые слова могут быть не актуальны с коммерческой точки зрения.
То есть, как мы видим, необходимо проверять любое, даже самое качественное ядро.
Критерии, по которым делается анализ семантического ядра:
- Изменение частотности. Насколько изменилась частота показов за прошедшее время;
- Устаревание слов. Часть слов со временем может потерять актуальность как с точки зрения спроса, так и с коммерческой точки зрения;
- Отсутствие новых слов. Каждый день появляются новые запросы. Проверьте, что изменилось в Вашей области и актуализируйте ядро;
- Полнота ядра. Изначально ядро могло быть составлено неравномерно, с упором на какие-то конкретные области. Заполните эти «пробелы»;
- Ядро должно быть для SEO. Убедитесь, что существующее ядро составлялось для продвижения сайта, а не для контекстной рекламы. Ядро для контекста зачастую сильно отличается. Основное отличие — наличие слишком низкочастотных запросов. Отсутствие информационных ключей;
- Сопоставьте ядро и сайт. Правильное семантическое ядро должно полностью соответствовать структуре сайта. (это справедливо и в обратную сторону);
При полноценной работе с сайтом, необходимо каждые пол года проверять актуальность ядра. Устаревшая семантика привлечет за собой много потраченных в пустую сил.
Шаг 3: анализируем поисковые подсказки магазинов приложений
Пользователи часто не вводят запрос целиком, а кликают на поисковую подсказку, которую предлагает магазин приложений.
Наша задача — попробовать восстановить весь путь поиска приложения.
Этот метод очень пригодится на 2-4 итерации, когда вы уже используете основную часть запросов, но продолжаете искать точки роста.
С помощью подсказок магазинов приложений вы можете увидеть картину глазами пользователей и сузить ядро.
Например, вы поработали на охват и используете широкие запросы («изучение английского», «учить английский»). Тогда стоит найти более узкие поисковые запросы, которые подойдут под специфику приложения: «учить английские слова», «английская грамматика», «английский для туристов».
Чтобы проверить поисковые подсказки, напишите слово «английский» и посмотрите, что выдаёт магазин приложений. Часть запросов будет относиться к изучению английского, будут запросы по поиску переводчиков и словарей.
Можно подходить более детально и вбивать слова посимвольно в App Store или Google Play.
ASOdesk также поможет найти поисковые подсказки по вашим запросам. Они отображаются в Keyword Table, графа Suggestions.
Keyword Table в Keyword Analytics Keyword Suggestions по словосочетанию «английский язык»
Проверить подсказки также можно с помощью инструмента Keyword Explorer.
Поисковая выдача по запросу «учить английский» в Keyword Explorer
Шаг 4: анализируем запросы конкурентов
Топовые конкуренты дают инсайты по ключевым словам и метаданным. Вы можете посмотреть прогноз установок, которые получают конкуренты по различным ключевым словам. А также оценить, какие слова и фразы пропускает модерация.
Для анализа нужно найти конкурентов по поисковым запросам из вашей ниши. Это можно сделать через Keyword Explorer в ASOdesk.
Поисковая выдача App Store по запросу «английский язык»
На этом этапе мы также проверяем релевантность ваших поисковых запросов. Если вбивая запрос в поиск, вы видите похожие приложения конкурентов, то такое ключевое слово можно добавлять в семантическое ядро. Если же по запросу ранжируются совсем другие приложения, то не стоит использовать этот запрос.
Например, по запросу «словарный запас» очень мало приложений, связанных с английским языком. Соответственно, нам нужно убрать это ключевое слово из семантического ядра.
Поисковая выдача App Store по запросу «словарный запас»
В ASOdesk вы можете найти и одновременно проанализировать до 9 конкурентов с помощью нескольких инструментов.
Organic Report
Показывает прогноз установок с поисковых запросов, по которым ранжируется приложение конкурента (Estimate Installs).
Мы проанализировали приложение конкурента и нашли поисковые запросы. Теперь добавим наиболее релевантные в семантическое ядро.
Organic Report Lingualeo
Missing Ranked Keyword
Инструмент на основе приложений конкурентов показывает запросы, которых нет в нашем ядре. По этим запросам похожие приложения находятся в топ-1, топ 2-5 и т.д.
В процессе анализа мы добавили 73 запроса для приложения Simple.
Missing Competitors Keywords в Keyword Analytics
Competitors Best Keywords
Найдёт самые популярные запросы, которые дают установки вашим конкурентам. Данные запросы вы можете добавлять в семантическое ядро.
Competitors Best Keywords в Keywords Auto-Suggestions
Least Competitive Keywords
Если приложение пока не популярно, выйти в топ по высокочастотным запросам будет невозможно. Поэтому нужно ранжироваться по запросам с низкой конкуренцией.
В результате анализа мы нашли ещё 16 ключевых слов для приложения Simple.
Least Competitors Keywords в Keyword Auto-Suggestions
ASO Comparative Report
Этот инструмент позволяет смотреть ключевые слова, по которым у конкурентов растут или падают поисковые позиции, а также недавно добавленные ключи.
Ключевые слова можно отфильтровать с помощью movement.
ASO Comparative Report конкурента приложения Simple
Биржи фриланса
Самым первым и одновременно самым дешевым способом заказа услуги по составлению семантики принято считать биржи фриланса. Огромное количество специалистов занимаются сбором семантики для клиентов. Причем они не берут за это много.
Стоимость услуг фрилансера может составлять от 500 рублей до 3 – 4 тысяч. Бывает и больше, но здесь уже речь идет о профессионалах, которые привыкли работать с большими компаниями или популярными проектами. Если речь идет о личном блоге, то вы вполне можете обратиться к специалисту, который сделает это дешевле.
Найти хорошего сео-специалиста можно на популярных биржах удаленной работы. Достаточно просто выложить заказ с соответствующим ТЗ и уже через несколько минут к вам начнут поступать предложения о работе.

Например, в магазине фриланс-услуг Kwork вы сможете купить один кворк любого специалиста за 500 рублей. Каждый из них предлагает свой набор опций. Топовые фрилансеры могут повышать цены. Если вы не располагаете средствами, то я советую вам поискать кворки от новичков. Как правило, они за ту же цену предлагают больший объем услуг.
Wordstat Яндекса и расширения для браузера
Wordstat — это бесплатный сервис поисковой статистики и подбора слов от Яндекса. Именно здесь можно посмотреть статистику запросов по любой поисковой фразе в зависимости от региона поиска.
Чтобы собрать семантическое ядро, используя исключительно Wordstat Яндекса, нужно копировать каждую страницу с результатами, переносить ее в Excel, а затем отсеивать нерелевантные запросы и только после этого добавлять в рекламные кампании.
Сократить процесс в несколько раз поможет расширение для браузера WordStater. После его установки Wordstat выглядит так:
Расширение позволяет одновременно собирать поисковые фразы, их частотность и минус-слова. При добавлении они будут подсвечены красным на всех страницах.
Далеко не всегда суть поискового запроса можно понять сразу же, иногда приходится копировать и искать его в новой вкладке. Разработчики расширения продумали этот момент — создали переход по нужному ключевому слову прямо из интерфейса при помощи одного клика. Это удобно и значительно экономит время.
Другие расширения с подобными возможностями:
- Yandex Wordstat Helper
- Yandex Wordstat Assistant
- Yandex Wordstat Keywords Add
Кластеризация семантического ядра
Кластеризация (кластерный анализ) — процесс обработки запрос и распределение их на одинаковые лексические группы, называемые кластерами. В кластер попадают запросы, которые могут продвигаться на 1 странице, совместимы между собой и похожи по смыслу.
Виды кластеризации запросов
HARD кластеризация
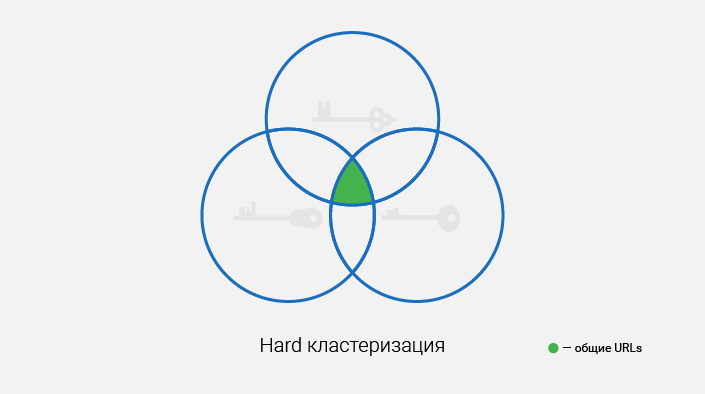
При данном методе в группу попадают запросы, которые на 100% совместимы между собой, группа формируется, когда URL из ТОП-10 пересекаются во всех запросах, и их количество достигает или превышает определенного порога.
В результате мы получаем большое количество групп небольшого размера за счет высокой точности группировки, метод походит для дальнейшего текстового анализа, т.к. мы будем точно уверены, что в группе нет лишних запросов.
Подходит для большинства коммерческих сайтов и тематик.
SOFT кластеризация
В группу попадают запросы, которые пересекаются URL в ТОП-10 c главным ключом и если их число совпадений достигло нужного нам порога или превысило его.
На выходе получаем меньшее количество групп большого размера за счет слабой точности пересечения запросов, идеально подходит для информационных порталов или форумов, для контекстной рекламы. В группу могут попадать слабо совместимые ключи, в следствии чего использовать такие группы для текстового анализа не рекомендуется.
Программы для кластеризации
Кроме онлайн инструментов есть еще и десктопные версии программ по кластеризации ядра (все программы работают только в Windows):
- Key Collector — 1800 рублей.
- KeyAssort — 1990 рублей. (невозможно работать на Retina дисплеях)
- Majento — , для работы необходимы XML лимиты.
Пример кластеризации семантического ядра в программе Magento:

Сервисы для кластеризации
Для автоматической кластеризации семантического ядра используют платные онлайн сервисы:
- Rush Analytics — является лучшим сервисом для кластеризации ядер, собирает данные с реальной выдачи, без использования XML. Сервис платный, но при регистрации выдается 200 лимитов, которых хватит на группировку 400 запросов в семантике.
- Just-Magic.org — также платный сервис, используется в кластеризации очень сложных тематик, когда необходимо видеть силу связи между ключевыми запросами в кластерах. При регистрации вы получаете лимит на 100 запросов.
- http://coolakov.ru/tools/razbivka/ — бесплатный сервис кластеризации ядра до 1000 запросов.
Пример кластеризации семантики от Coolakov:
Семантическое ядро для Landing Page
Так как продвижение лэндинг пейдж имеет свои особенности, то и ядро будет сильно отличаться от стандартного. Ранее мы уже писали о том, что лэндинг должен быть ориентирован только на один основной запрос и иметь небольшое дерево подзапросов. Семантическое ядро должно быть точно таким же.
То есть, перед составлением ядра для landing page, определите один основной запрос, который полностью характеризует Вашу деятельность
Обратите внимание, что это должен быть не высокочастотник, который охватывает все, а подходящий достаточно конкретный ключевик. К примеру, для лэндинга по продаже мебельных щитов по МСК, запрос «щит» и «мебельный щит» не подойдут
После того, как Вы определились с основной ключевой фразой — найдите для нее максимально похожие подзапросы. Это и будет семантическое ядро для Вашей посадочной страницы. Небольшое, но полностью характеризующее деятельность.
Так как все запросы будут очень похожи друг на друга — не переборщите с оптимизацией. Применяйте синонимы, заменяйте на местоимения и т.д.
Последний шаг
Маркерные запросы
Маркерные запросы — это запросы, которые наиболее точно описывают суть страницы. Такие запросы часто имею самую высокую частотность по Wordstat, от них происходит «хвост» запросов, например, такие как «купить», «отзывы» и т.д. Очень частно маркерным запросом выступает заголовок h1 на странице.
Производим мозговой штурм и собираем маркерные запросы по всем основным направлениям на нашем сайте. Например, мы продаем заточные, фрезерные и токарные станки, это разделы, сначала пишем их, после вписываем категории, которые входят в каждый из разделов, далее указываем подкатегории входящие в категории.
Особенности ядра для Интернет-магазина
Примечание: Уникальные запросы — это фразы, которые вбивали в строку поиска всего 1 раз. Статистики по ним нету, так как в предыдущие и последующие месяцы их частотность равна нулю. Обычно, это длинные и конкретные запросы.
Что делать в таком случае? Многие рекомендуют собирать огромное семантическое ядро с десятками тысяч низкочастотников. Сложность заключается в том, что работать с такой семантикой крайне сложно. Мы предлагаем немного иной подход.
В ядре необходимо отразить дерево всех основных ключевых запросов с частотностью до 5-10 показов. А вместо очень низкочастотных запросов просто выписать слова, которые необходимо упомянуть в тексте и тэгах. Огромное количество низкочастотников формируется из достаточно небольшого количества слов.
Таким образом, Вы сможете упомянуть в описании товара большинство слов, которые формируют низкочастотные запросы. При этом, ядро будет наглядным и структурированным. Выглядеть это может таким образом:
Программы для сбора семантического ядра
Словоеб — это бесплатный аналог KeyCollector, но с множеством урезанных функций, позволяет собирать ключи через Wordstat, определять частотность и собирать поисковые подсказки. Отключена выгрузка результатов.
KeyCollector — мощный многофункциональный инструмент для работы с семантическим ядром, является обязательной программой для всех специалистов по SEO и контекстной рекламе. Стоит всего 1800 рублей.
Настройки KeyCollector
Настройка парсинга Yandex.Direct
В самом верху настроек, вам необходимо будет ввести логин и пароль от аккаунта в Яндекс. Желательно сделать для этого новый аккаунт, не используйте свой рабочий аккаунт.
Настройка парсинга Поисковой выдачи
Крайне желательно использовать XML, если он у вас есть. Это сильно сократить время сбора данных.
Создаете новый проект в программе и перед началом парсинга выбираете необходимый вам регион, например, Москва и область, сохраняете изменения.
Этап 1. Сбор вариаций написания продукта и маркеров
Перед сбором запросов необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекса.
Методика
Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».
Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.
Переносим все найденные варианты названия продукта в отдельный файл.
На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.
Для выявления маркеров есть два пути:
1.Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
1.1. Плюс: Сбор всех существующих в спросе маркеров;
1.2. Минус: Долгий и трудозатратный процесс.
2. Поиск и анализ страниц конкурентов в ТОП 10, которые уже имеют страницы с нашим продуктом.
2.1. Плюс: Быстрый процесс;
2.2. Минус: Неполный сбор свойств, если они отсутствуют у конкурентов.
Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП 10
Это возможно сделать вводом основного запроса прямо в поисковую систему или же воспользоваться инструментом полноценного поиска конкурентов по видимости их сайтов, как было рассказано в 4 пункте первого этапа данной статьи.
На странице конкурента, нужно обратить внимание на структуру категории, то есть существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры
Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:
Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в Microsoft Excel. В результате получим таблицу, аналогичную представленной ниже:
Для пакетной (разовой) загрузки всех ключевых слов в KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:
Шаг 1: добавляем запросы из головы
Разработчик и мобильный маркетолог отлично знают своё приложение и проблемы, которые оно решает. ASO-специалист перед началом продвижения также разбирается в продукте и понимает, зачем и кому он нужен. Поисковые запросы следуют из задач пользователей и функций вашего приложения. Поэтому на первом этапе выпишите все запросы, по которым, как вам кажется, пользователи ищут похожие приложения.
Зайдите в ASOdesk Keyword Analytics и введите запросы в поле Add Keywords.
Если у вас брендовое приложение, начните с брендовых ключевых слов. А затем вставьте все общие запросы. На первом этапе у нас получилось 51 ключевое слово.
Add keywords в Keyword Analytics
3 часто допускаемые ошибки в сборе семантического ядра
Зачастую неопытные пользователи не до конца понимают, как производить сбор семантического ядра, и допускают ошибки. Эти ошибки, конечно, не фатальные, но способны вызвать негативные последствия.
- Контент страницы и запрос не соответствуют друг другу. Пример: вы включили в семантическое ядро запрос («фитнес браслет отзывы»). Но фактически отзывы у вас на странице отсутствуют. Соответственно, человек не найдет необходимые ему сведения. Не нужно намеренно писать об отзывах в тексте. Человек зайдет на сайт и поймет, что его обманули. В результате у него сформируется негативное отношение к вашему ресурсу и компании в целом. Надо сказать, что в рекламных целях такой запрос можно применять к странице, хотя это и нежелательно.
- В семантическое ядро включены запросы с нулевой частотностью. То есть такие запросы «пустые» и пользователи их не ищут. Такого рода запросы не приносят вам трафика. Частотность – первый показатель, который нужно проверять после сбора семантического ядра.
- Ключевые запросы подобраны без ориентира на пользователя. В первую очередь следует понять, что в поисковиках ищет ЦА и что полезного вы вместе со своим сайтом можете ей предложить.
Помните, каждый день рынок пополняется новыми продуктами, интересы и пожелания аудитории меняются, а потому важно оставаться в тренде и своевременно адаптироваться к новым веяниям. Конечно, в повседневной суете не всегда есть время на аналитику
Но разовый сбор семантического ядра без последующей работы в данном направлении – абсолютно бесперспективная идея.