Как найти удаленную информацию с веб сайта?
Содержание:
- Проекты, предоставляющие историю сайта
- Как найти нужный веб-архив и восстановить сайт без бекапа
- Как посмотреть историю сайта
- Плюсы и минусы привлечения подписчиков без накрутки
- Вконтакте
- Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
- Смотрим каким был сайт ранее
- Что такое веб-архив и зачем он нужен?
- Немного о резервных копиях
- HTML верстка и анализ содержания сайта
- Уникальный контент из «мертвых» сайтов
- Индексация веб-страниц в интернете
- web.archive.org
- Как вытянуть из Webarchive уникальный контент для сайта
- Просмотр истории посещения в браузере:
- Как сделать бэкап сайта и спать спокойно?
Проекты, предоставляющие историю сайта
 Peeep.us в действии
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Как найти нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
Возможно, что это делается во избежании потери данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру одного из веб-архивов, вы увидите копию своего (в данном примере моего) сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающее на ДжаваСкрипте полностью исчезло:
Но это не столь важно, ибо в исходном коде страницы с web.archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится
Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomu-vnutrennej-optimizaciej.html
Понятно, что можно будет вручную отсечь вступительную часть ссылок (), получив таким образом рабочий вариант. Можно этот процесс даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет воспользоваться встроенной в этот сервис возможностью замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки браузера — начинается с ). Он будет иметь примерно такой вид:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
И вставляете в него конструкцию «id_» в конце даты (), чтобы получилось так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Теперь измененный адрес обратно возвращаете в адресную строку браузера и жмете на Enter. После этого страница c архивом вашего сайта обновится и все внутренние ссылки станут прямыми. Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что восстановление таким образом огромного сайта займет чудовищное количество времени, но когда другого варианта нет, то и такой покажется манной небесной. К тому же, страдают невозвратной потерей контента обычно только начинающие вебмастера, у которых этого самого контента было мало, а более-менее опытные сайтовладельцы, уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые содержатся в недрах этого мастодонта, то вам нужно будет вставить в адресную строку браузера следующий адрес и нажать Enter:
http://wayback.archive.org/web/*/ktonanovenkogo.ru*
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этого форме:
Например, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive. Зачем — не знаю, но захотел.
Как посмотреть историю сайта
Конечно, после выполнения модернизации сайта есть желание его сравнить с теми версиями сайта, которые были раньше. Но если не знаешь, возникает вопрос, как посмотреть историю сайта, где её посмотреть? На помощь может прийти сервис archive.org. На сервисе archive.org собрано более, чем пол триллиона сайтов. Причем, каждый сайт (блог) представлен там, в различный период времени.
Например, Вы открываете сайт и хотите посмотреть, как он выглядел в феврале 2013 года. Вы действительно его увидите таким, каким он был в тот период времени. Опубликованные на блоге статьи сможете открыть и прочитать их, даже если автор эти статьи уже удалил. Вы можете проверить историю сайта за каждый месяц, за каждый год. Представляете, какой объём информации хранит сервис archive.org!
Многие люди пишут на форумах — archive.org заблокирован, как зайти? Действительно, если просто зайти по адресу первого сайта, то сервис archive.org почему то работает не корректно.
Итак, открывается окно сервиса archive.org, далее в поле нужно ввести доменное имя своего сайта и нажать кнопку «Browse history». Теперь выбираем дату архивирования своего сайта из встроенного календаря, сначала выбираем год, далее месяц и день.
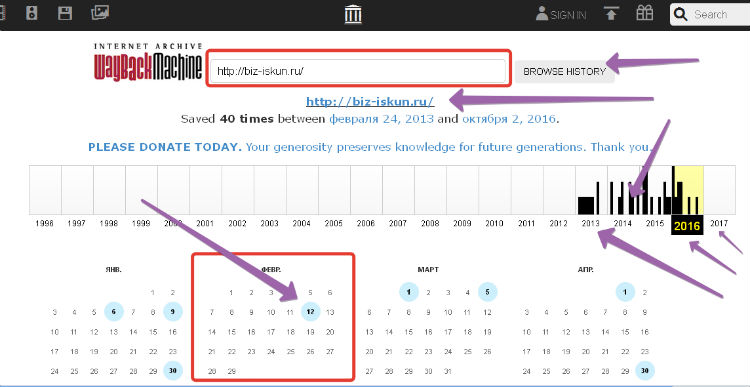
День нужно выбирать тот, который отмечен голубым кружочком – нажимаем на дату. Теперь можем посмотреть историю нашего ресурса. Мы можем посмотреть историю сайта своего или чужого. А сейчас можете посмотреть видео, как узнать историю ресурса с помощью сервиса archive.org:
Плюсы и минусы привлечения подписчиков без накрутки
Любому аккаунту нужны подписчики, которых можно найти, не прибегая к накрутке. При этом следует знать плюсы и минусы такого продвижения.
Достоинства:
- Нет риска блокировки аккаунта.
- К аккаунту присоединяются живые подписчики.
- Профиль можно раскрутить без материальных вливаний.
Недостатки:
- Работу по увеличению вовлеченности аудитории нужно проводить регулярно.
- Понадобится много времени для осуществления мероприятий по привлечению фолловеров.
- Не все методы раскрутки увеличат количество подписчиков.
Обратите внимание! В эпоху коронавируса все ищут дополнительные возможности заработка. Удивительно, что альтернативными способами зарабатывать можно гораздо больше, вплоть до миллионов рублей в месяц
Один из наших лучших авторов написал отличную статью про заработок на играх с отзывами людей.
Вконтакте
Ради прикола я еще решил проверить социальную сеть вконтакте и посмотреть предыдущие версии этого сайта. Все мы помним, что сеть начала свою деятельность еще в 2006 году и тогда сайт располагался по адресу vkontakte.ru, а не vk.com. Вот его я и решил ввести и посмотреть его в 2006 году. Вы помните такой дизайн? Вот таким он был.
Я зарегистрировался в 2007 году (помню, как даже смотрел дату регистрации в вк) и вот так выглядел тогда этот сайт.
В 2011 году ВК ограничил свободные регистрации в связи с наплывом фейковых страниц. там просто так было нельзя. Нужно было получить приглашение от зарегистрированного пользователя. И вот тогда главная страница смотрелась так.
А с 2012 года сайт переходит на новый домен vk.com, и со старого происходит автоматическая переадресация. Поэтому с этого момента у вас не получится посмотреть, как выглядел vkontakte.ru например в 2013 году, так как надо вводить уже современный адрес и смотреть там.
В общем как-то так. Здорово, да? Я вот прошелся по старым дизайна вконтакте, и аж ностальгия взяла. Когда я регистрировался, там находилось всего чуть более миллиона человек. А теперь там сотни миллионов.
Ну в общем рекомендую вам тоже пройтись по задворкам прошлого и взглянуть, как всё выглядело раньше. А на сегодня я уже буду закругляться. Надеюсь, что статья была для вас интересной, поэтому не забудьте подписаться на обновления моего блога. С нетерпением буду вас снова ждать у себя в гостях. Удачи вам. Пока-пока!
Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
В данной статье мы рассмотрим способы просмотра старых копий страниц, но здесь нужно отметить, что таким способом можно посмотреть только профили тех людей, что не были скрыты настройками приватности, которые закрывают страницу от поисковых систем. При этом здесь можно посмотреть даже те страницы, что ранее были удалены.
Сначала мы расскажем о том, как посмотреть старую версию страницы, пользуясь популярным поисковиком Google, который умеет сохранять различные страницы в Интернете в их ранних версиях. Но здесь нужно понимать, что все эти сохраненные страницы остаются в памяти поисковика на ограниченный период времени, то есть старая версия удаляется после того, как она будет сканирована снова.
В поисковой строке нужно ввести запрос с именем человека «ВКонтакте», а также со специальным добавлением site:vk.com, чтобы Google показывал результаты только внутри этой социальной сети. В поисковой выдаче далее нужно найти требуемую страницу и рядом с нею нажать на кнопку с зеленым треугольником, чтобы открыть меню с дополнительными функциями. Далее в отобразившемся списке нужно выбрать пункт «Сохраненная копия».
После этого пользователь попадет на страницу искомого человека, причем на ту ее версию, что сканировалась поисковиком Google в предыдущий раз. В зависимости от того, насколько старая версия в итоге откроется, может изменяться даже сам интерфейс социальной сети «ВКонтакте».
Также стоит отметить, что даже если пользователь уже авторизовался в этой социальной сети, он увидит данную страницу со стороны человека, которые не зарегистрирован «ВКонтакте», то есть как анонимный посетитель, потому что именно так видят профили на данном сайте роботы Google. Если же пользователь решит зайти в свой профиль, чтобы подробнее просмотреть материалы, размещенные на сохраненной версии найденной страницы, он просто попадет на оригинальную текущую версию «ВКонтакте». Это значит, что таким способом можно посмотреть только ту основную информацию, что была размещена непосредственно на самой странице человека, а все остальные дополнительные материалы просто не получится открыть. Именно поэтому здесь нельзя будет, например, просмотреть список подписчиков или все фотографии человека. Также стоит заметить, что смотреть старые сохраненные версии профилей известных и популярных людей в этой социальной сети, по сути, не имеет никакого смысла, потому что на эти страницы заходит слишком много людей, а потому они намного чаще сканируются поисковыми системами.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
- Введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com):
- И нажмите на кнопку «Browse history» (просмотреть историю) справа.
Система обработает запрос и выдаст вам результат. Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.

История сайта за 2005 год
Выберите дату сохранённого сервисом скриншота
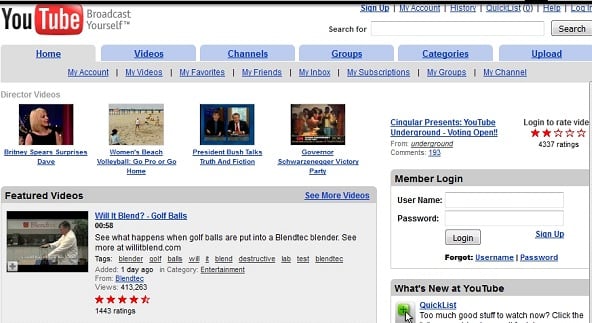
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Кликаем на 28 апреля и просматриваем, как выглядел сервис Youtube 28 апреля 2005 года.
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
Также можно работать с данным сервисом напрямую, введя в адресной строке вашего браузера:
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web.archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Что такое веб-архив и зачем он нужен?
 Веб-архив — история миллионов сайтов
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Немного о резервных копиях
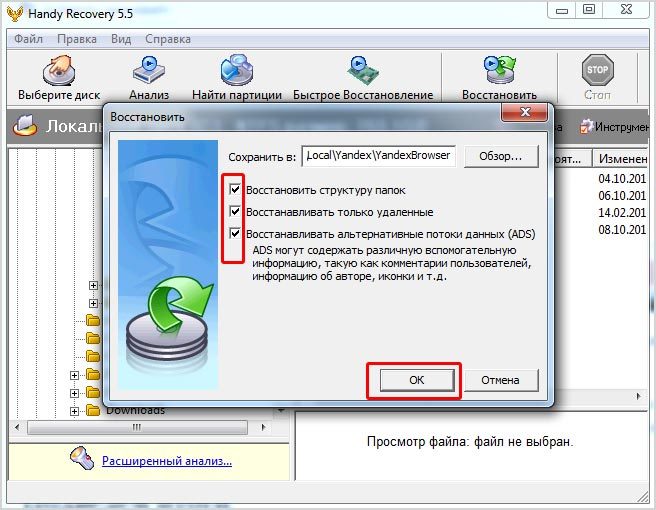
В данной статье речь пойдет про восстановление из резервной копии (бэкапа), выложенной в корень аккаунта через нашу систему BackUp. Подробнее о системе резервного копирования и работе с разделом BackUp вы можете узнать в руководстве по панели управления.
В процессе создания резервной копии в разделе BackUp, при выборе действия «Выложить на аккаунт», в корне Вашего аккаунта создаётся архив, содержащий в себе файловую структуру выбранного каталога.
Восстановление файловой структуры подразумевает под собой распаковку архива в нужную директорию. Если в целевом каталоге есть файлы с таким же именем, как и в архиве — они будут перезаписаны.Если вы восстанавливаете сайт после заражения вирусами, корневую директорию сайта нужно предварительно очистить, поскольку те файлы, которые на момент создания резервной копии отсутствовали на вашем сайте, останутся в сохранности.
Имя архива можно посмотреть во вкладке «История заданий» раздела BackUp, нажав на ссылку в колонке «Статус». Если с момента заказа вами резервной копиии ее статус не сменился на «Выполнено» — значит архив еще не загружен в корень Вашего аккаунта, и необходимо немного подождать.
Большинство сайтов использует в своей работе как файлы, так и базу данных. Восстановление работоспособности сайта проходит в 2 этапа:
- Восстановление файловой структуры
- Способ №1: Файловый менеджер
- Способ №2: Терминал
- Восстановление базы данных
- Способ №1: phpMyAdmin
- Способ №2: Терминал
Тем не менее, в зависимости от проблемы на сайте, можно обойтись и одним этапом.
HTML верстка и анализ содержания сайта
Размещённая в данном блоке информация используется оптимизаторами для контроля наполнения контентом главной страницы сайта, количества ссылок, фреймов, графических элементов, объёма теста, определения «тошноты» страницы.
Отчёт содержит анализ использования Flash-элементов, позволяет контролировать использование на сайте разметки (микроформатов и Doctype).
IFrame – это плавающие фреймы, которые находится внутри обычного документа, они позволяет загружать в область заданных размеров любые другие независимые документы.
Flash — это мультимедийная платформа компании для создания веб-приложений или мультимедийных презентаций. Широко используется для создания рекламных баннеров, анимации, игр, а также воспроизведения на веб-страницах видео- и аудиозаписей.
Микроформат — это способ семантической разметки сведений о разнообразных сущностях (событиях, организациях, людях, товарах и так далее) на веб-страницах с использованием стандартных элементов языка HTML (или XHTML).
Уникальный контент из «мертвых» сайтов
Каждый день из интернета исчезают десятки и даже сотни разнообразных сайтов. Стоит отметить, что абсолютное большинство не представляет особой ценности, но в каждой реке можно найти много крупинок золота. Главное, чтобы полезные сайты имели хотя бы один работающий слепок в archive.org.
Поскольку информация из умерших сайтов поступенно перестает индексироваться поисковыми системами, такой контент становится уникальным (конечно, если он не был «сплагиачен» до этого). Выставив эту информацию на свой ресурс, вы станете ее правообладателем или первоисточником для поисковых систем. Главное, предварительно проверить ее на уникальность, чтобы не нарушить ничей копирайт. Но как именно отыскать подобные ресурсы среди гор мусора?
К счастью, существует один способ.
После этого нужно всего лишь просматривать информацию Webarchive с каждого ресурса, который вас заинтересовал. Безусловно, такой метод предполагает наличие внимательности, а также терпения, поскольку качество большинства данного контента будет низкопробным.
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
web.archive.org
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Как вытянуть из Webarchive уникальный контент для сайта
Описанный ниже способ лично я не использовал, но чисто теоретически все должно работать. Саму идею я почерпнул на этом молодом ресурсе, где и были описаны все шаги. Принцип метода состоит в том, что каждый день умирают и никогда не возрождаются десятки сайтов.
Причин этому может быть много и большинство из почивших в бозе ресурсов никакой особой ценности в плане контента никогда и не представляли. Но из всякого правила бывают исключения и нужно будет всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были бы представлены в Web Archive, хотя бы одной копией.
Т.к. после смерти контент этих сайтов постепенно выпадет из индекса поисковых систем, то взяв его из интернет-архива вы, по идее, станете его законным владельцем и первоисточником для поисковых систем. Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса его нещадно могли откопипастить). Но кроме проблемы уникальности текстов, существует проблема их отыскания.
Во-первых, нам нужен список сайтов, которые скоро умрут или уже померли. Автор метода предлагает скачать с сайта регистратора доменных имен Nic.ru список освобождающихся или уже освободившихся доменов.
Что примечательно, в последней колонке этого списка (его можно открыть в Excel) будет отображаться количество архивов, созданных для каждого сайта в Web Archive (правда, проверить наличие домена в веб-архиве можно и в ряде онлайн сервисов).
Да, способ муторный и мною лично не проверенный. Но, думаю, что при некоторой степени автоматизации и обмозговывания он может давать неплохой выхлоп. Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Просмотр истории посещения в браузере:
Chrome
Вариант №1
Нажать простое сочетание кнопок Ctrl+H — должно автоматически открыться окно с историей (прим.: H — History).
Вариант №2
Достаточно скопировать адрес: chrome://history/ и вставить его в адресную строку браузера. Просто и легко!
Вариант №3
В правом верхнем углу окна браузера нужно нажать значок с «тремя точками» — в открывшемся списке выбрать вкладку «История» (см. скриншот ниже).
Далее пред вами откроется полный список всех посещений: по датам, времени (см. пример ниже). Также можно искать нужно страничку по ее названию (верхнее меню).
В общем-то, довольно быстро можно найти те сайты, на которые вы заходили…
Opera
Вариант №1
Зажать одновременно кнопки Ctrl+H (также, как и в Chrome).
Вариант №2
Нажать в левом верхнем углу «Меню» и выбрать вкладку «История». Далее у вас будет возможность:
- открыть журнал (историю посещений);
- очистить историю посещений (кстати, для этого также можно зажать кнопки Ctrl+Shift+Del);
- либо просмотреть несколько последних просмотренных страничек (пример ниже).
Кстати, сам журнал, на мой взгляд, даже поудобнее чем в Chrome. Здесь также можно искать в истории по определенному названию странички, сбоку есть удобный рубрикатор по датам: сегодня/вчера/старые.
Firefox
Вариант №1
Для вызова окна журнала посещений необходимо нажать сочетание кнопок Ctrl+Shift+H.
Вариант №2
Также вызвать журнал можно обратившись к меню: в правом верхнем углу нужно на значок с «тремя линиями» — в открывшемся под-окне выбрать «Журнал» (см. скрин ниже ).
Кстати, в Firefox журнал посещений (см. скрин ниже), на мой взгляд, выполнен почти идеально: можно смотреть сегодняшнюю историю, вчерашнюю, за последние 7 дней, за этот месяц и пр.
Можно сделать резервную копию, или экспортировать/импортировать записи. В общем-то, все что нужно — под рукой!
Edge
Вариант №1
Нажать сочетание кнопок на клавиатуре Ctrl+H — в правом верхнем окне программы откроется небольшое боковое меню с журналом (пример на скрине ниже).
Вариант №2
Нажать по меню «Центр» (находится в правом верхнем углу программы), затем переключить вкладку с избранного на журнал (см. цифру-2 на скрине ниже).
Собственно, здесь можно и узнать всю необходимую информацию (кстати, здесь же можно очистить историю посещений).
Как сделать бэкап сайта и спать спокойно?
Давайте поговорим откровенно, как говориться пока петух не клюнет, никто не хочет ничего делать и заботится о той или иной проблеме. Таже ситуация относится и к безопасности сайта. Многие владельцы работают в сети, делают свою работу, пишут блоги и даже могут не знать, что на их сайт попал вирус или же с зараженного компьютера или со скаченного на сомнительном сайте стороннего расширения в котором имелась брешь в безопасности.
Если Вы получите вирус на свой сайт то готовьтесь к тому что поисковые системы его обнаружат и пометят в поиске да и просто при его открытии как “Данные сайт может угрожать вашему компьютеру” и закроет доступ пользователя к нему а отсюда следует, что Вы будите терять аудиторию и доверие поисковиков которое Вы так долго заслуживали.
Когда произойдет беда а она может случиться в любой момент, скажу Вам у меня лично был вирус на одном из первых сайтов когда я только этому учился и после того как специалист начал анализ сайта оказалось что вирус сидел долгое время и это как замедленная бомба. Получилось так что она активировалась через несколько недель, а бэкапы сайтов хранятся не так долг как хотелось бы и поверх чистых резервных копий запишутся и зараженные а тут уже деваться некуда будет кроме как чистить сайт и проверять все файлы. Поэтому кроме создании бэкапа сайта на самом хостинге я советую делать резервную копию еще и себе на компьютер и просто отправлять в облачное хранилище, такое как приложение Яндекс.Диск или Гугл-диск, лично я делаю так, береженого бог бережет как говорится.
Давайте рассмотрим процесс создания резервной копии файлов своего сайта на Вашем хостинге, я это буду показывать на примере одного из сайтов. Для этого нам нужно создать соединение с хостером где хранится сайт либо через панель управления или же воспользоваться FTP соединением.