Два способа, как поменять кодировку в word
Содержание:
- Как зайти на 192.168.1.1?!
- FontDetect
- Что это такое
- Кодирование Торпедо
- Что делать, если вместо текста иероглифы (в Word, браузере или текстовом документе)
- Особенности с которыми я столкнулся
- Пропал весь пакет каналов на цифровой приставке
- Два способа, как поменять кодировку в Word
- Кодировки стандарта ASCII[править]
- Прием
- Читайте также
- Собственный велосипед
- В Windows 10 пропал курсор мыши, он дёргается или притормаживает: что делать?
Как зайти на 192.168.1.1?!
FontDetect
Что это такое

В наркологии кодировка от алкоголизма — это метод лечения зависимости через внушение с опорой на физиологию. Работа ведётся в первую очередь с подсознанием пациента. Так что практически все техники и приёмы заимствованы из психотерапии.
Однако в последнее время широкое распространение получили программы, заявляющие о том, что не воздействуют на психику и влияют исключительно на мозговые структуры. Но это не совсем так. Те нейронные связи, которые они затрагивают, отвечают за функционирование ЦНС, когнитивные способности, чувства и эмоции. А это уже область познания психотерапии.
Первая проблема кодирования
Официальная медицина заявляет, что все обоснования, которыми оперируют специалисты, занимающиеся лечением алкоголизма, являются псевдонаучными и никакими серьёзными исследованиями не подтверждены. Тем не менее многие наркологи признают, что психотерапевтические установки в ряде случаев срабатывают и люди избавляются от пагубной зависимости.
Вторая проблема
Как правило, человека кодируют близкие, так как жить с ним становится невыносимо. Однако сам он чаще всего не осознаёт своего заболевания, не видит необходимости в лечении и не хочет этого. А все методики рассчитаны на добровольное желание избавиться от зависимости. Это является основной причиной неэффективности применяемых техник.
Термин был введён А. Р. Довженко. Именно он стал практиковать кодирование впервые. О его методе будет написано более подробно чуть ниже.
Кодирование Торпедо
Данный метод кодирования алкоголизма основывается на введении больному под кожу специальной ампулы. В этой ампуле находится лекарственный препарат, который при приеме спиртного оказывает токсическое действие, вызывая временное прекращение работы печени и мощное отравление организма. Из-за страха потерять здоровье человек, страдающий от алкоголизма, прекращает пить уже на следующий день после проведения процедуры. На данный момент это один из самых быстродействующих методов кодирования, позволяющий за короткое время вернуть пациента к здоровой и полноценной жизни.
Данный способ имеет следующие преимущества:
-
процедура введения ампулы не занимает много времени;
-
небольшой шрам от вшивания капсулы незаметен окружающим людям.
К недостаткам можно отнести:
-
длительность кодировки ограничена по сроку действия лекарственного препарата;
-
кодирование может вызывать психологические проблемы, вызванные отказом от спиртного.
Что делать, если вместо текста иероглифы (в Word, браузере или текстовом документе)
Наверное, каждый пользователь ПК сталкивался с подобной проблемой: открываешь интернет-страничку или документ Microsoft Word — а вместо текста видишь иероглифы (различные «крякозабры», незнакомые буквы, цифры и т.д. (как на картинке слева…)).
Хорошо, если вам этот документ (с иероглифами) не особо важен, а если нужно обязательно его прочитать?! Довольно часто подобные вопросы и просьбы помочь с открытием подобных текстов задают и мне. В этой небольшой статье я хочу рассмотреть самые популярные причины появления иероглифов (разумеется, и устранить их).
Иероглифы в текстовых файлах (.txt)
Самая популярная проблема. Дело в том, что текстовый файл (обычно в формате txt, но так же ими являются форматы: php, css, info и т.д.) может быть сохранен в различных кодировках .
Чаще всего происходит одна вещь: документ открывается просто не в той кодировке из-за чего происходит путаница, и вместо кода одних символов, будут вызваны другие. На экране появляются различные непонятные символы (см. рис. 1)…
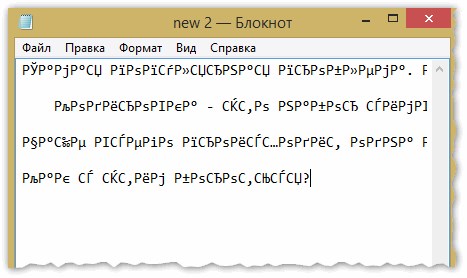
Рис. 1. Блокнот — проблема с кодировкой
Как с этим бороться?
На мой взгляд лучший вариант — это установить продвинутый блокнот, например Notepad++ или Bred 3. Рассмотрим более подробно каждую из них.
Notepad++
Один из лучших блокнотов как для начинающих пользователей, так и для профессионалов. Плюсы: бесплатная программа, поддерживает русский язык, работает очень быстро, подсветка кода, открытие всех распространенных форматов файлов, огромное количество опций позволяют подстроить ее под себя.
В плане кодировок здесь вообще полный порядок: есть отдельный раздел «Кодировки» (см. рис. 2). Просто попробуйте сменить ANSI на UTF-8 (например).
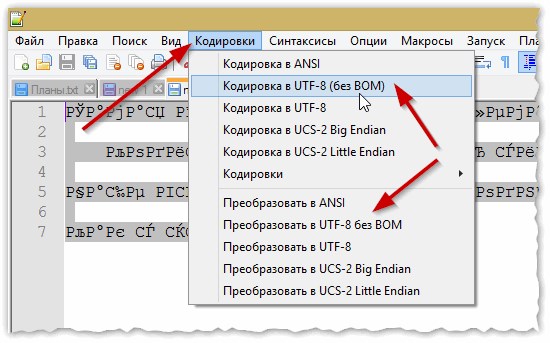
Рис. 2. Смена кодировки в Notepad++
После смены кодировки мой текстовый документ стал нормальным и читаемым — иероглифы пропали (см. рис. 3)!
Рис. 3. Текст стал читаемый… Notepad++
Bred 3
Еще одна замечательная программа, призванная полностью заменить стандартный блокнот в Windows. Она так же «легко» работает со множеством кодировок, легко их меняет, поддерживает огромное число форматов файлов, поддерживает новые ОС Windows (8, 10).
Кстати, Bred 3 очень помогает при работе со «старыми» файлами, сохраненных в MS DOS форматах. Когда другие программы показывают только иероглифы — Bred 3 легко их открывает и позволяет спокойно работать с ними (см. рис. 4).
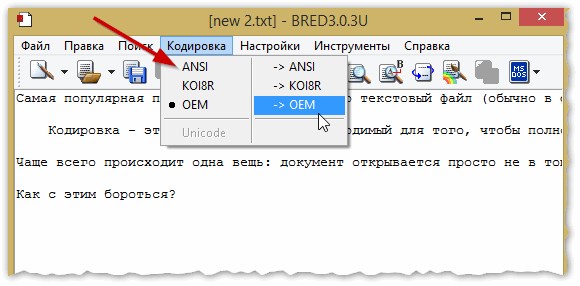
Если вместо текста иероглифы в Microsoft Word
Самое первое, на что нужно обратить внимание — это на формат файла. Дело в том, что начиная с Word 2007 появился новый формат — « docx » (раньше был просто « doc «)
Обычно, в «старом» Word нельзя открыть новые форматы файлов, но случается иногда так, что эти «новые» файлы открываются в старой программе.
Просто откройте свойства файла, а затем посмотрите вкладку « Подробно » (как на рис. 5). Так вы узнаете формат файла (на рис. 5 — формат файла «txt»).
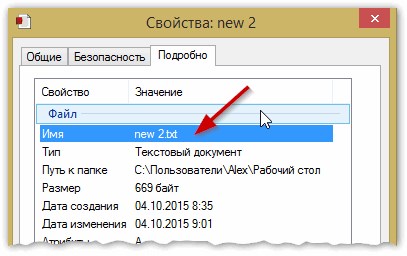
Рис. 5. Свойства файла
Далее при открытии файла обратите внимание (по умолчанию данная опция всегда включена, если у вас, конечно, не «не пойми какая сборка») — Word вас переспросит: в какой кодировке открыть файл (это сообщение появляется при любом «намеке» на проблемы при открытии файла, см. рис
5).
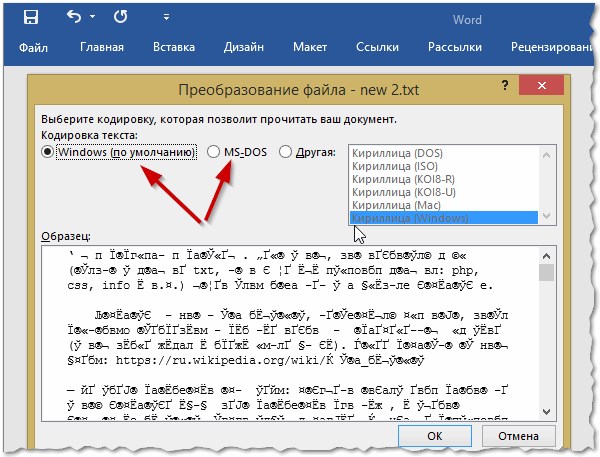
Рис. 6. Word — преобразование файла
Чаще всего Word определяет сам автоматически нужную кодировку, но не всегда текст получается читаемым. Вам нужно установить ползунок на нужную кодировку, когда текст станет читаемым. Иногда, приходится буквально угадывать, в как был сохранен файл, чтобы его прочитать.
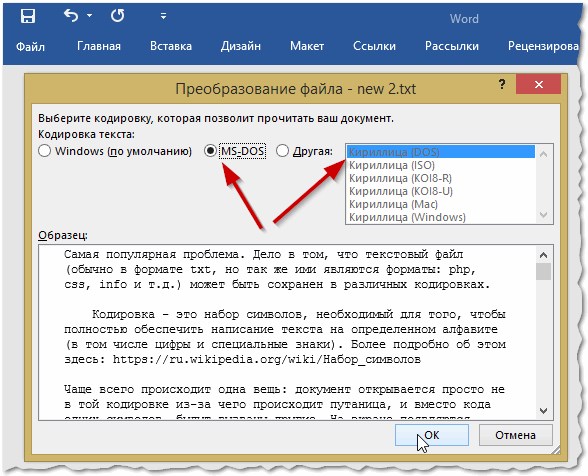
Рис. 7. Word — файл в норме (кодировка выбрана верно)!
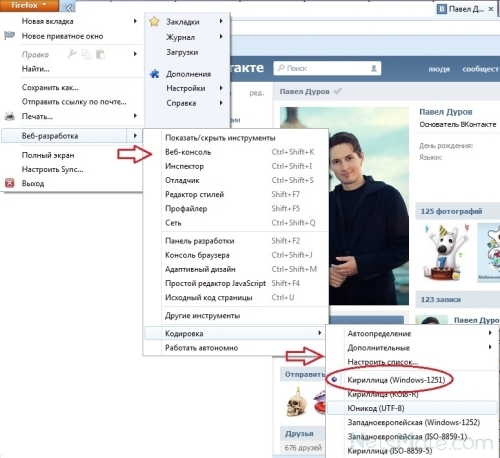
Смена кодировки в браузере
Когда браузер ошибочно определяет кодировку интернет-странички — вы увидите точно такие же иероглифы (см. рис 8).

Рис. 8. браузер определил неверно кодировку
Чтобы исправить отображение сайта: измените кодировку. Делается это в настройках браузера:
- Google chrome: параметры (значок в правом верхнем углу)/дополнительные параметры/кодировка/Windows-1251 (или UTF-8);
- Firefox: левая кнопка ALT (если у вас выключена верхняя панелька), затем вид/кодировка страницы/выбрать нужную (чаще всего Windows-1251 или UTF-8) ;
- Opera: Opera (красный значок в верхнем левом углу)/страница/кодировка/выбрать нужное.
PS
Таким образом в этой статье были разобраны самые частые случаи появления иероглифов, связанных с неправильно определенной кодировкой. При помощи выше приведенных способов — можно решить все основные проблемы с неверной кодировкой.
Буду благодарен за дополнения по теме. Good Luck
Особенности с которыми я столкнулся
Чуть коснусь прелестей и проблем связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Что делать если интерфейс является входным параметром нашей функции? Например если мы принимаем io.Reader, проверить его на nil ведь надо. Проверить на существование переменной типа io.Reader мне удалось только с помощью рефлексии.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы хранящиеся в map пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно быстро давало результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Пропал весь пакет каналов на цифровой приставке
Сложней обстоит ситуация, когда в определенный момент пропал полный набор ТВ-каналов. На телевизоре могут отображаться разные сообщения, к примеру, Нет сигнала. Возникает вопрос, как вернуть каналы на приставке, и в чем могут быть причины такой ситуации. Сделайте следующие шаги:
- Выполните ручную или автоматическую настройку. Для начала еще раз запустите поиск и попробуйте восстановить список с помощью ручного или автоматического режима. Возможно, настройки цифрового тюнера сбились из-за скачка напряжения или внутренних проблем.
- Увеличьте мощность антенны или измените ее положение. Иногда из-за плохих погодных условий антенна смещается. Вы замечаете, что сначала пропал первый, а потом и второй канал. В дальнейшем они могут пропасть все сразу. Если проблема возникла во время грозы, снега или дождя, ничего делать не нужно. В случае, если неисправность осталась после нормализации погодных условий, проверьте целостность кабеля и правильность расположения антенны. Для оценки сигнала жмите на значок i (INFO) на пульте и посмотрите на уровень. Если он слишком низкий, выполните регулировку и установите мощность на минимум.
Проверьте исправность оборудования. При поиске ответов на вопрос, куда пропали TV-каналы, нельзя исключать неисправность оборудования — цифровой приставки или телевизора. Убедитесь, что аппаратура включена в розетку, а на передней панели горят все индикаторы. В случае с тюнером возможна неисправность блока питания. Если он внешний, попробуйте его поменять. Если это не дает результата, обратитесь в сервис. Осмотрите кабель на целостность. Возможно, цифровой сигнал пропал из-за его повреждения.
Два способа, как поменять кодировку в Word
Ввиду того, что текстовый редактор “Майкрософт Ворд” является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.
Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, “перевести” которые невозможно.
Эти случаи чаще всего связаны лишь с одним – с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой.
Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона.
Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных “неисправностей”, но и, наоборот, для намеренного неправильного кодирования документа.
Определение
Перед рассказом о том, как поменять кодировку в Word, стоит дать определение этому понятию. Сейчас мы попробуем это сделать простым языком, чтобы даже далекий от этой тематики человек все понял.
Зайдем издалека. В “вордовском” файле содержится не текст, как многими принято считать, а лишь набор чисел. Именно они преобразовываются во всем понятные символы программой. Именно для этих целей применяется кодировка.
Кодировка – схема нумерации, числовое значение в которой соответствует конкретному символу. К слову, кодировка может в себя вмещать не только лишь цифровой набор, но и буквы, и специальные знаки. А ввиду того, что в каждом языке используются разные символы, то и кодировка в разных странах отличается.
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word. Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, – это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку “Файл” (в ранних версиях это кнопка “MS Office”).
- Перейти в категорию “Параметры”.
- Нажать по пункту “Дополнительно”.
- В открывшемся меню пролистать окно до пункта “Общие”.
- Поставить отметку рядом с “Подтверждать преобразование формата файла при открытии”.
- Нажать”ОК”.
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе “Ворд”, будет появляться окно. В нем вы сможете поменять кодировку открывающегося текста.
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту “Кодированный текст”, что находится в разделе “Преобразование файла”.
- В появившемся окне установите переключатель на пункт “Другая”.
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите “ОК”.
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне “Образец”. Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Способ второй: во время сохранения документа
Суть второго способа довольно проста: открыть файл с некорректной кодировкой и сохранить его в подходящей. Делается это следующим образом:
- Нажмите “Файл”.
- Выберите “Сохранить как”.
- В выпадающем списке, что находится в разделе “Тип файла”, выберите “Обычный текст”.
- Кликните по “Сохранить”.
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите “ОК”.
Теперь вы знаете два способа, как можно поменять кодировку текста в Word. Надеемся, что эта статья помогла вам в решении вопроса.
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицыправить
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | ||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Прием
Косплеер в роли Аски на выставке Marseilles Japan Expo 2011
Аска участвовала в различных опросах лучших аниме-пилотов и женских аниме-персонажей, оказавшись популярной как среди женской, так и среди мужской аудитории. В 1996 году она заняла третье место среди «самых популярных женских персонажей на данный момент» в обзоре Гран-при аниме от Animage mangazine, после Рей Аянами и Хикару Шидо из Magic Knight Rayearth . В 1997 и 1998 годах на Гран-при аниме ей также удалось остаться в десятке лучших женских персонажей; в 1997 году она заняла четвертое место, а в 1998 году — шестое. В ежемесячных опросах популярности Animage Аска также заняла третье место в августе 1996 года и седьмое в июле 1998 года. Ее популярность возросла после выхода второго фильма Rebuild of Evangelion ; в августе и сентябре 2009 года она вышла на первое место и оставалась самым популярным женским персонажем Neon Genesis Evangelion в рейтинге популярности журнала Newtype , а в октябре она заняла десятое место. В опросе Newtype, проведенном в марте 2010 года, она была признана третьим по популярности женским аниме-персонажем 1990-х годов сразу после Рей Аянами и Усаги Цукино из Pretty Guardian Sailor Moon . В 2017 году она заняла 16-е место среди персонажей аниме, с которыми читатели аниме предпочли бы умереть, чем выйти замуж.
Ее строчка «Ты дурак?» стала широко использоваться среди хардкорных фанатов с момента ее первого появления в 8-м эпизоде. Ценив ее за «хорошую дозу комического облегчения» Евангелиону , аниме-критик Пит Харкофф назвал ее «надоедливой соплей». Рафаэль Си из THEM Anime Reviews, который нашел характеристику Neon Genesis Evangelion «немного клише или временами просто раздражающей», презирал Аску за ее высокомерное отношение. Редактор Anime News Network Линзи Ловеридж заняла свое седьмое место среди «худших неудачников» в истории аниме. Критик IGN Рэмси Айслер назвал ее 13-м величайшим персонажем аниме всех времен за реалистичность ее персонажей, сказав: «Она трагический персонаж и полная крушение поезда, но именно это делает ее такой привлекательной, потому что мы просто не можем помогите, но наблюдайте, как разворачивается эта прекрасная катастрофа «. CBR включил ее в число лучших женщин-пилотов аниме, назвав ее «лучшим классическим цундэрэ в аниме сёнэн» и «одним из самых захватывающих персонажей аниме».
По словам критика Джея Телотта, Аска «является первым заслуживающим доверия многонациональным персонажем в истории японской SFTV». Crunchyroll также похвалил ее реализм и оригинальность, а Чарапедия написала: «Описание ее психологии реалистично и без принуждения, в отличие от многих других аниме-персонажей. Ее добрая и детская сторона — настоящая причина обаяния Аски». Бой Аски против евангелионов массового производства в «Конец Евангелиона» был особенно хорошо принят критиками, которые считали, что это был ее решающий момент, поскольку в остальном она остается статичной на протяжении большей части фильма. Также похвалили Тиффани Грант за роль актрисы озвучивания Аски на английском языке. Майк Крэндол из Anime News Network заявил, что Грант был «ее старым пылким я в роли Аски». Терон Мартин написала, что изображение Аски в Evangelion: 2.0 You Can (Not) Advance «отличается от начального», заявив, что она даже более антисоциальна, чем в оригинальном аниме. Мартин также написал, что, несмотря на то, что она кажется «наиболее социально адаптированным пилотом Евы в сериале», Аска из Evangelion 2.0 «не претендует на то, чтобы кому-то понравиться», и что она «кажется, в такой же степени мотивирована тем, что сделает свою будущую карьеру. в Nerv, как и она из-за своей личной гордости ». Эрик Суррелл также прокомментировал роль Аски в Evangelion: 2.0 You Can (Not) Advance, заявив, что «прибытие и внезапное увольнение Аски было шокирующим и депрессивным, особенно учитывая, насколько она была неотъемлемой частью оригинального Evangelion ». Саймон Абрамс из Slant Magazine , рецензирующий Evangelion: 2.0 You Can (Not) Advance , негативно оценил новые отношения Синдзи и Аски, «что прискорбно, потому что эта связь должна иметь возможность расти в свое время».
Читайте также
Собственный велосипед
Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.