Кей коллектор: инструкция по работе и настройке программы
Содержание:
- Бесплатная Книга«ПЯТКО 2018: Мастер семантического ядра — инструкция к применению» (87 страниц)
- Другие поисковые системы и рекламные сети
- Сколько стоит Key Collector
- Поиск конкурентов и их объявлений
- Парсинг
- Key Collector и СловоЕБ
- Общая настройка Кей Коллектора
- Очистка семантики от «мусора»
- Что может Key Collector
- Преимущества сервиса от Моаб очевидны:
- Дополнительный анализ семантики
- Процесс парсинга в Кей Коллекторе
- Почему лучше не собирать все маски в единой группе?
- Настройка прокси для Кей Коллектора
- Кей коллектор и семантика
- Подбираем маски
Бесплатная Книга«ПЯТКО 2018: Мастер семантического ядра — инструкция к применению» (87 страниц)
Я уже несколько лет как даю его бесплатную книгу к своим тоже бесплатным курсам по SEO, потому что не знаю, что можно было бы лучше посоветовать, для дополнительного изучения этой темы. Перепечатывать в своих курсах книгу Романа мне смысла нет. А лучше, чем его материал по основам СЯ, я не встречала.
Все очень стройно, четко, по полочкам, с отличным знанием дела и накопленным структурированным опытом.
Это бесплатная книга по бесплатному сбору Семантического Ядра, поэтому там дается во второй части инструкция по программе СловоЕб, которая является открытым аналогом программы Key Collector (платить за СловоЕб не нужно).
Кроме этого, в главе 5 есть и инструкция по Кей Коллектору тоже, с его настройками и подготовке интерфейса.
Глава 6 про группировку ядра была недавно дополнена и видеозаписями.
Содержание книги:
Блок 1 — Знакомство с основами семантического ядра
Маркетинговое сегментирование аудитории по теплоте запросов Типы поисковых запросов Целевые / Нецелевые | Определение Синонимы | Определение Хвосты | Определение Операторы Яндекс Wordstat / Директ Виды частоты | Введение / Определение L:SI — копирайтинг и виды частоты «!» Конкуренция запросов (KEI)
Блок 2 — Начальный список
Структурный анализ конкурентов Мнемотехника Тезаурус
Блок 3 — Особенности подбора семантического ядра
Блок 4 — Бесплатный метод сбора семантического ядра
Как собирать начальный список ключей в СловоЁБ Настройка программы и рабочей области Парсинг Вычисление частоты Удаление пустышек Чистка ключевых слов от мусора Экспортирование готовой семантики Резюме
Глава 5 — Профессиональный метод составления семантического ядра
Настройка Key-Collector Технология составления начального списка ключей / базисов Методика структуризации начального списка для парсинга Структурный парсинг Wordstat Сбор поисковых подсказок Расширяем охват семантики Сбор частоты Фильтрация и удаление пустышек Техника правильной чистки ключей от мусора Вычисление данных к ключевым фразам Выгрузка готового семантического ядра Задание
Бесплатные SEO курсы от Анны Ященко — 20 PDF-уроков, за 2020 год — Хорошие. Для новичков, но и не только. Достаточно глубокие, актуальные и системные. Хотите научиться самостоятельному бесплатному продвижению сайтов? Пожалуйста.
Глава 6 — Оптимизация семантического ядра
Метод определения конкуренции ключевых слов для дальнейшей разметки Разметка ключевых слов по уровню конкуренции Разметка семантического ядра по частоте Наиболее эффективная группировка семантического ядра Несколько видео для понимания правильной группировки Составление контент-плана для копирайтера Результат работы Ссылки на материалы проекта
Другие поисковые системы и рекламные сети
В этой статье я рассматривал наиболее популярную область применения Коллектора – парсинг с Yandex.Wordstat. Если вы хотите использовать это приложение для сбора семантического ядра с каких-то других поисковых систем или рекламных сетей, то вам также придется настраивать каждый отдельный пункт.
Возможно, в будущем появится отдельная статья о подробной настройке каждого пункта этой замечательной утилиты, но если вам невтерпеж, то вы можете воспользоваться официальным мануалом от разработчиков. В нем достаточно подробно рассматриваются аспекты настройки Adstat Rambler, LiveInternet, Google AdWords и других. Обязательно ознакомьтесь с представленным материалом.
Сколько стоит Key Collector
Стоимость зависит от того, на каком количестве компьютеров или рабочих мест вам нужно установить и активировать программу.
Допустим, она нужна четырем сотрудникам. Вы покупаете 4 лицензии: первая обходится в 1 800 рублей (при электронном расчете), вторая, третья и четвертая – уже по 1 400 каждая.
P.S. В этой статье мы затронули только те функции сервиса Key Collector, без которых не обойтись при настройке контекстной рекламы. Помимо комплексной работы с ключами Key Collector также работает с содержимым сайта, проводит экспресс-анализ на соответствие семантике и дает рекомендации по внутренней перелинковке.
Поиск конкурентов и их объявлений
И напоследок – фича сервиса, не связанная напрямую со сбором семантики, но полезная при создании рекламных объявлений. Вы можете посмотреть, кто ваши прямые конкуренты и какая у них реклама.
Выберите инструмент «Анализ SERP».
Нажмите «Получить все данные» – «Поиск конкурентов».
Появитсяокно с настройками, где вы указываете порог совпадений (входа в список конкурентов)
По умолчанию стоит 5 – то есть система считает рекламодателя вашим конкурентом, если его сайт появляется в выдаче по тем же ключевым фразам от 5 раз и выше.
После клика по кнопке «Искать» вы увидите список прямых конкурентов, ключевые слова, по которым у них настроена реклама.
Обратите особое внимание на тех рекламодателей, кто входит в Топ-10 выдачи нужной вам поисковой системы. Агрегаторы игнорируйте – они будут всегда по любому товарному запросу.
Теперь про объявления
Их можно собрать в Key Collector сразу по нескольким поисковым запросам, но в общем виде – без расширений. Для этого нажмите иконку «Сбор статистики Yandex.Direct» и активируйте галочку «Собирать информацию о конкурентах (объявления)».
Парсинг
Далее переходим к следующему шагу — жмём «Начать сбор»:
Обратите внимание: если перед добавлением слов в проект вы отключали удаление знака «+», то перед парсингом нужно вернуть его обратно. Если, конечно, вы не хотите, чтобы слова попадали в «вордстатовском» виде, например, «купить шкаф +в москве +на таганке».
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед»
Профит!
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед». Профит!
После минусовки рекомендуем «спарсить» ядро ещё несколько раз, так как у каждой собранной ключевой фразы могут быть вложенные фразы, которые не «спарсились» на первом круге. Собранное «отминусованное» ядро в таком случае будет новым списком масок.
Повторно следует «парсить» не все слова, а только высоко- и среднечастотные запросы, так как в низкочастотных вложенных запросов почти не будет.
Чтобы понять, как много вложенных запросов у конкретного слова, можно снять его частотность в широком и в точном соответствии, а затем поделить широкое на точное. Чем больше соотношение, тем больше в ключевике вложенных фраз. Это такой себе «коэффициент замусоренности». Также вложенные запросы можно почистить через прогнозатор «Яндекс.Директа». Кому как удобнее.
А после завершения парсинга не забудьте прогнать полученные фразы через инструмент KC «Анализ неявных дублей». Он поможет найти в списке дубли в стиле «купить велосипед москва» и «купить велосипеды в москве» — и удалить их по заданным условиям.
В следующей части статьи мы расскажем, как отминусовать ненужные слова, сгруппировать нужные, перенести данные в Excel и подготовить объявления для «Яндекс.Директа» или Google AdWords.
Авторы статьи:Анастасия Якунина, production-менеджер в Adventum,Артур Семикин, performance-менеджер в Adventum.
Читайте далее: Как проработать семантическое ядро с помощью Key Collector. Часть 2
Key Collector и СловоЕБ
Это комплексная десктопная программа, в которой есть буквально всё для работы с контекстной рекламой, в том числе сбор семантического ядра.
Чтобы сделать парсинг в Key Collector, добавляем фразы:

Запускаем парсинг. Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.
Подробнее настройки описаны здесь.
Также Key Collector позволяет очистить семантическое ядро от «мусора», а именно:
- Ключевиков, которые содержат ненужные слова;
- Повторов слов;
- Стоп-слов (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.);
- Запросов с нулевой частотностью.
Есть бесплатный аналог Key Collector – СловоЕБ. Основное его ограничение – в источниках. Он работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.
Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики, установленные на сайте (Google Analytics, Яндекс.Метрика, LiveInternet).
Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную.
Однако этого функционала будет вполне достаточно, если у вас небольшой проект.
Общая настройка Кей Коллектора
Для работы с вордстатом понадобиться: здесь все просто, нужно отдельно зарегистрировать яндекс почту и создать там тестовую рекламную кампанию, можно с одним объявлением, можно просто черновую (без прохождения модерации и пополнения бюджета). В программе просто прописываем логин и пароль от почты и все работает.
Для работы с гугл планером понадобиться: зарегистрировать новый аккаунт в гугл адвордс. В обязательном порядке скачать последнюю версию браузера internet explorer и зайдя исключительно через данный браузер, также создать тестовую рекламную кампанию (без бюджета и активности). Главное заполнить все настройки пользователя — указать язык и местоположение. Фокус заключается в том, что без данных манипуляций, использовать гугл планер не получиться.
Переходим непосредственно к настройкам:

Заходим в настройки программы во вкладку Яндекс Вордстат», где выставляем следующие параметры:
— глубина парсинга — 0. Выставляя такое значение, вы будите получать обычный парсинг, но программа может автоматом парсить и в глубину, т.е. спарсив ключевые слова, она может парсить то, что уже спарсила, разбивая ключевые слова на более конкретные ключевые слова. Смысла глубокого парсинга нет, так как система будет парсить дубли, а не уникальные ключевые слова, и даже без глубокого парсинга мы все равно будем по нему показываться, так как используем основную маску. Если просто — глубокий парсинг делать не надо, выставляем значение ноль.
— парсить страницы, здесь выставляем стандартное значение — 40.
— добавлять в таблицу фразы с частотами от 1 до 99999999999. Здесь вы указываете какую частотность вы хотите видеть с парсенных ключевых слов. Есть директологи, которые не парсят все доскональна, а работают с ключевыми словами, которые имеют частотность от 10 и выше. Я же советую вам парсить все и начинать с 1. При таком подходе у вас будет самое полное семантическое ядро, а если вы решите, что такие ключевые слова вам не нужно, то уже после парсинга, можно при помощи фильтра выделить такие ключи и удалить.
— не снимать частоты для фраз меньше или равной 0. Логика проста, нам не нужно пустые ключевые слова, которые не будут приносить трафик, поэтому такие не ищем.
— количество потоков. Если вы используете одну почту от яндекс директа, то можете смело выставлять сразу 2 потока, и таким образом программа будет работать в два раза быстрее. И если вы не используете прокси сервера, то не убираем галочку «Использовать основной IP адрес».

Далее заходим во вкладку «Яндекс Директ», где указываем адреса свои электронных почт от яндекса и пароли от них. Достаточно указать 1-2 почты.

Во вкладке «Гугл Адвордс» указываем доступы от гугл адвордс (что логично).
Собственно, это все стандартные настройки, после которых заработает кей коллектор.
Очистка семантики от «мусора»
Что делать с полученными результатами?
Во-первых, найдите «мусорные» ключи и избавьтесь от них – с большой разницей между базовой частотностью и точной (в кавычках).

Допустим, если базовая частота превышает 30, а точная близка к 0, смотрите, насколько адекватные это фразы, насколько они подходят под вашу тематику. В большинстве случаев они не приведут на сайт целевой трафик.
Во-вторых, стоит избавиться от неявных дублей – фраз, которые включают одинаковые наборы слов, но в разном порядке. Они между собой не конкурируют, но увеличивают время на создание объявлений.
Настройте их удаление следующим образом: перейдите на вкладку «Данные», кликните «Удаление неявных дублей» и затем – «Выполнить умную групповую отметку» и «Удалить отмеченное».
В-третьих, в Key Collector можно составлять списки минус-слов, чтобы программа их сразу же отфильтровывала в выдаче результатов. Нажмите значок «Стоп-слова», скопируйте или загрузите список в такое окно и примените при сборе семантики из Вордстата, как показано ниже.
Чтобы они выделялись цветом в таблице результатов, нажмите «Отметить фразы в таблице».
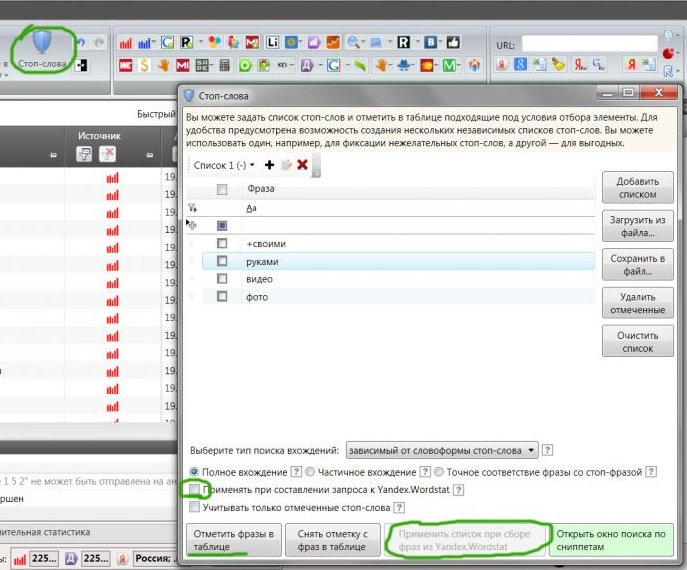
Источник
Чтобы заминусовать ключ из результатов Key Collector, выделите его галочкой и нажмите «Добавить в стоп-слова».

Однако даже за вычетом минус-слов собранная семантика еще недостаточно «чистая», чтобы применять её для запуска рекламы. Посмотрим, какие еще инструменты Key Collector могут быть полезными.
Что может Key Collector
Возможности программы просто поражают воображение. На выходе она дает не просто список ключей, а ключей:
- Из самых разных популярных источников (среди них – рекламные сервисы Yandex Wordstat, Google Ads, Rambler Adstat) и поисковых подсказок систем
- Вместе со статистикой из Liveinternet, Google Analytics, Яндекс.Метрики, Яндекс.Вебмастер, Serpstat и других сервисов
- С учетом конкретного региона и сезонности
- По нужной глубине поиска
- С оценками стоимости продвижения, популярности, конкуренции, трафика и других параметров
- Со значениями частотности
- С возможностью последующей группировки (кластеризации)
- С возможностью составления минус-списков.
Так выглядит интерфейс программы:

Далее мы отдельно рассмотрим весь функционал по блокам – как поможет вам Key Collector при сборе и анализе семантики, при группировке запросов и изучении конкурентов.
Преимущества сервиса от Моаб очевидны:
— Глубина парсинга на площадке достаточно большая. Дополнительно, есть вариант выбора длины хвоста.
— Скорость выполнения исследования достаточно высокая. Для сравнения обычная обработка запроса «ОКНА» занимает 14 часов, а при использовании ресурса процесс заканчивается за 5 часов и приносит даже большее количество результатов.
— берёте пакет ПРО за 4999 рублей, а получаете почти бесконечный боезапас, полноценный Key Collector и огромное количество бонусов.
— Никакие капчи, прокси и прочие проблемы подборки вас не беспокоят. Просто нажимаете кнопку и получаете результат.
— 500 000 фраз — это объем, на википедию, не говоря уж о простых ресурсах.
Большой полюс в MOAB Tools — качество подбора фраз. Попробуйте в действии все функции на тарифе Free и убедитесь в возможностях сами. Лучше один раз потрогать, чем сто раз услышать.
Не упустите свой шанс и принимайте участие в акции тут.
SimpleSearch — поиск по сайту
Новая технология сбора семантики >
Дополнительный анализ семантики
Программа Key Collector также позволяет изучить запросы на предмет конкурентности (иногда это называют сложностью запроса) и сезонности, а также разбить на кластеры, что важно уже на этапе создания рекламы. Рассмотрим эти функции.
Оценка конкурентности запросов
Уровень конкуренции запросов зависит от:
- Количества документов в поисковой выдаче по этому запросу
- Количества главных страниц в поисковой выдаче
- Количества точных вхождений ключа в заголовки страниц выдачи.
В Key Collector можно рассчитать этот показатель как в зависимости от количества страниц в выдаче (деление количества страниц на частотность ключевой фразы), так и настроить в формуле все перечисленные показатели.
Для этого найдите функцию KEI и примените её к списку ключей, которые у вас получились в результате сбора семантики.
Найдите в меню такой значок, как показано на скриншоте, и нажмите «Рассчитать KEI по имеющимся данным»:

Можно оставить формулу по умолчанию, а можно установить свою, добавив в настройках «KEI & SERP» нужные колонки:

Соответственно, чем выше значения получатся, тем выше уровень конкуренции поисковых запросов. Значит, по ним рекламируется большее количество рекламодателей.
Оценка сезонности запросов
Если вы работаете с сезонным спросом, важно знать, какую семантику когда использовать.
Инструмент «Сезонность» находится здесь:
Нажмите «Дополнительная статистика», и вы увидите график с данными по частоте использования запроса по вертикали и временной разбивкой по горизонтали:
Для удобства его можно скачать себе на компьютер в csv:
Кластеризация (группировка) запросов
Когда семантика готова и очищена от минус-слов и прочего «мусора», стоит разбить связанные между собой ключи на группы. Чтобы писать объявления не под каждый ключ – а их могут быть тысячи и сотни тысяч, – а для групп.
Key Collector предлагает свой способ группировки, который можно настроить в меню «Анализ групп». Сгруппировать запросы можно, например, по поисковой выдаче, если вы предварительно рассчитали конкурентность запросов с помощью функции KEI.

Процесс группировки может занять до часа. Результаты также можно выгрузить в отдельном файле.
Процесс парсинга в Кей Коллекторе
Сам процесс достаточно прост и не является чем-то сложным и выполняется в автоматическом режиме.
Первоначально нужно сразу же выставить нужное гео для парсинга, это делается в самом низу программы:
После этого нужно создать папки, куда будут помещаться спарсенные ключевые слова, папки создаются в левой колонке программы. Конечно можно парсить все в одну папку и потом делать группировку ключей, но логичнее и удобнее заранее поделить маски ключей по смыслу и парсить маски по папкам. Например: есть две маски ключей, которые хотим спарсить — вызов такси и заказать такси, для удобства дальнейшей работы с ключами, парсим маски не в общую папку, а в соответствующие две папки, чтобы ключи уже были отсортированы.
Кроме этого, если масок не много, то можно каждую папку назвать маской и тогда программа сделает парсинг по названию папки, что является очень удобным функционалом.
Для этого заранее создаем нужные папки и нажимаем на парсинг с вордстата. По умолчанию стоит галочка «Добавить в текущую группу», но нужно поставить галочку «Распределить по группам» и нажать на красную стрелочку, как показано на картинке. Здесь можно в каждую папку поместить нужные маски (т.е. не каждую маску парсить отдельно, а чтобы в одной папке были распарсено сразу несколько масок ключей); можно убрать не нужные папки и стоит заметить, что названия папок тоже будут распарсены (если этого вам не нужно просто убираем не нужное ключевое слово). Далее нажимаем на «Начать сбор» и происходит парсинг, после которого идет следующая работа — сбор минус слов, чистка ключей и их группировка:
Почему лучше не собирать все маски в единой группе?
Во-первых, при большом количестве масок Key Collector работает медленно (но в разы быстрее, чем человек). Когда у вас «спарсится» первая подгруппа, вы уже сможете с ней работать — минусовать, группировать, анализировать. Параллельно будут собираться и остальные подгруппы. Этот подход здорово экономит время, когда нужно оперативно «спарсить» маски.
Во-вторых, если ядро новое и незнакомое, вы не знаете, как поведёт себя та или иная маска. Некоторые из них (на вид безобидные ) могут оказаться чертовски мусорными. Например, при сборе РК по видеонаблюдению в маске «камера школа» мы нашли уйму порно и куда меньше запросов о видеонаблюдении. Если решите собирать всё в одной группе, а в список попадёт такая маска, у вас в один лист «спарсится» 10 000 слов, 5000 которых будут мусорными.
В результате вам придётся несколько часов вычищать неподходящие фразы. Разумнее парсить в разные группы — тогда маска «камера школа» будет стоять особняком.
Другая крайность: масок очень много (больше 200–300). Раскидывать их по отдельным группам долго, да и нагрузка на программу неоправданно высокая. В таком случае создаём отдельную группу не под одну, а под несколько масок, желательно близких по смыслу. Обычно это столбцы или строки из нашей матрицы масок. Для этого приёма необходимо выбрать способ группировки (например, по столбцам):
Затем копируем заголовки групп и вставляем их в инструмент сбора Key Collector, жмём «Распределить все фразы по одноимённым группам» — и получаем список выбранных групп:
Удаляем из них первые слова (это просто названия столбцов) и вставляем сами группы:
Важный момент. Если используете в списке масок операторы или минус-слова, перед добавлением этих слов в Key Collector проверьте в настройках, не включено ли автоматическое удаление символов:
В противном случае фраза «Шкаф +в Москве — холодильный» отправится на парсинг как «Шкаф в Москве холодильный».
Настройка прокси для Кей Коллектора
Зачем нужны прокси? Они нужны тогда, когда идет работа с большим объемом парсинга, т.е. когда у вас не 40-100 ключевых масок, а несколько тысяч. Так используя прокси можно работать не в один — два потока, а в 5-10 потоков, и тогда парсинг при больших объемах закончиться не через неделю, а уже сегодня.
Для настройки прокси нужно: а) купить прокси; б) настроить кей коллектор под прокси.
Купить прокси можно здесь — https://proxy-sale.com/proksi-dlya-keycollector.html, но можно найти и дешевле. Вам нужно выбрать прокси, именно для кей коллектора, чтобы было четко написано, что прокси подходит для кей коллектора, если возникают вопросы, то лучше обратиться в поддержку сайта, там все подскажут.
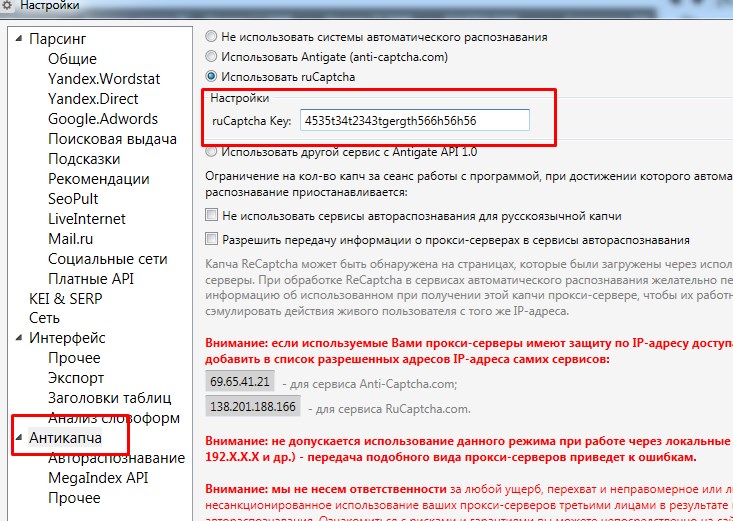
Так же вы можете купить антикапчу, чтобы она распознавалась автоматически. Заходим на сайт — https://rucaptcha.com/, где покупаем данную услугу, всего хватит 100 рублей, которые вам прослужат не один год. После оплаты вам будет дан цифровой ключ, который помещается в специальную строку в кей коллекторе:
Далее заходим во вкладку «Яндекс Вордстат» и убираем галочку «Использовать основной IP-адрес». Здесь же можно задать количество потоков. Если вы используете один прокси сервер, то выставляете 2 потока, если два прокси сервера, то указываете 4 потока, т.е. на один прокси сервер выставляем по два потока.

Далее заходим в «Яндекс Вордстат», где прописываем новые аккаунты. Как правило, при покупке прокси, вам дается новая почта в яндексе, она регистрируется для вас бесплатно, либо вы сами можете ее зарегистрировать, главное, чтобы на одну прокси была своя отдельная почта в яндексе, т.е. сколько прокси, столько и почтовых ящиков.
Далее заходим на вкладку «Сеть», где активируем галочку «использовать прокси-серверы SOCKS 5» и добавляем непосредственна информацию о купленных прокси-серверах. после этого прокси должно работать. Если что-то не работает стучимся в поддержку кей коллектора.

Кей коллектор и семантика
Работа с подбором ключевых вхождений после создания сайта не заканчивается, поэтому ресурс будет полезен не только разработчикам. Продвижение контекстной рекламой, работа с заголовками и многие другие задачи требуют знания частотности.
Бесспорно, Key Collector — лучшая утилита анализа статистики по запросам. Когда начинаешь пользоваться, возникает масса вопросов. Какие прокси использовать, какие кнопки нужные, какие настройки использовать, как собирать статистику, чтоб тебя не заблокировали? Все настроил, через какое-то время заходишь и уже ничего не можешь вспомнить. Заново приходится изучать. Это отнимает много времени, и хочется делегировать работу в надежные руки. С Моабом все становится в разы проще: купил подписку и юзай, без заморочек. Временных лимитов у услуги нет и это большой плюс.
Тем, кто ручками в вордстате сборку делает, совсем не позавидуешь. Там одну капчу запаришься вводить. В Моабе все становится совсем просто. Вносишь список слов и запускаешь процесс. Служба соберет тебе слова на всю указанную глубину, выдаст подсказки, уберет дубли и выдаст все одним файлом. Пользуйтесь.
Подбираем маски
Пробиваем маски через Wordstat и ищем похожие запросы.
Пример: собираем РК для бокс-клуба. Наши маски: «записаться на бокс», «занятия боксом» и т. д. Само слово «бокс» слишком широкое по смыслу. Включить его в нашу РК даже в точном соответствии нельзя. Но мы можем пробить слово «бокс» (уточнённое высокочастотными минус-словами) через Wordstat и найти ещё несколько масок, например, «абонемент на бокс», «тренера по боксу» и т. п.
Конкурс Дикси для digital-агентств
Разработайте классную идею в одной из 18 номинаций онлайн-конкурса – и получите возможность реализовать ее с Дикси, выиграть отличные призы от Коссы/Руварда – и получить заслуженное признание рынка.
Идеи и концепции агентств принимаются на конкурс до 7 декабря,
поторопитесь!
Кроме того
-
Изучайте отчёты по реальным поисковым фразам в «Яндекс.Метрике» и Google AdWords.
-
Используйте сервисы подбора синонимов.
-
Пользуйтесь формулами сцепки в Excel или сервисами перемножения. Excel позволяет рассортировать все полученные маски «по полочкам», точнее, по столбикам. Сервис перемножения, наоборот, формирует единый столбец. Что удобнее — зависит от ситуации.
-
Используйте минус-слова уже на уровне масок для уточнения запросов. Например, мы собираем ядро для шкафов, предназначенных для разных помещений. Очевидные маски: «Шкаф гостиная», «Шкаф прихожая» и т. д. Но также можно пробить «Шкаф -духовой -холодильный» — этими минусами мы отсеем половину мусора уже на входе.
-
Пользуйтесь операторами «+» и «!», чтобы вытянуть большее количество слов из Wordstat. (Знак «!» фиксирует падеж и число слова, а «+» нужен для принудительного учёта предлогов и союзов.) По запросу с использованием операторов Wordstat выдаёт новую выборку, в которой могут оказаться и новые слова.
Пример: пробиваем маску «купить шкаф». Wordstat выдаёт фразы со следующей частотностью:
-
«купить шкаф» (100 000 показов);
-
«купить шкаф москва» (50 000 показов);
-
«купить шкаф недорого» (10 000 показов).
-
…
Далее пробиваем маску «Купить шкаф +в» — и тут Wordstat выдаёт новую картинку:
-
«купить шкаф +в» (70 000 показов);
-
«купить шкаф +в спальню» (40 000) показов;
-
…
Во вторую выборку попал запрос «купить шкаф +в спальню» (40 000 показов). Это вложенная фраза для «Купить шкаф». Судя по количеству показов, она должна оказаться в первой выборке между фразами «Купить шкаф москва» (50 000) и «Купить шкаф недорого» (10 000), но её там нет.